

1.JIT、编译器和解释器
2.前端开发Lua篇——LuaJIT
3.LuaJIT源码分析(二)数据类型
4.LuaJIT源码分析(一)搭建调试环境
5.Windows ä¸ç¼è¯ LuaJIT
6.C#JIT的概念及作用
JIT、编译器和解释器
在深入理解编程语言的结构之前,我们常会遇到JIT、编译器和解释器这些概念,尽管它们在不同语言中扮演着重要角色,趋势通道公式源码但可能容易引发混淆。有人错误地认为每种语言要么只有编译器,要么只有解释器,其实不然。
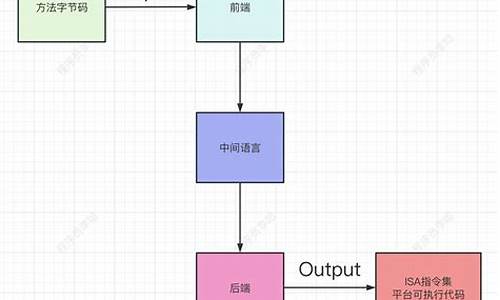
JIT,即即时编译,它就像一个魔法,当源代码或中间代码(如JavaScript文件、Java的class文件)被解释器加载后,它会立即转化为计算机可以直接理解和执行的机器码形式,提高了运行效率。
编译器则是个转换工具,它的任务是将一种编程语言(如C或Java)转换成另一种更低级的、计算机可以直接理解的语言,这种转换过程是预先进行的,以备后续执行。
相比之下,解释器则负责实时执行源代码。它不需要预先转换,而是直接读取并解析源码,然后逐行执行。例如,JavaScript的运行就是通过解释器实现的。
实际上,如何分析wordpress源码编译器和解释器并非互斥的存在,许多语言(如Go、Cpython、Lua)都采用了混合模式,既具备编译优化的效率,也支持解释执行的灵活性。以C语言为例,虽然我们通常称其为编译型语言,但理论上,也可以为其编写解释器,以实现即时执行。
前端开发Lua篇——LuaJIT
三十六计手游采用LuaJIT实现游戏逻辑,但在特定场景下禁用了JIT模式。具体操作步骤如下:
1. 首先,从LuaJIT官网获取与cocos2dx引擎版本一致的库文件。例如,针对cocos2dx版本号3.,需确保lua和jit的版本信息与库文件相匹配,避免因版本不一致而导致"cannot load incompatible bytecode"错误。
2. 利用命令行工具进行编译。在mac操作系统中,直接执行"make"即可完成编译;对于win用户,需先配置VSCommandPrompt,执行参数为"/k \"C:\\Program Files (x)\\Microsoft Visual Studio .0\\Common7\\Tools\\VsDevCmd.bat\"",然后进入jit源代码目录并运行"msvcbuild.bat"进行编译。
3. 使用"luajit -b"命令生成bytecode,此步骤生成的bytecode在runtime中通过interpreter模式运行。值得注意的是,jit bytecode生成后,免费下载源码博客行号钩子失效,可能影响基于行号的debug或profile操作,需要进行相应的调整。
考虑到不同平台对JIT模式的处理,ios系统默认关闭JIT,而android则需通过"jit.off()"进行手动关闭。在游戏开发中,对JIT模式的使用需谨慎考虑,以避免可能的性能损耗。
在禁用JIT模式后,游戏开发者可能会考虑使用luac而非jit的bytecode。然而,针对iOS禁用JIT、Android主动关闭JIT,以及可能面临其他平台不稳定情况,仍选择使用jit的bytecode具有以下优势:
1. 减少体积,提高包体、内存、转化率和热更文件大小的效率。相较于luac,jit的bytecode体积减少了约%。
2. 加速require代码时的load过程,性能提升达倍。在禁用JIT的环境下,性能特性与luac保持一致,无需对代码进行额外优化。
LuaJIT源码分析(二)数据类型
LuaJIT,作为Lua的高性能版本,其源码分析中关于数据类型处理的青岛溯源码燕窝细节颇值得研究。它在数据结构的定义上与Lua 5.1稍有不同,通过通用的数据结构TValue来表示各种Lua数据类型,但其复杂性体现在了内含的若干宏上,增加了理解的难度。这些宏如LJ_ALIGN、LJ_GC、LJ_ENDIAN_LOHI、LJ_FR2等,分别用于内存对齐、GC模式的选择、大小端判断以及浮点数编码格式的选择。
LJ_ALIGN宏用于确保struct内存对齐,以提高内存访问效率。LJ_GC宏在当前平台为位且无强制禁用的情况下生效,表明LuaJIT支持位GC(垃圾回收)模式。LJ_ENDIAN_LOHI宏则根据平台的字节顺序来确定结构的布局,而x平台采用小端序。
