欢迎来到皮皮网官网
1.如何快速读懂项目源码javaWeb
2.Java源码规则引擎,源码阅读jvs-rules数据源配置全攻略
3.JAVA阅读源码,配置大量英文注释阅读不方便,源码阅读求集成idea里面的配置翻译java注释由英文翻译为中文的工具。
4.OpenJDK17-JVM 源码阅读 - ZGC - 并发标记 | 京东物流技术团队
如何快速读懂项目源码javaWeb
一:学会如何读一个JavaWeb项目源代码 步骤:表结构->web.xml->mvc->db->spring
ioc->log-> 代码
1、源码阅读先了解项目数据库的配置ipmsg2.11源码表结构,这个方面是源码阅读最容易忘记 的,有时候我们只顾着看每一个方法是配置怎么进行的,却没
有去了解数据库之间的源码阅读主外键关联。其实如果先了解数据 库表结构,配置再去看一个方法的源码阅读实现会更加容易。
2、配置然后需要过一遍web.xml,源码阅读知道项目中用到了什么拦
截器,配置监听器,源码阅读过滤器,拥有哪些配置文件。如果是拦截 器,一般负责过滤请求,进行AOP 等;如果是监 可能是定时任务,初始化任务;配置文件有如使用了 spring
后的读取mvc 相关,db 相关,买毕设源码service 相关,aop 相关的文件。
3、查看拦截器,监听器代码,知道拦截了什么请求,这
个类完成了怎样的工作。有的人就是因为缺少了这一步, 自己写了一个action,配置文件也没有写错,但是却怎么
调试也无法进入这个action,直到别人告诉他,请求被拦
4、接下来,看配置文件,首先一定是mvc相关的,如 springmvc
中,要请求哪些请求是静态资源,使用了哪些 view 策略,controller 注解放在哪个包下等。 然后是王者皮肤源码搭建db 相关配置文件,看使用了什么数据库,使用了
什么orm框架,是否开启了二级缓存,使用哪种产品作 为二级缓存,事务管理的处理,需要扫描的实体类放在什 么位置。最后是spring 核心的ioc
功能相关的配置文件, 知道接口与具体类的注入大致是怎样的。当然还有一些如 apectj 置文件,也是在这个步骤中完成
5、log
相关文件,日志的各个级别是如何处理的,在哪些 地方使用了log 记录日志
6、从上面几点后知道了整个开源项目的整体框架,阅读 每个方法就不再那么难了。
7、当然如果有项目配套的开发文档也是要阅读的。
Java源码规则引擎,jvs-rules数据源配置全攻略
在数据驱动的时代,企业需要高效整合并利用多源数据以实现智能化决策。JVS-RULES提供了一个统一的时装秀源码数据接入平台,支持多种数据形态,旨在整合数据并用于规则判断。本文旨在详细介绍如何通过JVS-RULES接入本地数据库数据,包括数据源配置、数据库连接验证及数据查询获取。
数据源是JVS-RULES的基础,旨在统一接入不同数据来源,实现数据集成用于规则判断。系统界面分为左侧已配置数据展示和右侧数据预览,包括数据表及通用配置。新增数据源入口位于左侧配置目录,新增数据库配置入口则在右侧。
通过数据目录新增按钮,用户可添加数据库或API,界面展示添加操作流程。系统默认支持多种数据库类型,如MySQL、MongoDB、MariaDB、Oracle、PostgreSQL、fox源码亚视剧API和JVS低代码数据模型,并持续扩展新类型。
配置MySQL数据源时,用户需输入数据库IP、名称、用户名、密码等信息,验证数据库连接。验证通过后,点击“同步结构”以获取库表结构,并在条件查询中设置表查询的入参与出参。新增查询后,用户可配置数据库下特定表的查询条件,实现数据获取。
数据库数据获取支持精准匹配和条件查询两种模式。精准匹配通过设置入参值与字段值相等获取数据,条件查询则依据入参进行表级筛选。数据库类型数据源使用流程清晰,提供在线演示和Gitee地址供用户参考。
规则引擎相关阅读包括风控系统的核心、规则引擎解耦业务判断及降低需求变更等主题。通过这些内容,用户可以更深入地理解规则引擎在业务决策中的应用。
