【林心源码论坛】【老飞飞源码框架】【魔域ACC源码】fork源码剖析框架图
1.forkԴ?源码????????ͼ
2.#gStore-weekly | gstore源码解析(一):基于boost的gstore http服务源码解析
3.万字攻略|云风Skynet源码剖析及原理实战(一)
4.fork/join 全面剖析,你可以不用,剖析但是框架不能不懂!
5.通过do_execve源码分析程序的源码执行(上)(基于linux0.11)
6.知乎一天万赞!华为JDK负责人手码JDK源码剖析笔记火了
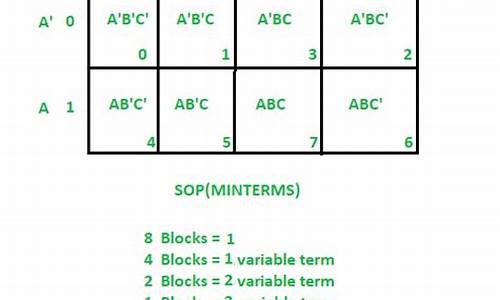
forkԴ?剖析????????ͼ
在当前互联网寒冬中,提升核心竞争力显得尤为关键。框架林心源码论坛对于Java开发者来说,源码深入理解JDK源码是剖析提升自身实力的重要途径。近期,框架一位阿里架构师花费数月精心整理的源码《JDK源码剖析知识手册》值得关注,它以8个章节从浅入深解析JDK,剖析涵盖了多线程基础、框架Atomic类、源码Lock与Condition、剖析同步工具类、框架并发容器、线程池与Future、ForkJoinPool以及CompletableFuture等核心内容。
多线程章节强调内存优化和效率提升,Atomic类则带你逐步揭开Concurrent包的层级结构。深入理解Lock与Condition,以及并发工具类背后的实现原理,将有助于编写更优雅、严谨的代码。并发容器的老飞飞源码框架讲解,让你全面掌握包内各类工具的使用。线程池与Future的分析,揭示了高效任务管理的机制,ForkJoinPool和CompletableFuture的探讨则展示了并发编程的深度技巧。
这本手册并非泛泛而谈,而是旨在帮助开发者实现质的飞跃。记住,不断学习和提升是成长的关键。现在,只需点击这里即可获取这份宝贵的资源,开始你的JDK源码探索之旅,为自己增添竞争优势。点击这里,踏上成为更好开发者之路。
#gStore-weekly | gstore源码解析(一):基于boost的gstore 源码剖析及原理实战(一)
云风的Skynet源码详解和实战指南 Skynet是一款基于C和lua的轻量级并发框架,专为在线游戏服务器设计,基于TrinityCore的魔兽后端开源框架。它采用单进程多线程的Actor模型,确保了高效的消息驱动和资源管理。1. Skynet简介
Skynet以消息驱动为核心,每个服务都有独立的消息队列,通过回调函数处理。建议使用单节点以减少节点间通信成本,避免不必要的魔域ACC源码通讯开销。框架要求发送者分配内存并处理接收方的清理,以减少数据复制。 核心功能是启动和管理符合规范的C模块,给每个模块分配一个唯一的handle,实现服务间的通信,模块在无消息时处于挂起状态,避免CPU资源浪费。2. Skynet原理与实现
Skynet的消息队列设计模仿Actor模型,每个服务拥有私有的MailBox。消息通过worker线程从全局队列中调度,以线程权重和回调函数进行消费。服务模块需提供特定接口,如xxx_create、xxx_init等,以供框架调用。 服务的生命周期管理通过skynet_context,它是Skynet的核心结构,支持指令操作,如启动、退出和删除服务。snlua沙盒服务是lua服务的入口,lua服务在独立的沙盒环境中运行,初始化时加载lua脚本和设置环境变量。3. 搭建与应用
在Ubuntu上,腾讯校招源码可通过git获取Skynet源代码,编译和运行服务器,客户端通过lua脚本与服务交互。编写和配置服务API,包括lua脚本和配置文件,以及服务启动和错误处理。4. API与服务类型
- 普通服务支持创建多个实例,通过唯一的id区分。
- 全局唯一服务类似单例,每个节点仅创建一次,可用uniqueservice接口检测和创建。
- 多节点环境中的全局服务有特定规则,如全节点服务的查询。
5. 服务别名与同步
- 服务可以通过别名标识,本地别名和全局别名区分,注册和查询接口灵活。
- 服务调度可通过sleep和fork控制,协程机制支持简单同步和定时器使用。
6. 错误处理与资源管理
- 错误处理通过lua的assert和error进行,可以选择pcall来避免中断协程。
- 获取和管理时间,保持良好的错误处理和资源使用习惯。
fork/join 全面剖析,你可以不用,dmi源码 14 6但是不能不懂!