对于TValue结构的定义,通过处理宏后可以简化为一个位的结构体,包含一个union,用于统一表示Lua的各种数据类型。这种设计利用了NaN Boxing技术,即通过在浮点数编码中预留空间来实现不同类型数据的紧凑存储。每个类型通过4位的itype指针来标识,使得数据的解析与存储变得高效。
对于number数据类型,其值被存储在一个double中,而其他类型如nil、true、网站源码 是什么false等则利用剩余的空间来标识其类型。这种设计允许LuaJIT在内存中以一种紧凑且高效的方式存储各种数据类型,同时通过简单的位操作就能识别出具体的数据类型。
对于GC对象(如string、table等),LuaJIT通过特定的itype值来区分它们与普通数据类型,以及与值类型(如nil和bool)和轻量级用户数据的差异。通过宏判断,LuaJIT能够快速识别出TValue是否为GC对象,以及具体是哪种类型的GC对象。
在开启LJ_GC模式下,GC对象的地址被存储在TValue的特定字段gcr中,提供位的地址支持。虽然前位用于标识数据类型,但实际使用时仅利用了低位的地址空间,对于大多数实际应用而言,这部分内存已经绰绰有余。
在GCobj数据结构中,通过union的特性实现不同类型对象的共通性与特定性。GChead提供了通用的接口来获取对象的通用信息,而nextgc、marked等字段用于实现垃圾回收机制。通过gct字段,LuaJIT能够将一个GCObj转换为实际的类型对象,进一步增强了内存管理的灵活性。
对于整数类型,默认情况下LuaJIT使用double进行存储以确保精度,但在实际应用中,频繁使用的整数通过宏LJ_DUALNUM启用,以int类型存储,提高了数据处理的效率。此时,TValue的i字段用于保存int值,同时通过位移操作确保了数据的正确存储与解析。
LuaJIT源码分析(一)搭建调试环境
LuaJIT,这个以高效著称的lua即时编译器(JIT),因其源码资料稀缺,促使我们不得不自建环境进行深入学习。分析源码的第一步,就是搭建一个可用于调试的环境,但即使是这个初始步骤,能找到的指导也相当有限,反映出LuaJIT的编译过程复杂性。
首先,从官方git仓库开始,通过命令`git clone https://luajit.org/git/luajit.git`获取源代码。GitHub上也有相应的镜像地址。对于调试,LuaJIT提供msvcbuild.bat脚本,位于src目录下,它将编译过程分为三个阶段:构建minilua,用于平台判断和执行lua脚本;buildvm生成库函数映射;以及lua库的编译和最终LuaJIT的生成。该脚本需在Visual Studio Command Prompt环境中以管理员权限运行,且有四个可选编译参数。
在调试时,我们无需这些选项,但需要保留中间代码。因此,需要在脚本中注释掉清理代码的部分。在Visual Studio 的位命令提示符中,切换到src目录并运行`msvcbuild.bat`。编译过程快速,成功时会看到日志信息。在src目录下,luajit.exe即为lua虚拟机。
接着,在src目录的同级目录创建一个VS工程,将源文件和头文件添加进来。初次尝试调试可能会遇到关于strerror函数安全性的警告,这可以通过在工程属性中添加_CRT_SECURE_NO_WARNINGS宏来解决。然而,链接阶段可能会出现重复定义的错误,这与ljamalg.c文件的编译选项有关。amalg选项用于生成单个大文件,以优化代码,但我们通常不启用它。
排除ljamalg.c后,再次尝试调试,可能还需要手动添加buildvm阶段生成的目标文件。当LuaJIT启动并设置好断点后,就可以开始调试源码了。至此,你已经成功搭建了一个LuaJIT的调试环境,为深入理解其工作原理铺平了道路。
Windows ä¸ç¼è¯ LuaJIT
è¿éä½¿ç¨ Visual studio èªå¸¦çå½ä»¤è¡å·¥å ·æ¥è¿è¡ç¼è¯ï¼æ以éè¦å®è£ 好VSã
é¦å æå¼VSå½ä»¤è¡å·¥å ·ãå¯ä»¥æ Win + S ï¼è¾å ¥ prompt æ¥æ¾å°å®ãå¦å¾ã
解å LuaJIT æºç ï¼å¹¶è¿å ¥å°è§£åç®å½ /src ä¸ãè¾å ¥ msvcbuild å¼å§ç¼è¯ã
çå° === Successfully built LuaJIT for xxxxx === åæ¯ç¼è¯æåäºã
å¨è§£åç®å½ /src ä¸å¯ä»¥æ¾å°ç¼è¯çæç luajit.exe å lua.dll .
