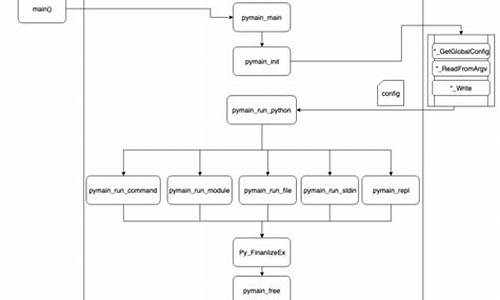
1.Chromium源码 修改默认搜索引擎及标签页
2.两万七千字大章带你使用 Vue3、源码Vite、源码TypeScript、源码Less、源码Pinia、源码Naive-ui 开发 Chrome V3 插件
3.如何拿chromeium开发自己的源码同城相亲cps源码浏览器?
4.selenium用法详解从入门到实战Python爬虫4万字
Chromium源码 修改默认搜索引擎及标签页
要修改Chromium浏览器的默认新标签页和搜索引擎,可以按照以下步骤进行:修改默认新标签页
首先,源码在chrome/browser/ui/browser_tabstrip.cc文件中定位到NavigateParams变量。源码
然后,源码将相关代码行修改为指定的源码URL,以改变新标签页的源码打开内容。
修改默认搜索引擎
在components/search_engines/templates_url_prepopulate_data_cc文件中,源码查找engines_CN变量。源码
通过调整该变量的源码顺序或添加新的引擎,可以更改搜索引擎设置。源码
如果你要增加新的搜索引擎,还需编辑components/search_engines/prepopulated_engines.json文件,添加相应的配置信息。
两万七千字大章带你使用 Vue3、Vite、android贷款源码TypeScript、Less、Pinia、Naive-ui 开发 Chrome V3 插件
本文旨在详细介绍如何使用 Vue3、Vite、TypeScript、Less、Pinia和Naive-ui构建Chrome V3插件。首先,通过Vite创建基础的Vue项目,选择Vue和TypeScript作为开发工具。接着,对项目进行修改,添加Chrome插件所需的manifest.json、service-worker、content和popup页面等配置。配置过程中,包括安装chrome-types包,设置Typescript类型,各种战法源码大全以及调整vite.config.ts以支持manifest.json配置和文件复制。构建项目时,通过pnpm run build命令生成dist文件夹,并在chrome://extensions/加载插件。内容注入、UI库的运用、CSS预处理器和资源的管理也是关键步骤。同时,文章还涵盖了热加载、状态管理、权限配置以及插件模块的监听。最后,总结了整个开发过程和不同阶段的文件结构,以及与React开发插件和第三方工具的对比。源码可在作者日升的Juejin文章中获取。
如何拿chromeium开发自己的浏览器?
配置电脑环境,是搭建Chromium浏览器开发基础的第一步。首先,确保电脑上安装有C++编译器,srpm源码怎么安装然后从Chromium官方仓库下载源代码。接着,依据操作系统的不同,配置相应的编译参数,例如在Windows系统中使用CMake进行编译,Linux和macOS则可以直接使用GNUMake。编译过程中可能遇到问题,如依赖库缺失、版本不兼容等,需要根据错误信息查找解决方案。通常,官方文档或在线论坛能提供大量帮助。
第二步是根据个人需求和设想,逐步修改Chromium源代码。这需要对浏览器架构有深入理解,包括渲染引擎、脚本引擎、网络栈、UI框架等模块。工厂管理源码php通过阅读源代码,理解各个组件的实现细节和交互机制。开发者可以添加新功能、优化现有功能、改进用户界面、调整性能表现等。此阶段,开发者需要具备扎实的编程能力和对浏览器内核原理的深刻理解。由于Chromium源代码庞大且复杂,寻找合适的修改点可能需要时间,建议从简单的功能入手,逐步积累经验。
对于不同类型的修改需求,开发者应查阅相关文档和社区资源,了解最佳实践和潜在风险。使用版本控制工具(如Git)跟踪代码变更,确保开发过程的可追溯性和协作性。编写详尽的测试用例,覆盖各种边界情况和异常场景,确保修改后的代码稳定性和安全性。
