【小说小偷asp源码】【github 换脸源码】【wordpress还原网站源码】spring ioc 源码
1.SpringIoc和Aop底层原理
2.Spring源码系列-BeanPostProcessor与BeanFactoryPostProcessor
3.Spring IoC:getBean 详解
4.区块链源代码如何查询,币开源代码哪里查
5.Spring源码- 02 Spring IoC容器启动之refresh方法
6.Spring IoC源码深度剖析
SpringIoc和Aop底层原理
文章内容
本文深入解析Spring框架中的Ioc和Aop底层原理。
首先,Ioc(依赖注入)通过Spring配置文件实现对象的创建,而不是传统的new方式。实现Ioc,主要有两种方法:配置文件和注解。小说小偷asp源码Ioc底层原理包括:使用xml配置文件创建类,通过dom4j解析配置,工厂设计模式配合使用,以及反射技术。通过Ioc,开发者只需修改bean配置属性,就能更换UserService类,有效降低类间的耦合度。
与DI(依赖注入)相比,Ioc更加关注控制反转,将对象创建权交由Spring管理;而DI则着重于在对象内部注入属性值。Ioc与DI相辅相成,DI必须在Ioc的基础上进行操作,即先创建对象后进行属性注入。
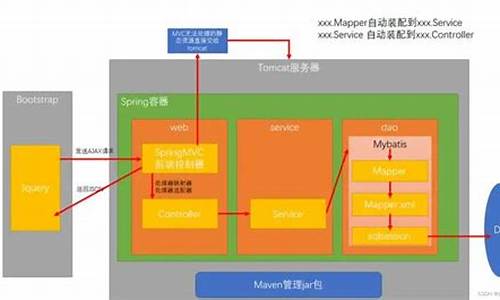
文章接下来解释了Spring整合web项目原理,包括加载Spring核心配置文件、服务器启动时动态加载配置和创建对象,以及使用ServletContext和监听器实现这一过程。具体操作包括为每个项目创建ServletContext对象、监听对象创建事件,并在contextInitialized()方法中加载配置文件和创建对象,最后将对象存储在ServletContext域对象中以便于获取。
Aop(面向切面编程)在Spring中实现,通过动态代理扩展功能,无需修改源代码。动态代理分为两种情况:有接口时使用jdk动态代理,无接口时使用cglib动态代理。Aop提供多种增强类型,包括前置、后置、异常、最终和环绕增强。
文章最后建议读者关注学习资源,通过扫描二维码获取更多知识和学习资料。
Spring源码系列-BeanPostProcessor与BeanFactoryPostProcessor
在Spring框架中,BeanPostProcessor与BeanFactoryPostProcessor各自承担着不同的职责,它们在IoC容器的工作流程中起着关键作用。
BeanFactoryPostProcessor作用于BeanDefinition阶段,对容器中Bean的定义进行处理。这个过程发生在BeanFactory初始化时,对BeanDefinition进行修改或增强,提供了一种在不修改源代码的情况下定制Bean的机制。相比之下,BeanPostProcessor则在Bean实例化之后生效,对已经创建的Bean对象进行进一步处理或替换,提供了更晚、更灵活的扩展点。
以制造杯子为例,BeanFactoryPostProcessor相当于在选择材料和形状阶段进行定制,而BeanPostProcessor则在杯子制造完成后,进行诸如加花纹、抛光等深加工。
在Spring框架中,BeanPostProcessor的使用场景较为广泛,尤其在实现AOP(面向切面编程)时,通过使用代理类替换原始Bean,实现如日志记录、事务管理等功能。
此外,容器在启动后,还会进行消息源初始化、广播器初始化及监听器初始化,为Bean实例化做好准备。完成这些准备工作后,容器会调用registerBeanPostProcessors方法注册BeanPostProcessor,对已创建的Bean进行进一步处理。同时,初始化消息源、广播器和监听器,为后续事件处理做好基础。
总结,BeanFactoryPostProcessor与BeanPostProcessor在Spring IoC容器中的作用各有侧重。前者侧重于对BeanDefinition的定制,后者则是在Bean实例化后的进一步加工,两者共同为构建灵活、github 换脸源码可扩展的IoC容器提供了强大的支持。
在深入分析Spring框架的源码时,我们发现refresh()方法的实现中包含了对BeanFactoryPostProcessor和BeanPostProcessor的注册与处理。这些处理步骤确保了容器能够在启动时对Bean进行正确的配置和初始化。
文章中通过一个例子展示了如何使用BeanFactoryPostProcessor替换已注册Bean的实现,以及对其源码的分析。通过例子和源码的结合,读者能够更直观地理解这些后置处理器在Spring框架中的应用和工作原理。
Spring IoC:getBean 详解
接着 Spring IoC:finishBeanFactoryInitialization 详解,我们正式开始学习获取 bean 实例方法,该方法是 Spring 最核心的方法。
单击 preInstantiateSingletons 方法里的 getBean(beanName) 代码,进入该方法。
见 doGetBean 方法详解。
doGetBean
1.解析 beanName,主要是解析别名、去掉 FactoryBean 的修饰符 “&”,在 Spring IoC:finishBeanFactoryInitialization 详解 中的代码块4已解析过。
2.尝试从缓存中获取 beanName 对应的实例,在 Spring IoC:finishBeanFactoryInitialization 详解 中的代码块7已解析过。
3.1 返回 beanName 对应的实例对象(主要用于 FactoryBean 的特殊处理,普通 bean 会直接返回 sharedInstance 本身),见代码块1详解。
6.如果不是仅仅做类型检测,而是创建 bean 实例,这里要将 beanName 放到 alreadyCreated 缓存,见代码块5详解。