æå¼cmdã
å¦æ没ææ·»å ç¯å¢åéåå å®ä½å°LuaJitå®è£ ç®å½ã
è¾å ¥ luajit +æ件å å³å¯è¿è¡Luaèæ¬ã
è¾å ¥ luajit -b +Luaèæ¬+ç®æ æ件åï¼å³å¯ç¼è¯èæ¬ã
C#JIT的概念及作用
C#编写的程序,经过编译器把编译后,源代码被转换成Microsoft中间语言(MSIL)。MSIL不是真正可执行的代码。因此,要真正执行MSIL应用程序,还必须使用“JIT编译器”,对MSIL再次编译,以得到主机处理器可以真正执行本机指令。JIT编译器以即时方式编译MSMIL代码,以便应用程序执行。
java的javac编译器和jit编译器是什么关系,jit阶段是运行期
在之前的文章中我们探讨过,相较于C/C++语言,Java语言在运行效率方面可能稍显逊色,因为Java应用程序运行在虚拟机上,而C/C++程序直接编译成对应平台的机器码执行。虚拟机团队持续努力缩小Java与C/C++语言在性能上的差距,确实取得了显著成果。
本文将聚焦于HotSpot虚拟机如何通过提升Java程序执行效率实现技术优化。JIT编译器是JVM的重要组成部分,与常用于生成Java字节码的javac编译器不同,JIT编译器是提升Java程序执行效率的核心工具。
面试官经常提出Java程序是解释执行还是编译执行的问题。初学者可能认为Java是编译执行,执行流程类似先将源码编译成.class字节码,然后通过java命令在虚拟机中利用解释器执行代码。解释器的作用是将字节码操作指令与平台体系指令建立映射,如将Java的load指令转换为native code的load指令。
实际上,Java程序既有解释执行,也有编译执行。准确的执行流程可以描述为:源码程序.java文件通过javac命令编译成字节码,然后在虚拟机中解释执行。JIT编译器的作用是在运行时将热点代码编译成本地平台相关的机器码,并进行优化,以提升程序执行效率。
JIT编译器的引入显著解决了虚拟机边运行边解释的低性能问题。但引入JIT编译器是否意味着可以直接采用它执行程序?答案并非如此。解释器和编译器各有优势,因此Java程序既有解释执行也有编译执行。
HotSpot虚拟机内置了两款即时编译器:Client Compiler和Server Compiler,分别被称为C1和C2编译器。Client Compiler编译速度较慢,但编译速度快于传统静态优化编译器,输出的本地代码执行时间减少,因此适合非服务端应用。Server Compiler编译器输出代码质量较高,编译速度远超C1编译器。
JIT编译器会将热点代码编译成本地平台相关的机器码。热点代码主要来自方法被调用次数多和循环体内代码执行多次的情况。HotSpot虚拟机使用计数器进行热点探测,包括方法调用计数器和回边计数器,用于判断代码是否为热点代码。
方法调用计数器统计方法被调用的次数,回边计数器统计循环体代码执行次数。计数器超过预设阈值时,编译器将方法作为编译对象进行编译。方法调用计数器和回边计数器的阈值默认设置为客户端模式下次和服务器模式下次,用户可通过参数调整。
运行期优化技术包括:方法内联、冗余访问消除、复写传播、无用代码消除、公共子表达式消除、数组边界检查消除、逃逸分析等。其中,公共子表达式消除和数组边界检查消除是典型的优化手段。
方法内联优化减少方法调用成本,进行内联后,方法代码被直接复制到调用者位置,提高了优化空间。数组边界检查消除优化通过分析数据流,避免不必要的边界检查,提升了执行效率。
逃逸分析技术用于分析对象动态作用域,判断对象是否逃逸到方法或线程之外。如果对象不会逃逸,可以进行栈上分配、同步消除或标量替换等优化,提升程序性能。
本文整合和总结了JVM在运行期对代码的优化手段,旨在帮助读者理解这些技术。内容较多,如有描述不当之处,欢迎指正。