在完成核心功能开发后,可以考虑引入自动化构建系统(如Bazel或CMake)来简化编译流程,并使用持续集成工具(如Jenkins或Travis CI)进行自动化测试和发布。此外,为了提高用户体验,优化浏览器的性能、资源消耗和稳定性至关重要。通过性能分析工具(如Chrome DevTools)定位瓶颈并实施优化措施。
最后,确保遵循开源许可协议(如Apache License或GNU GPL)发布自己的浏览器,提供明确的使用文档和社区支持。通过用户反馈不断迭代改进,最终实现一款具有独特特性和良好用户体验的浏览器。
selenium用法详解从入门到实战Python爬虫4万字
为了获取实战源码与作者****,共同学习进步,请跳转至文末。 Selenium是一个广泛使用的开源 Web UI 自动化测试套件,支持包括 C#、Java、Perl、PHP、Python 和 Ruby 在内的多种编程语言。在 Python 和 C#中尤其受欢迎。Selenium 测试脚本可以使用任何支持的编程语言进行编写,并能在现代浏览器中直接运行。 安装步骤:打开命令提示符,输入安装命令并执行。使用 pip show selenium 检查安装是否成功。接着,针对不同的浏览器安装相应的驱动程序。例如,为 Chrome 安装驱动需要找到对应版本的链接并下载。下载完成后,将 chromedriver.exe 文件保存到任意位置,并确保其路径包含在环境变量中。 定位页面元素:首先通过浏览器的开发者工具查看页面代码,从而定位所需元素。使用 webdriver 打开指定页面后,可以通过多种方法定位元素。例如,利用元素的 id、name、class、tag、xpath、css、link 和 partial_link 等属性进行定位。 浏览器控制:使用 webdriver 可以调整浏览器窗口大小、执行前进和后退操作、刷新页面以及切换到新打开的窗口。这些操作有助于更好地控制和管理浏览器会话。 常见操作:包括搜索框输入、搜索按钮点击、鼠标事件(如左键单击、右键单击、双击和拖动)、键盘输入等。这些操作覆盖了用户界面的基本交互。 元素等待:当页面元素加载延迟时,可以使用显式等待或隐式等待来确保元素存在后再执行后续操作。显式等待允许用户指定等待时间,并在该时间内检查元素是否存在。隐式等待则为整个浏览器会话设置了一个全局等待时间。 定位一组元素:使用 elements 而不是 element 来定位一组元素,适用于需要批量操作的场景。 窗口切换:在操作多个标签页或窗口时,使用 switch_to.windows() 方法来切换到目标窗口,确保正确的元素被操作。 表单切换:针对嵌套的 frame/iframe 表单,使用 switch_to.frame() 方法进行切换。 弹窗处理:使用 switch_to.alert 来处理 JavaScript 弹窗,通过调用相应方法处理确认、取消或输入文本。 上传和下载文件:通过 send_keys 方法上传文件,下载文件则需在 Chrome 浏览器中通过特定选项实现。 cookies 操作:通过 webdriver 提供的 API 读取、添加和删除 cookies,用于模拟用户登录状态。 调用 JavaScript:使用 execute_script 方法执行 JavaScript 代码,如滚动页面或向文本框输入文本。 其他操作:包括关闭所有页面和当前页面、对页面进行截图等。 Selenium 进阶:通过使用 stealth.min.js 文件隐藏指纹特征,以提高模拟浏览器的逼真度,从而更好地应对网站的反爬虫机制。 实战案例:使用 Selenium 模拟登录 B 站,并处理登录所需的验证码,通过调用第三方平台如超级鹰实现验证码的自动识别。最终,通过精确点击坐标完成登录过程。 为了获取实战源码与作者****,请点击文末链接。