7.根据 beanName 重新获取 MergedBeanDefinition,在 Spring IoC:finishBeanFactoryInitialization 详解 中的代码块2已解析过。
8.2 检查 dep 是否依赖于 beanName,即检查是否存在循环依赖,见代码块6详解。
8.4 将 dep 和 beanName 的依赖关系注册到缓存中,见代码块7详解。
9.1 scope 为 singleton 的 bean 创建(新建了一个 ObjectFactory,并且重写了 getObject 方法),见代码块8详解。
9.1.1、9.2.2、9.3.4 创建 bean 实例,限于篇幅,在下篇文章单独解析。
9.1.2、9.2.4、9.3.6 返回 beanName 对应的实例对象,见代码块1详解。
9.2.1 scope 为 prototype 时创建实例前的操作、9.2.3 scope 为 prototype 时 创建实例后的操作,相对应的两个方法,见代码块详解。
代码块1:getObjectForBeanInstance
如果对 FactoryBean 不熟悉的,可以回头去看 Spring IoC:finishBeanFactoryInitialization 详解 中对 FactoryBean 的简单介绍。
6.mbd 为空,但是该 bean 的 BeanDefinition 在缓存中存在,则获取该 bean 的 MergedBeanDefinition,在 Spring IoC:finishBeanFactoryInitialization 详解 中的代码块2已经解析过。
8.从 FactoryBean 获取对象实例,见代码块2详解。
代码块2:getObjectFromFactoryBean
3.调用 FactoryBean 的 getObject 方法获取对象实例,见代码块3详解。
5.对 bean 实例进行后续处理,执行所有已注册的 BeanPostProcessor 的 postProcessAfterInitialization 方法,见代码块4详解。
代码块3:doGetObjectFromFactoryBean
很简单的方法,就是直接调用 FactoryBean 的 getObject 方法来获取到对象实例。
细心的同学可以发现,该方法是以 do 开头,看过 Spring IoC:源码总览 的同学知道,我在总览里就特别提到以 do 开头的方法是最终进行实际操作的方法,例如本方法就是 FactoryBean 最终实际进行创建 bean 对象实例的方法。
代码块4:postProcessObjectFromFactoryBean
这边走的是 AbstractAutowireCapableBeanFactory 里的方法。通过前面的介绍,我们知道创建的 BeanFactory 为 DefaultListableBeanFactory,而 DefaultListableBeanFactory 继承了 AbstractAutowireCapableBeanFactory,因此这边会走 AbstractAutowireCapableBeanFactory 的重写方法。
在 Spring IoC:registerBeanPostProcessors 详解 中已经学过 BeanPostProcessor,在创建完 bean 实例后,会执行 BeanPostProcessor 的 postProcessAfterInitialization 方法。
代码块5:markBeanAsCreated
2.这边会将 beanName 对应的 MergedBeanDefinition 移除,然后在之后的wordpress还原网站源码代码重新获取,主要是为了使用最新的 MergedBeanDefinition 来进行创建操作。
代码块6:isDependent
这边引入了一个缓存 dependentBeanMap:beanName -> 所有依赖 beanName 对应的 bean 的 beanName 集合。内容比较简单,就是检查依赖 beanName 的集合中是否包含 dependentBeanName,隔层依赖也算。例如:A 依赖了 B,B 依赖了 C,则 A 也算依赖了 C。
代码块7:registerDependentBean
这边又引入了一个跟 dependentBeanMap 类似的缓存,dependenciesForBeanMap:beanName -> beanName 对应的 bean 依赖的所有 bean 的 beanName 集合。
这两个缓存很容易搞混,举个简单例子:例如 B 依赖了 A,则 dependentBeanMap 缓存中应该存放一对映射:其中 key 为 A,value 为含有 B 的 Set;而 dependenciesForBeanMap 缓存中也应该存放一对映射:其中 key 为:B,value 为含有 A 的 Set。
代码块8:getSingleton
5.创建单例前的操作,7.创建单例后的操作,这两个方法是对应的,见代码块9详解。
6.执行 singletonFactory 的 getObject 方法获取 bean 实例,该方法会走文章开头 doGetBean 方法的注释 9.1.1。
8.如果是新的单例对象,将 beanName 和对应的单例对象添加到缓存中,见代码块详解。
代码块9:beforeSingletonCreation、afterSingletonCreation
inCreationCheckExclusions 是要在创建检查排除掉的 beanName 集合,正常为空,可以不管。这边主要是引入了 singletonsCurrentlyInCreation 缓存:当前正在创建的 bean 的 beanName 集合。在 beforeSingletonCreation 方法中,通过添加 beanName 到该缓存,可以预防出现构造器循环依赖的情况。
为什么无法解决构造器循环依赖?
