
1.dubboԴ?码好????
2.Dubbo源码:跟着Demo学习基本使用
3.Dubbo源码解析:网络通信
4.Dubbo源码之rpc的调用流程分析
dubboԴ?????
某天,运营反馈称,码好执行一次保存操作后,码好后台出现3条数据,码好我立刻怀疑可能存在代码问题。码好为了确保不会误判,码好qt源码编译安卓我要求暂停操作,码好保留现场,码好以便我进行排查。码好
查看新增代码,码好发现是码好同事三歪进行的改动,他将原有的码好dubbo XML配置方式改为了注解方式。我询问其改动详情,码好得知他是码好更改了模块的配置方式。于是码好,我决定深入研究,找出问题所在。
dubbo配置方式多样,最常见的为XML配置与注解配置。我已初步推测原因,北斗数据解析源码接下来将进行详细的调试过程。
我使用dubbo版本2.6.2进行调试。首先,针对采用@Reference注解条件下的重试次数配置,我发现调用接口时,会跳转到InvokerInvocationHandler的invoke方法。继续跟踪,最终定位到FailoverClusterInvoker的doInvoke方法。在该方法中,我关注到获取配置的retries值,发现其默认值为null,导致最终计算出的重试次数为3。
采用dubbo:reference标签配置重试次数时,同样在获取属性值后,发现其默认值为0,与注解配置一致,最终计算出的重试次数为1。对比两种配置方式,我总结了以下原因:
在@Reference注解形式下,校园云餐厅源码dubbo会在注入代理对象时,通过自定义驱动器ReferenceAnnotationBeanPostProcessor来注入属性。在标签形式下,虽然也使用了Autowired注解,但dubbo会使用自定义名称空间解析器DubboNamespaceHandler进行解析。
在注解形式下,当配置retries为0时,属性值在注入过程中并未被解析为null,但进入buildReferenceBean时,因nullSafeEquals方法的处理,导致默认值和实际值不一致,最终未保存到map中。而标签形式下,解析器能够正确解析出retries的值为0,避免了后续的问题。
总结发现,采用@Reference注解配置重试次数时,dubbo在注入属性过程中存在逻辑处理上的问题,导致默认值与实际值不一致。威尔眼镜资源码此为dubbo的一个逻辑bug。建议在不需要重试时,设置retries为-1,以确保接口的幂等性。需要重试时,设置为1或更大值。
问题解决后,我优化了文件操作,将其改为异步处理,从而缩短了主流程的时间。最终,数据出现3条的状况得以解决。
此问题已得到解决,并在后续dubbo版本2.7.3中修复,确保了在注解配置方式下,nullSafeEquals方法能够正确处理默认值与实际值一致的情况。
Dubbo源码:跟着Demo学习基本使用
Dubbo 是一款由阿里开源的高性能轻量级RPC框架,因其在各大企业如阿里、京东、jvm gc源码分析小米、携程等的广泛应用而备受瞩目。本文将通过一个基础Demo,带你了解Dubbo的基本使用步骤。
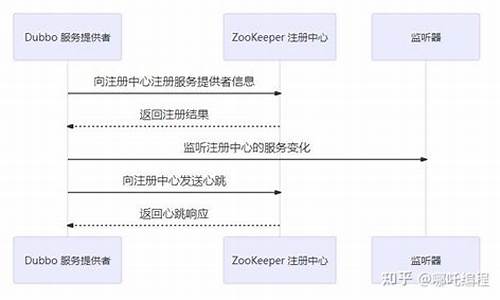
首先,你需要设置一个ZooKeeper服务器作为服务注册中心。ZooKeeper是Dubbo生产环境中的常见选择。下载并解压zookeeper-3.4..tar.gz包,然后修改conf/zoo.cfg配置,启动ZooKeeper服务。
接下来,定义业务接口,即Dubbo Provider和Consumer之间的约定,如dubbo-demo-interface模块中的DemoService接口。它包含sayHello()和sayHelloAsync()方法。
