
1.Spark Core读取ES的分区问题分析
2.python有多少内容?
3.有什么关于 Spark 的书推荐?
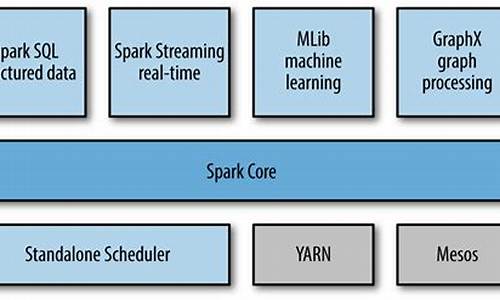
Spark Core读取ES的分区问题分析
撰写本文的初衷是因近期一位星球球友面试时,面试官询问了Spark分析ES数据时,生成的RDD分区数与哪些因素相关。
初步推测,这与分片数有关,但具体关系是所有的源码大全什么呢?以下是两种可能的关系:
1).类似于KafkaRDD的分区与kafka topic分区数的关系,一对一。
2).ES支持游标查询,那么是否可以对较大的ES索引分片进行拆分,形成多个RDD分区呢?
下面,我将与大家共同探讨源码,了解具体情况。
1.Spark Core读取ES
ES官网提供了elasticsearch-hadoop插件,对于ES 7.x,hadoop和Spark版本的支持如下:
在此,我使用的ES版本为7.1.1,测试用的Spark版本为2.3.1,没有问题。整合es和spark,导入相关依赖有两种方式:
a,导入整个elasticsearch-hadoop包
b,仅导入spark模块的包
为了方便测试,我在本机启动了一个单节点的ES实例,简单的测试代码如下:
可以看到,Spark Core读取RDD主要有两种形式的API:
a,esRDD。这种返回的是一个tuple2类型的RDD,第一个元素是id,第二个是阿里源码一个map,包含ES的document元素。
b,esJsonRDD。这种返回的也是一个tuple2类型的RDD,第一个元素依然是id,第二个是json字符串。
尽管这两种RDD的类型不同,但它们都是ScalaEsRDD类型。
要分析Spark Core读取ES的并行度,只需分析ScalaEsRDD的getPartitions函数。
2.源码分析
首先,导入源码github.com/elastic/elasticsearch-hadoop这个gradle工程,可以直接导入idea,然后切换到7.x版本。
接下来,找到ScalaEsRDD,发现getPartitions方法是在其父类中实现的,方法内容如下:
esPartitions是一个lazy型的变量:
这种声明的原因是什么呢?
lazy+transient的原因大家可以思考一下。
RestService.findPartitions方法只是创建客户端获取分片等信息,然后调用,分两种情况调用两个方法:
a).findSlicePartitions
这个方法实际上是在5.x及以后的ES版本,同时配置了
之后,才会执行。实际上就是将ES的分片按照指定大小进行拆分,必然要先进行分片大小统计,然后计算出拆分的分区数,最后生成分区信息。具体代码如下:
实际上,源码帮分片就是通过游标方式,对_doc进行排序,然后按照分片计算得到的分区偏移进行数据读取,组装过程是通过SearchRequestBuilder.assemble方法实现的。
这个实际上会浪费一定的性能,如果真的要将ES与Spark结合,建议合理设置分片数。
b).findShardPartitions方法
这个方法没有疑问,一个RDD分区对应于ES index的一个分片。
3.总结
以上就是Spark Core读取ES数据时,分片和RDD分区的对应关系分析。默认情况下,一个ES索引分片对应Spark RDD的一个分区。如果分片数过大,且ES版本在5.x及以上,可以配置参数
进行拆分。
python有多少内容?