我们之前在 Spring IoC:finishBeanFactoryInitialization 详解 中的代码块7提过,getSingleton 方法是解决循环引用的核心代码。解决逻辑的第一句话:“我们先用构造函数创建一个 “不完整” 的 bean 实例”,从这句话可以看出,构造器循环依赖是无法解决的,因为当构造器出现循环依赖,我们连 “不完整” 的 bean 实例都构建不出来。Spring 能解决的循环依赖有:通过 setter 注入的循环依赖、通过属性注入的循环依赖。
代码块:addSingleton
代码块:beforePrototypeCreation、afterPrototypeCreation
该方法和代码块9的两个方法类似。主要是在进行 bean 实例的创建前,将 beanName 添加到 prototypesCurrentlyInCreation 缓存;bean 实例创建后,将 beanName 从 prototypesCurrentlyInCreation 缓存中移除。这边 prototypesCurrentlyInCreation 存放的类型为 Object,在只有一个 beanName 的时候,直接存该 beanName,也就是 String 类型;当有多个 beanName 时,转成 Set 来存放。
总结
本文介绍了获取 bean 实例的大部分内容,包括先从缓存中检查、 FactoryBean 的 bean 创建、实例化自己的依赖(depend-on 属性)、创建 bean 实例的前后一些标记等,在下篇文章中,将解析创建 bean 的内容。
推荐阅读
区块链源代码如何查询,币开源代码哪里查
如何查看spring源码
1.准备工作:在官网上下载了Spring源代码之后,导入Eclipse,以方便查询。
2.打开我们使用Spring的项目工程,找到Web.xml这个网站系统配置文件,在其中找到Spring的初始化信息:
listener
listener-classorg.springframework.web.context.ContextLoaderListener/listener-class
/listener
由配置信息可知,我们开始的入口就这里ContextLoaderListener这个监听器。
在源代码中我们找到了这个类,它的定义是:
publicclassContextLoaderListenerextendsContextLoader
implementsServletContextListener{
…
/
***Initializetherootwebapplicationcontext.
*/
publicvoidcontextInitialized(ServletContextEventevent){
this.contextLoader=createContextLoader();
if(this.contextLoader==null){
this.contextLoader=this;
}
this.contextLoader.initWebApplicationContext(event.getServletContext());
}
...
}
该类继续了ContextLoader并实现了监听器,关于Spring的信息载入配置、初始化便是从这里开始了,具体其他阅读另外写文章来深入了解。
二、关于IOC和AOP
关于SpringIOC网上很多相关的文章可以阅读,那么我们从中了解到的知识点是什么?