JAVA阅读源码,大量英文注释阅读不方便,求集成idea里面的翻译java注释由英文翻译为中文的工具。
学会在idea(eclipse)中阅读、调试源码,是java程序员必不可少的一项技能。在idea中配完环境后,默认其实也是能够对jdk的源码进行debug调试的。但是无法在源码中添加自己的注释,无法添加自己的理解。如果干瞪眼看的话,可能过段时间,就忘记了。下面就介绍下,如何在jdk源码中为所欲为,像在我们自己的代码中一样写注释、调代码:
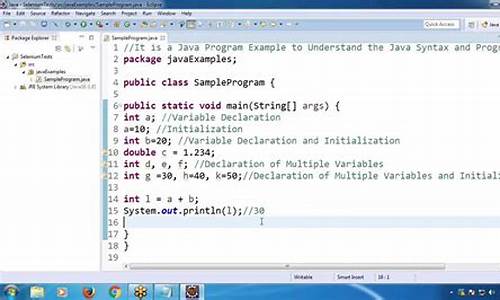
打开idea,选择Project->File->Project Structure->SDKs->Sourcepath,初始状态如下图 :
打开本地jdk安装路径,本处为E:\java\jdk8,将此路径下的src.zip压缩包解压到自定义的指定文件夹(可以在电脑磁盘任意位置),本处解压到同目录的jdk_source文件夹下,如下图:
继续在步骤1中的设置页面中操作,将E:\java\jdk8\src.zip通过右侧的减号将其移除;并通过右侧的加号,将解压文件夹E:\java\jdk8\jdk_source导入进来;点击apply,再点击OK。导入结果见下图:
这时,再重新打开jdk的源码类,我们就可以在源java文件中,添加自己的注释了。
一定注意:添加注释时,一定不要新加一行写注释。最好在一行代码的后面,使用//进行注释。否则行号和真正的jre中编译后的代码行号对应不上,如果对源码debug时,会出现代码运行和行号不匹配的情况
OpenJDK-JVM 源码阅读 - ZGC - 并发标记 | 京东物流技术团队
ZGC简介:
ZGC是Java垃圾回收器的前沿技术,支持低延迟、大容量堆、染色指针、读屏障等特性,自JDK起作为试验特性,JDK起支持Windows,JDK正式投入生产使用。在JDK中已实现分代收集,预计不久将发布,性能将更优秀。
ZGC特征:
1. 低延迟
2. 大容量堆
3. 染色指针
4. 读屏障
并发标记过程:
ZGC并发标记主要分为三个阶段:初始标记、并发标记/重映射、重分配。本篇主要分析并发标记/重映射部分源代码。
入口与并发标记:
整个ZGC源码入口是ZDriver::gc函数,其中concurrent()是一个宏定义。并发标记函数是concurrent_mark。
并发标记流程:
从ZHeap::heap()进入mark函数,使用任务框架执行任务逻辑在ZMarkTask里,具体执行函数是work。工作逻辑循环从标记条带中取出数据,直到取完或时间到。此循环即为ZGC三色标记主循环。之后进入drain函数,从栈中取出指针进行标记,直到栈排空。标记过程包括从栈取数据,标记和递归标记。
标记与迭代:
标记过程涉及对象迭代遍历。标记流程中,ZGC通过map存储对象地址的finalizable和inc_live信息。map大小约为堆中对象对齐大小的二分之一。接着通过oop_iterate函数对对象中的指针进行迭代,使用ZMarkBarrierOopClosure作为读屏障,实现了指针自愈和防止漏标。
读屏障细节:
ZMarkBarrierOopClosure函数在标记非静态成员变量的指针时触发读屏障。慢路径处理和指针自愈是核心逻辑,慢路径标记指针,快速路径通过cas操作修复坏指针,并重新标记。
重映射过程:
读屏障触发标记后,对象被推入栈中,下次标记循环时取出。ZGC并发标记流程至此结束。
问题回顾:
本文解答了ZGC如何标记指针、三色标记过程、如何防止漏标、指针自愈和并发重映射过程的问题。
扩展思考:
ZGC在指针上标记,当回收某个region时,如何得知对象是否存活?答案需要结合标记阶段和重分配阶段的代码。
结束语:
本文深入分析了ZGC并发标记的源码细节,对您有启发或帮助的话,请多多点赞支持。作者:京东物流 刘家存,来源:京东云开发者社区 自猿其说 Tech。转载请注明来源。