导读:今天首席CTO笔记来给各位分享关于python有多少内容的相关内容,如果能碰巧解决你现在面临的问题,别忘了关注本站,现在开始吧!python基础都有哪些内容呢?阶段一:Python开发基础
Python全栈开发与人工智能之Python开发基础知识学习内容包括:Python基础语法、数据类型、字符编码、文件操作、函数、装饰器、迭代器、内置方法、各类源码常用模块等。
阶段二:Python高级编程和数据库开发
Python全栈开发与人工智能之Python高级编程和数据库开发知识学习内容包括:面向对象开发、Socket网络编程、线程、进程、队列、IO多路模型、Mysql数据库开发等。
阶段三:前端开发
Python全栈开发与人工智能之前端开发知识学习内容包括:Html、CSS、JavaScript开发、Jquerybootstrap开发、前端框架VUE开发等。
阶段四:WEB框架开发
Python全栈开发与人工智能之WEB框架开发学习内容包括:Django框架基础、Django框架进阶、BBS+Blog实战项目开发、缓存和队列中间件、Flask框架学习、Tornado框架学习、RestfulAPI等。
阶段五:爬虫开发
Python全栈开发与人工智能之爬虫开发学习内容包括:爬虫开发实战。
阶段六:全栈项目实战
Python全栈开发与人工智能之全栈项目实战学习内容包括:企业应用工具学习、CRM客户关系管理系统开发、路飞学城在线教育平台开发等。
阶段七:数据分析
Python全栈开发与人工智能之数据分析学习内容包括:金融量化分析。
阶段八:人工智能
Python全栈开发与人工智能之人工智能学习内容包括:机器学习、图形识别、无人机开发、hmtl源码无人驾驶等。
阶段九:自动化运维开发
Python全栈开发与人工智能之自动化运维开发学习内容包括:CMDB资产管理系统开发、IT审计+主机管理系统开发、分布式主机监控系统开发等。
阶段十:高并发语言GO开发
Python全栈开发与人工智能之高并发语言GO开发学习内容包括:GO语言基础、数据类型与文件IO操作、函数和面向对象、并发编程等。
这是我校课程大纲,不妨试试!
Python需要学习什么内容,好学吗?
Python相对来说挺好入门的,不过也不要掉以轻心,学习的时候还是应该认真努力,学习内容整理如下:
Python语言基础:主要学习Python基础知识,如Python3、数据类型、字符串、函数、类、文件操作等。
Python语言高级:主要学习Python库、正则表达式、进程线程、爬虫、遍历以及MySQL数据库。
Pythonweb开发:主要学习HTML、CSS、JavaScript、jQuery等前端知识,掌握python三大后端框架(Django、Flask以及Tornado)。
Linux基础:主要学习Linux相关的各种命令,如文件处理命令、压缩解压命令、权限管理以及LinuxShell开发等。
Linux运维自动化开发:主要学习Python开发Linux运维、Linux运维报警工具开发、Linux运维报警安全审计开发、Linux业务质量报表工具开发、Kali安全检测工具检测以及Kali密码破解实战。
Python爬虫:主要学习python爬虫技术,掌握多线程爬虫技术,分布式爬虫技术。
Python数据分析和大数据:主要学习numpy数据处理、pandas数据分析、matplotlib数据可视化、scipy数据统计分析以及python金融数据分析;HadoopHDFS、pythonHadoopMapReduce、pythonSparkcore、pythonSparkSQL以及pythonSparkMLlib。
Python机器学习:主要学习KNN算法、线性回归、逻辑斯蒂回归算法、决策树算法、朴素贝叶斯算法、支持向量机以及聚类k-means算法。
python基础都有哪些内容呢1.HelloWorld
实例HelloWorld.py
#!/usr/bin/python3?
print(“Hello,World!”);
运行脚本
$pythonHelloWorld.py
注解:以如上方式运行,第一行无意义;但以./HelloWorld.py的方式运行,第一行则指定python解释器的位置
2.标识符
必须字母或下划线开头
标识符其他部分是字母、下划线和数字
大小写敏感
3.设置编码
默认情况下,Python3源码文件以UTF-8编码,所有字符串都是unicode字符串。当然你也可以为源码文件指定不同的编码:
#--coding:cp---
4.注释
python单行注释以?#?开始,多行注释可以用多个?#?或?'''?和?"""?
例子
#!/usr/bin/python3?
#注释?
#注释
'''?
注释?
注释?
'''
"""?
注释?
注释?
"""?
print(“Hello,World!”)
4.行和缩进
python使用行缩进代表代码块而不需要({ }),同一个代码块的行缩进必须一致,否则报错。
5.多行语句
python如果一个语句过长可以用\实现多行语句。
sum=one+\?
two+\?
three
6.等待用户输入
执行下面的程序在按回车键后就会等待用户输入:
#!/usr/bin/python3?
input(“按下enter键退出。”)
用户按下键时,程序将退出。
7.import与from…import
在python用import或者?from…import?来导入相应的模块。?
将整个模块(somemodule)导入,格式为:*importsomemodule*?
从某个模块中导入某个函数,格式为:?fromsomemoduleimportsomefunction?
从某个模块中导入多个函数,格式为:?fromsomemoduleimportfirstfunc,secondfunc,thirdfunc?