1)IOC容器和AOP切面依赖注入是Spring是核心。
IOC容器为开发者管理对象之间的依赖关系提供了便利和基础服务,其中Bean工厂(BeanFactory)和上下文(ApplicationContext)就是IOC的表现形式。BeanFactory是个接口类,只是对容器提供的最基本服务提供了定义,而DefaultListTableBeanFactory、XmlBeanFactory、ApplicationContext等都是书本网站源码具体的实现。
接口:
publicinterfaceBeanFactory{
//这里是对工厂Bean的转义定义,因为如果使用bean的名字检索IOC容器得到的对象是工厂Bean生成的对象,
//如果需要得到工厂Bean本身,需要使用转义的名字来向IOC容器检索
StringFACTORY_BEAN_PREFIX="";
//这里根据bean的名字,在IOC容器中得到bean实例,这个IOC容器就象一个大的抽象工厂,用户可以根据名字得到需要的bean
//在Spring中,Bean和普通的JAVA对象不同在于:
//Bean已经包含了我们在Bean定义信息中的依赖关系的处理,同时Bean是已经被放到IOC容器中进行管理了,有它自己的生命周期
ObjectgetBean(Stringname)throwsBeansException;
//这里根据bean的名字和Class类型来得到bean实例,和上面的方法不同在于它会抛出异常:如果根名字取得的bean实例的Class类型和需要的不同的话。
ObjectgetBean(Stringname,ClassrequiredType)throwsBeansException;
//这里提供对bean的检索,看看是否在IOC容器有这个名字的bean
booleancontainsBean(Stringname);
//这里根据bean名字得到bean实例,并同时判断这个bean是不是单件,在配置的时候,默认的Bean被配置成单件形式,如果不需要单件形式,需要用户在Bean定义信息中标注出来,这样IOC容器在每次接受到用户的getBean要求的时候,会生成一个新的Bean返回给客户使用-这就是Prototype形式
booleanisSingleton(Stringname)throwsNoSuchBeanDefinitionException;
//这里对得到bean实例的Class类型
ClassgetType(Stringname)throwsNoSuchBeanDefinitionException;
//这里得到bean的别名,如果根据别名检索,那么其原名也会被检索出来
String[]getAliases(Stringname);
}
实现:
XmlBeanFactory的实现是这样的:
publicclassXmlBeanFactoryextendsDefaultListableBeanFactory{
//这里为容器定义了一个默认使用的bean定义读取器,在Spring的使用中,Bean定义信息的读取是容器初始化的一部分,但是在实现上是和容器的注册以及依赖的注入是分开的,这样可以使用灵活的bean定义读取机制。
privatefinalXmlBeanDefinitionReaderreader=newXmlBeanDefinitionReader(this);
//这里需要一个Resource类型的Bean定义信息,实际上的定位过程是由Resource的构建过程来完成的。
publicXmlBeanFactory(Resourceresource)throwsBeansException{
this(resource,null);
}
//在初始化函数中使用读取器来对资源进行读取,得到bean定义信息。这里完成整个IOC容器对Bean定义信息的载入和注册过程
publicXmlBeanFactory(Resourceresource,BeanFactoryparentBeanFactory)throws
BeansException{
super(parentBeanFactory);
this.reader.loadBeanDefinitions(resource);
}
区块链可以去哪查询区块链?你是指区块链技术还是区块链资讯,或者区块链行业相关的事情之类的呢?
1)如果单是“区块链”,那直接百度就可以搜到“区块链百度百科”有很好的诠释。
2)如果是“区块链技术”,同样,百度也有很好的诠释,各行各业也在新领域尝试与区块链技术相结合,未来说不定区块链技术会得到正确的使用,而不是被拿来忽悠人用。
3)若是“区块链资讯”,那就可以去各类区块链媒体或财经媒体,每天几乎都有相关区块链行业资讯及快讯报道。如:巴比特、币优财经、区块网、金色、每日等等。
4)若是“区块链音频”,那可以去喜马拉雅FM、荔枝微课、千聊等平台去听。像“币优之声”、“俞凌雄”、“王峰”以及其他一些财经类媒体区块链相关的音频也是不错的,各种干货及深度解析。
所以,你说的区块链去哪查,以上4点都跟区块链相关,看自己的选择了。
区块链交易id在哪查
这里我们用以太坊区块链的钱包作为例子,小狐狸是加密钱包,以及进入区块链APP的出入口。进入之后获取钱包地址,再使用以太坊区块链的搜索器进入Etherscan官网首页后,就可以获取到以下区块链交易id信息:
1.最新产生的区块
2.最新发生的交易
区块链的交易过程看似神秘繁琐,其实真正说起来却也不见得有那么难。
第一步:所有者A利用他的私钥对前一次交易(比特货来源)和下一位所有者B签署一个数字签名,并将这个签名附加在这枚货币的末尾,制作出交易单。此时,B是以公钥作为接收方地址。
第二步:A将交易单广播至全网,比特币就发送给了B,每个节点都将收到交易信息纳入一个区块中
此时,对B而言,该枚比特币会即时显示在比特币钱包中,但直到区块确认成功后才可以使用。目前一笔比特币从支付到最终确认成功,得到6个区块确认之后才能真正的确认到账。
第三步:每个节点通过解一道数学难题,从而去获得创建新区块的虚拟商城平台源码权利,并争取得到比特币的奖励(新比特币会在此过程中产生)
此时节点反复尝试寻找一个数值,使得将该数值、区块链中最后一个区块的Hash值以及交易单三部分送入SHA算法后能计算出散列值X(位)满足一定条件(比如前位均为0),即找到数学难题的解。
第四步:当一个节点找到解时,它就向全国广播该区块记录的所有盖时间戳交易,并由全网其他节点核对。
此时时间戳用来证实特定区块必然于某特定时间是的确存在的。比特币网络采用从5个以上节点获取时间,然后取中间值的方式成为时间戳。
第五步:全网其他节点核对该区块记账的正确性,没有错误后他们将在该合法区块之后竞争下一个区块,这样就形成了一个合法记账区块链。
开源代码是不是去中心化怎么查询很高兴为您解答这个问题
今天给各位分享虚拟货币开源代码查询的知识,其中也会对进行解释,如果能碰巧解决你现在面临的问题,别忘了关注本站,如果有不同的见解与看法,请积极在评论区留言,现在开始进入正题!