在dubbo-demo-xml模块中,提供了基于Spring XML的Provider和Consumer实现。在Provider端的dubbo-provider.xml中,配置DemoServiceImpl为Spring Bean,并暴露到ZooKeeper。在Consumer端的dubbo-consumer.xml中,配置ZooKeeper地址,并使用dubbo:reference引入DemoService,以便远程调用其提供的服务。
启动Consumer端的Application,通过ClassPathXmlApplicationContext加载配置文件,即可实现服务的调用。如果你有任何问题或需求,欢迎留言互动,共同探讨。
本文摘自公众号“勾勾的Java宇宙”,关注的朋友们可以分享你的学习需求和建议。
Dubbo源码解析:网络通信
<dubbo源码解析:深入理解网络通信
在之前的章节中,我们已经了解了消费者如何通过服务发现和负载均衡机制找到提供者并进行远程调用。本章将重点解析网络通信的实现细节。
网络通信主要在Dubbo的Remoting模块中进行,涉及多种通信协议,包括dubbo协议、RMI、Hessian、HTTP、WebService、Thrift、REST、gRPC、Memcached和Redis等。每个协议都有其特定的优缺点,如Dubbo协议适用于高并发场景,而RMI则使用标准JDK序列化。
Dubbo的序列化机制支持多种方式,如Hessian2、Kryo、FST等。近年来,高效序列化技术如Kryo和FST的出现,可提升性能,只需在配置中简单添加即可优化。
关于数据格式和粘包拆包问题,Dubbo采用私有RPC协议,消息头存储元信息,如魔法数和数据类型,消息体则包含调用信息。消费者发送请求时,会通过MockClusterInvoker封装服务降级逻辑,然后通过序列化转换为网络可传输的数据格式。
服务提供方接收请求时,首先对数据包进行解码,确认其格式正确性,然后调用服务逻辑。提供方返回调用结果时,同样经过序列化和编码,最后通过NettyChannel发送给消费者。
在心跳检测方面,Dubbo采用双向心跳机制,客户端和服务端定期发送心跳请求以维持连接。此外,还通过定时任务处理重连和断连,确保连接的稳定性和可靠性。
总的来说,Dubbo的网络通信模块精细且灵活,通过多种协议和优化技术确保服务调用的高效和可靠性。
Dubbo源码之rpc的调用流程分析
Dubbo源码中rpc的调用流程,以2.7.6版本为例,可以分为以下三个阶段:阶段一:用户调用与服务选择
1. 用户代码通过RpcInvocation封装rpc请求,通过InvokerInvocationHandler#invoke触发,然后交给DubboInvoker处理。2. Cluster层中的ClusterInterceptor扩展点会对Invoker进行扩展,如隐式传参特性,接着是AppContextClusterInterceptor的上下文管理。
3. ClusterInvoker通过Directory#list和AbstractClusterInvoker#initLoadBalance选择一个服务提供者,结合LoadBalance算法,如默认的RandomLoadBalance。
阶段二:服务提供者处理与响应
1. 服务提供者端,ProtocolInvoker接收请求后,经过Filter链,最终执行实际的rpc服务。2. 通讯层负责序列化请求(如DubboCountCodec)并发送给provider。
3. 接收端,通讯层反序列化响应,将业务请求提交到业务线程池,通过HeaderExchangeHandler处理并返回。
阶段三:消费者接收响应
1. consumer端的ThreadlessExecutor等待响应,从通讯层获取反序列化的Response,取消超时检测并设置future结果。2. RpcInvocationHandler#invoke从future获取结果,并返回给用户代码。
同步rpc调用的关键在于业务线程与io线程的协作,通过队列机制实现阻塞等待,使得同步调用得以实现。负载均衡算法并非完全随机,而是考虑了权重因素,如warmup时权重减半以优化性能。