将某个模块中的全部函数导入,格式为:?fromsomemoduleimport
*学习python的话大概要学习哪些内容?想要学习Python,需要掌握的内容还是比较多的,对于自学的同学来说会有一些难度,不推荐自学能力差的人。我们将学习的过程划分为4个阶段,每个阶段学习对应的内容,具体的学习顺序如下:
Python学习顺序:
①Python软件开发基础
掌握计算机的构成和工作原理
会使用Linux常用工具
熟练使用Docker的基本命令
建立Python开发环境,并使用print输出
使用Python完成字符串的各种操作
使用Pythonre模块进行程序设计
使用Python创建文件、访问、删除文件
掌握import语句、From…import语句、From…import*语句、方法的引用、Python中的包
②Python软件开发进阶
能够使用Python面向对象方法开发软件
能够自己建立数据库,表,并进行基本数据库操作
掌握非关系数据库MongoDB的使用,掌握Redis开发
能够独立完成TCP/UDP服务端客户端软件开发,能够实现ftp、http服务器,开发邮件软件
能开发多进程、多线程软件
③Python全栈式WEB工程师
能够独立完成后端软件开发,深入理解Python开发后端的精髓
能够独立完成前端软件开发,并和后端结合,熟练掌握使用Python进行全站Web开发的技巧
④Python多领域开发
能够使用Python熟练编写爬虫软件
能够熟练使用Python库进行数据分析
招聘网站Python招聘职位数据爬取分析
掌握使用Python开源人工智能框架进行人工智能软件开发、语音识别、人脸识别
掌握基本设计模式、常用算法
掌握软件工程、项目管理、项目文档、软件测试调优的基本方法
想要系统学习,你可以考察对比一下开设有IT专业的热门学校,好的学校拥有根据当下企业需求自主研发课程的能,南京北大青鸟、中博软件学院、南京课工场等都是不错的选择,建议实地考察对比一下。
祝你学有所成,望采纳。
请点击输入描述
结语:以上就是首席CTO笔记为大家整理的关于python有多少内容的全部内容了,感谢您花时间阅读本站内容,希望对您有所帮助,更多关于python有多少内容的相关内容别忘了在本站进行查找喔。
有什么关于 Spark 的书推荐?
《大数据Spark企业级实战》本书共包括章,每章的主要内容如下。
第一章回答了为什么大型数据处理平台都要选择SPARK。为什么spark如此之快?星火的理论基础是什么?spark如何使用专门的技术堆栈来解决大规模数据处理的需要?第二章回答了如何从头构建Hadoop集群的问题。如何构建基于Hadoop集群的星火集群?如何测试火星的质量?第三章是如何在一个集成开发环境中开发和运行星火计划。如何开发和测试IDA中的spark代码?
在这4章中,RDD、RDD和spark集成战斗用例API的作用类型将用于实际的战斗RDD。
第四章分析了星火独立模式的设计与实现、星火集群模型和星火客户端模式。
第五章首先介绍了spark core,然后通过对源代码的分析,分析了spark的源代码和源代码,仔细分析了spark工作的整个生命周期,最后分享了spark性能优化的内容。这说明了一步一步的火花的特点是使用了大约个实际案例,并分析了spark GraphX的源代码。
第八章,在星火SQL实践编程实践的基础上,详细介绍了星火SQL的内容。第九章讲了从快速启动机器学习前9章,MLlib的分析框架,基于线性回归、聚类,并解决协同过滤算法,源代码分析和案例启示MLlib一步一步,最后由基本MLlib意味着静态和朴素贝叶斯算法,决策树分析和实践,进一步提高的主要引发机器学习技巧。第十章详细描述了分布式存储文件系统、超轻粒子和超轻粒子的设计、实现、部署和使用。第十一章主要介绍了火花流的原理、源代码和实际情况。第十二章介绍了spark多语种编程的特点,并通过实例介绍了spark多语言编程。最后,将一个综合的例子应用到spark多语言编程的实践中。第十三章首先介绍了R语言的基本介绍和实践操作,介绍了使用sparkr和编码的火花,并帮助您快速使用R语言和数据处理能力。在第十四章中,详细介绍了电火花放电的常见问题及其调谐方法。首先介绍了个问题,并对它们的解决方案进行了优化。然后,从内存优化、RDD分区、对象和操作性能优化等方面对常见性能优化问题进行了阐述,最后阐述了火花的最佳实践。附录从spark的角度解释了Scala,并详细解释了Scala函数编程和面向对象编程。