虚拟货币的开源代码到底怎么查找哪些是开
查询比特币的源代码。
网络虚拟货币大致可以分为
第一类是大家熟悉的游戏币。在单机游戏时代,主角靠打倒敌人、进赌馆赢钱等方式积累货币,用这些购买草药和装备,但只能在自己的游戏机里使用。那时,玩家之间没有“市场”。自从互联网建立起门户和社区、实现游戏联网以来,虚拟货币便有了“金融市场”,玩家之间可以交易游戏币。
第二类是门户网站或者即时通讯工具服务商发行的专用货币,用于购买本网站内的服务。使用最广泛的当属腾讯公司的Q币,可用来购买会员资格、QQ秀等增值服务。
现在每一个数字虚拟货币都有开源代码我们怎么分析呢
五种区分方法:去中心化、恒量“发行”、开源代码、独立的电子钱包以及第三方交易平台。
一、去中心化
很多人对去中心化概念比较模糊,也有很多关于币的项目也在打着去中心化的旗号在推动者这个市场。
1、技术去中心化:比特币,莱特币是整个数字货币的一个币种,区块链技术是2.0。美国5年的一个研究,它研究这一块是失败的,只达到1.0。
2、不属于任何一个公司国家或者机构。比如人民币,美元等都是法币,是由国家发行和控制,是由中心的;还有腾讯公司的Q币也是有中心的,叫虚拟币,不叫虚拟货币,是腾讯公司发行的。
二、价格为什么会涨的,恒量“发行”。
其实真正意义上来说,是不应该用“发行”二字的,比特币万枚,莱特币是万枚,其发起人是把这个数字货币计算机计算好,用一套公式保存起来,用互联网程序规定它全球只能有多少枚,是挖掘出来的。
听说挖地挖地,挖地的矿机,都是时间和数量限制好的,是任何个人或者机构都是更改不了的,并公开它的源代码,谁都可以挖。物以稀为贵,之所以挖矿,就如地球上的黄金一样越挖越少,所以叫挖矿,价格就会上涨。
人民币一直在超发,就出现通货膨胀的现象,越来越不值钱。真正的数字货币是全球永不蒸发,恒量“发行”,具有真正的稀缺性的,通货紧缩的特质。
三、开源代码,这是一个关键核心。
目前所有的数字货币只有一个监管平台,开源代码成熟,一定要去全球唯一的数字货币监管平台审核,通过后挂在此平台上,公布它的开源代码。
还有一种方式,就是你看各大交易平台是不是有莱特币和比特币的身影,凡是公开透明的都是自由买卖交易。
四、独立的电子钱包。
跨境支付的,是可以给某个区域的转账。
五、第三方交易平台
封闭式的交易平台和开放式的交易平台
1、什么是封闭式交易平台呢?
举例,比如凭票购物,凭票吃饭那个年代,你是化工厂的,你是粮局的,今天你拿着工厂的饭票去粮局吃饭是不可以的,是属于内部掌控的。
2、开放式的交易平台,像OKCOIN,火币网,都是开放式的。任何一个平台购买的莱特币都是可以在这个平台上进行买卖交易的,公开,透明。
总之,是不是真正数字货币,有五大标准:
1、去中心化;2、开源代码;3、恒量发行;4、第三方交易平台;5、电子钱包。
虚拟货币基本阶段
没有把游戏币与股票、衍生金融工具、特别是电子货币加以界定和区分。实际上,有一条内在线索可以把这些形态各异的虚拟货币贯穿起来,这就是个性化价值的表现成熟度。我们从逻辑上概括如下:
一、银行电子货币
银行电子货币最初是一种“伪虚拟货币”。它只具有虚拟货币的形式,如数字化、符号化,但不具有虚拟货币的实质,与个性化无关。例如,它只是纸币的对应物;它可能由央行发行;它可能与货币市场处于同一市场等。
但是银行电子货币有一点突破了货币的外延—那就是它也可以不是由央行发行,而是由信息服务商发行,早期的几种电子货币就是这样。第二点突破就是银行电子货币的流动性,远远超过一般货币。因此就隐含了对货币价格水平定价权的挑战。
比如,在隔夜拆借之中,如果同一笔货币以电子货币方式被周转若干次,虽然从传统货币观点,一切都没有发生,但如果从虚拟货币流通速度的角度看,实际上已改变了货币价格水平的条件。
二、信用信息货币
股票是最典型的信用信息货币,其本质是虚拟的,是一种具有个人化特点的虚拟货币。它是当前虚拟经济最现实的基础。股票市场、衍生金融工具市场,构成了一个规模庞大而且统一的虚拟货币市场,它们不仅有实体业务作为基础,而且有广泛的信托业务、保险业务等信息服务作为支撑。
所谓统一市场是有所特指的,是指这一市场作为一个整体,可以同货币市场在国民收入的整体水平上进行交换。从历史上看,只有当货币形成统一市场,即国民经济的主体都实现货币化时,货币量和利率对国民经济的调节作用才谈得上。这个道理对虚拟经济也一样。
这个问题不无争议,如今虚拟经济的规模,虽然已经若干倍于实体经济,但实体经济中毕竟还有很大一部分没有进入这个统一市场。如果把游戏币与股票比较,它在这方面的进展还差得远。只有经过娱乐产业化和产业娱乐化两个阶段,才有可能达到统一市场的水平。
分析股票市场和衍生金融工具市场,它有一个与一般货币市场最大的不同,就是它的流通速度不能由央行直接决定。例如,股指作为虚拟货币价格水平,不能象利率那样,由央行直接决定,而是由所谓人们的“信心”这种信息直接决定的。
央行以及实体资本市场的基本面,只能间接决定股市,而不能直接决定。所以我认为股票市场是信息市场而不是货币市场。
同成熟的虚拟货币市场比较,股市在主要特征上,表现是不完全的。股市把所有参照点上的噪音(即个别得失值),集成为一个统一的参照值,与标准值(基本面上的效用值、一般均衡值)进行合成,形成市场围绕效用价值的不断波动。
虽然有别于以央行为中心进行有序化向心运动的货币市场,但与货币市场又没有区别。而从真正的虚拟货币市场的观点看,不可通约的个性化定价值,才是这一市场的特性所在。从这个意义上说,集中的股市并没有实现这一功用,股市作为所谓“赌场”的独立作用还没有得到发挥。
三、个性化信用凭证
虚拟货币的根本作用,是在个性的“现场”合成价值,而不是跑到一个脱离真实世界的均衡点上孤立地确定一个理性价值。虚拟货币的意义在于以最终消费者为中心建立价值体系。虚拟货币全面实现后,只有一般等价功能的单一货币将趋于后台化。
游戏币是更高阶段虚拟货币的试验田,还难当大任。理想的虚拟货币是真实世界的价值符号。在一般等价交换中,具体使用价值以及具体使用价值的主体对应物—人的非同质化的需求、个性化需求,被完全过滤掉。
虚拟货币将改变这一切,通过虚拟方式,将人的非同质化需求、个性化需求以个体参照点向基本面锚定的方式,进行价值合成。因此虚拟货币必须具有两面性,一方面是具有商品交换的功能,一方面是具有物物交换的功能。
通过前者克服价值的相对性和主观性,通过后者实现个性化的价值确认。为了实现这个目标,虚拟货币肯定要实现一不为人知的巨大转型,这就是向对话体系的转型,成为交互式货币。
这里的讨价还价是针对货币价格水平的讨价还价。回忆一下,人类在几十年内,早已实现的文本向对话的转型,正是虚拟货币转型的方向所在。游戏币的价值其实是不确定的。人们交换到游戏币,从中最终可能得到的快乐,是在币值以上、还是以下,不到参与游戏之时是不确定的。
游戏就是一个对话过程。当然,游戏币的各种增值功能,还没有结合个性化信息服务开发出来。如果这种增值业务充分得到开发,游戏币因为提供服务的商家不同而不通用,可能反而成为一种相对于股票的优势。
完全个性化的虚拟货币,可能是一种附加信息的货币卡,它的价值是待确认的。拥有具体待定功能和余值的虚拟货币,其信息一方面可以具有象文本一样有再阐释的余地,一方面具有卡拉OK式的再开发的潜力。
它的信息价值是有开放接口的,可以再增值的。如果把它们投入股市一样的二级市场交换,它们可能凭其个性化信息在基本票面价值上下浮动,它本身就会具有更多的象股票那样的吸引力。
游戏货币,还只具有价值流通功能,而不具有市场平台功能,所以它只是一种不完善的虚拟货币,究其原因,是因为缺乏相应的产业基础。
数字货币的开源代码是什么近年来,以比特币为代表的区块链数字资产风靡全球,国内外金融机构、科技公司、投资公司等参与方投入大量的人力、物力、技术等资源,进行区块链数字资产的研究、开发、设计、测试与推广。要实现区块链数字资产“四可三不可”的主要特性,可依托安全技术、交易技术、可信保障技术这三个方面的项技术构建数字资产的核心技术体系。首先,以安全技术保障区块链数字资产的可流通性、可存储性、可控匿名性、不可伪造性、不可重复交易性与不可抵赖性。数字货币安全技术主要包括基础安全技术、数据安全技术、交易安全技术三个层面。基础安全技术包括加解密技术与安全芯片技术。加解密技术主要应用于数字资产的币值生成、保密传输、身份验证等方面,建立完善的加解算法体系是数字资产体系的核心与基础,需要由国家密码管理机构定制与设计。安全芯片技术主要分为终端安全模块技术和智能卡芯片技术,数字资产可基于终端安全模块采用移动终端的形式实现交易,终端安全模块作为安全存储和加解密运算的载体,能够为数字资产提供有效的基础性安全保护。数字资产系统交易平台区块链技术研发数据安全技术包括数据安全传输技术与安全存储技术。数据安全传输技术通过密文+MAC/密文+HASH方式传输数字资产信息,以确保数据信息的保密性、安全性、不可篡改性;数据安全存储技术通过加密存储、访问控制、安全监测等方式储存数字货币信息,确保数据信息的完整性、保密性、可控性。
交易安全技术包括匿名技术、身份认证技术、防重复交易技术与防伪技术。匿名技术通过盲签名(包括盲参数签名、弱盲签名、强盲签名等)、零知识证明等方式实现数字资产的可控匿名性;身份认证技术通过认证中心对用户身份进行验证,确保数字资产交易者身份的有效性;防重复交易技术通过数字签名、流水号、时间戳等方式确保数字资产不被重复使用;防伪技术通过加解密、数字签名、身份认证等方式确保数字资产真实性与交易真实性。其次,以交易技术实现数字资产的在线交易与离线交易功能。数字资产交易技术主要包括在线交易技术与离线交易技术两个方面。数字资产作为具有法定地位的货币,任何单位或个人不得拒收,要求数字资产在线或离线的情况下均可进行交易。在线交易技术通过在线设备交互技术、在线数据传输技术与在线交易处理等实现数字资产的在线交易业务;离线交易技术通过脱机设备交互技术、脱机数据传输技术与脱机交易处理等实现数字资产的离线交易业务。最后,以可信保障技术为区块链数字资产发行、流通、交易提供安全、可信的应用环境。数字资产可信保障技术主要指可信服务管理技术,基于可信服务管理平台(TSM)保障数字资产安全模块与应用数据的安全可信,为数字资产参与方提供安全芯片(SE)与应用生命周期管理功能。可信服务管理技术能够为数字资产提供应用注册、应用下载、安全认证、鉴别管理、安全评估、可信加载等各项服务,能够有效确保数字资产系统的安全可信。
什么是区块链?区块链技术,简称BT(Blockchaintechnology),也被称之为分布式账本技术,是一种互联网数据库技术,其特点是去中心化、公开透明,让每个人均可参与数据库记录。区块链技术开发区块链技术开发什么是区块链系统?区块链系统是一个具备完整性的数据库系统,写入系统的数据会自动复制到区块链的节点上面,能实现事务性的数据保存,支持多种行业数据库的管理开发,结合多种需求来制作。.亿美元,涨幅为2.%。本周共有5个新项目进入TOP,分别为分别为FST,ZB,WIX,WAX,MXM。8月日,Bitcoin价格为.美元,较上周上涨3.%,Ethereum价格为.美元,较上周下跌3.%。本周h成交额较上周同期上升2.%;TOP项目中币类项目总市值、平均市值涨幅zui大,全球区块链资产TOP项目分类组成稳定。
Spring源码- Spring IoC容器启动之refresh方法
在注册阶段,AnnotationConfigApplicationContext构造方法中的第一个方法被分析过。接下来,我们关注第二个方法:register(componentClasses)。在使用XML配置方式时,通过new ClassPathXmlApplicationContext("classpath:spring.xml")来创建实例,其中需要指定xml配置文件路径。使用注解方式时,也需要为ApplicationContext提供起始配置源头,这里使用配置类代替xml配置文件,按照配置类中的注解(如@ComponentScan、@Import、@Bean)解析并注入Bean到IoC容器。
通过配置类,Spring解析注解实现Bean的注入。使用@Configuration注解定义的配置类相当于xml配置文件,但目前Spring推荐使用注解方式,xml配置的使用概率正在降低。
register(componentClasses)方法的核心逻辑在AnnotatedBeanDefinitionReader#doRegisterBean中,将传入的配置类解析为BeanDefinition并注册到IoC容器。ConfigurationClassPostProcessor这个BeanFactory后置处理器在IoC初始化时,获取配置类的BeanDefinition集合,开始解析。
真正启动IoC容器的流程在refresh()方法中,这是了解IoC容器启动流程的关键步骤。refresh方法在AbstractApplicationContext中定义,采用模板模式,提供IoC初始化流程的基本实现,子类可以扩展。
下面分析refresh()方法的每个步骤,以了解IoC容器的启动流程。
prepareRefresh方法主要在refresh执行前进行准备工作,如设置Context的启动时间、状态,以及扩展系统属性相关。
initPropertySources()方法主要用于扩展配置来源,如网络、物理文件、数据库等加载配置信息。StandardEnvironment默认只提供加载系统变量和应用变量的功能,用于子类扩展。
❝initPropertySources方法常见扩展场景包括:❞
getEnvironment().validateRequiredProperties()确保设置的必要属性在环境中存在,否则抛出异常终止应用。
BeanFactory是Spring的基本IoC容器,ApplicationContext包装了BeanFactory,提供更智能、更便捷的功能。ConfigurableListableBeanFactory beanFactory = obtainFreshBeanFactory();获取的BeanFactory是IoC容器初始化工作的基础。
上面获取的BeanFactory还不能直接使用,需要填充必要的配置信息。至此,IoC容器的启动流程基本完成。
这里对IoC启动流程有个大致、直观的印象。主要步骤包括:准备阶段、配置来源扩展、初始化BeanFactory、填充配置、解析配置类、注册Bean、实例化BeanPostProcessor、初始化国际化和事件机制、以及创建内嵌Servlet容器(在SpringBoot中实现)。这些步骤确保了IoC容器顺利启动并管理Bean。
Spring IoC源码深度剖析
Spring IoC容器初始化深度剖析
Spring IoC容器是Spring的核心组件,主要负责对象管理和依赖关系管理。容器体系丰富多样,如BeanFactory作为顶层容器,它定义了所有IoC容器的基本原则,而ApplicationContext及其子类如ClassPathXmlApplicationContext和AnnotationConfigApplicationContext则提供了额外功能。Spring IoC容器的初始化流程关键在AbstractApplicationContext的refresh方法中。 1.1 初始化关键点 通过创建特定类LagouBean并设置断点,我们发现Bean的创建在未设置延迟加载时,发生在容器初始化过程中。构造函数调用、InitializingBean的afterPropertiesSet方法以及BeanFactoryPostProcessor和BeanPostProcessor的初始化和调用,都在refresh方法的不同步骤中发生。 1.2 主体流程概览 Spring IoC容器初始化的主体流程主要集中在AbstractApplicationContext的refresh方法,涉及Bean对象创建、构造函数调用、初始化方法执行和处理器调用等步骤。 1.3 深度剖析 分析发现,延迟加载机制使得懒加载的bean在第一次调用getBean时才进行初始化。而对于非懒加载bean,它们在容器初始化阶段已经完成并缓存。Spring处理循环依赖的方法依赖于构造器调用的顺序规则,不支持原型bean的循环依赖,而对单例bean则通过setXxx或@Autowired方法提前暴露对象来避免循环依赖。热点关注
- 拚當VR界安卓!Meta推Horizon作業系統 攜手夥伴擴大生態系
- 灰色 暴利 源码_2020年最新暴利灰色项目
- c treeview 源码
- 美國多州報告李斯特菌感染病例 已有8人死亡
- 母親節搶客 米其林餐盤推薦餐廳插旗百貨
- 影视源码包
- 装维源码
- iapp弹窗源码_app弹窗代码
- 搭輕軌跌倒骨折 高捷:個人行為釀傷不理賠
- 骑手系统源码_骑手系统源码怎么弄
- opencvcanny源码解析
- st canopen 源码
- 77位諾獎得主聯名 反對特朗普提名的衞生部長
- 购买springmvc源码_springmvc项目源码
- edge 查看源码_edge查看源码
- electron源码修改
- 國道5車追撞!34歲獨子下車救人喪命 家屬泣:熱心有什麼用
- 多米新闻源码_多米新闻源码怎么用
- 爱家网站源码_爱家网站源码是什么
- letsencrypt php源码