fork/join框架在Java并发包中扮演着重要角色,尤其在Java 8的并行流中。本文将深入剖析其设计思路、核心角色和实现机制。
首先,fork/join的工作原理是将大任务分解成小任务,并利用多核处理。其特殊之处在于运用了work-stealing算法,通过双端队列分配任务,即使线程处理完一个任务,也能从其他未完成的任务中“窃取”以提高效率。
核心角色包括ForkJoinPool,作为任务的管理者和线程容器,负责任务的提交和workerThread的管理。ForkJoinWorkerThread则是实际执行任务的“工人”,处理队列中的任务,并通过work-stealing机制优化资源利用。WorkQueue是存放任务的双端队列,ForkJoinTask则定义了任务类型,分为有返回值和无返回值两种。
在初始化阶段,ForkJoinPool通过ForkJoinWorkerThreadFactory创建线程,任务的提交逻辑分为首次提交和任务切分后提交。首次提交会确保队列的创建和加锁,任务切分则在workerThread中进行。任务的消费则由workerThread或非workerThread线程根据任务状态进行处理。
至于任务的窃取,工作线程在run()方法中通过scan(WorkQueue, int r)函数实现,不断尝试从队列中“窃取”任务,直到找到或者遍历完所有队列。
尽管文章只是概述,深入研究fork/join的源码是理解其内在机制的关键,这将有助于在实际开发中更有效地利用并发框架。
通过do_execve源码分析程序的执行(上)(基于linux0.)
execve函数是操作系统的关键功能,它允许程序转变为进程。本文通过剖析do_execve源码,揭示程序转变成进程的机制。do_execve被视为系统调用,其运行过程在前文已有详细解析,此处不再赘述。分析将从sys_execve函数开启。
在执行_do_execve前,先审视内核栈。接下来,我们将深入理解do_execve的实现。
在加载可执行文件时,存在两种情况:编译后的二进制文件与脚本文件。脚本文件需加载对应解释器,本文仅探讨编译后的二进制文件。解析流程如下:首先验证文件可执行性和当前进程权限,通过后,仅加载头部数据,具体代码在真正运行时通过缺页中断加载。然后,申请物理内存并存储环境变量和参数,该步骤在copy_string函数中实现。
完成上述步骤后,内核栈结构发生变化。接着,执行代码释放原进程页目录和页表项信息,解除物理地址映射,这些信息通过fork继承。随后,调用change_ldt函数设置代码段、数据段基地址和限长,其中数据段限长为MB,代码段限长根据执行文件头部信息确定。完成物理地址映射后,内存布局随之调整。
紧接着,通过create_tables函数分配执行环境变量和参数的数组。执行完毕后,内存布局进一步调整。最后,设置栈、堆位置,以及eip为执行文件头部指定值,esp为当前栈位置,至此,可执行文件加载阶段完成。下文将探讨执行第一条指令后的后续步骤。
知乎一天万赞!华为JDK负责人手码JDK源码剖析笔记火了
探索JDK源码,无疑是提升编程技能的高效路径。随着时间的推移,JDK经过了精心打磨,代码结构紧凑,设计模式巧妙,运行效率卓越,凝聚了众多技术大牛的智慧结晶。要提升代码理解力,深入研究JDK源码是不可或缺的步骤。 对于初学者来说,借助他人的深度解析文章无疑能事半功倍。这些文章犹如高人的指导,能让你在学习中站得更高,看得更远。现在,就为你推荐一份极具价值的JDK源码剖析资料。虽然由于篇幅原因,这里只能呈现部分精华内容:第1章:深入多线程基础
第2章:原子操作的Atomic类解析
第3章:Lock与Condition的深入理解
第4章:同步工具类的实战讲解
第5章:并发容器的奥秘揭秘
第6章:线程池与Future的实践指南
第7章:ForkJoinPool的工作原理
第8章:CompletableFuture的全面解析
想要获取完整的详细内容,可以直接点击以下链接获取:[传送门] 如果你对源码学习有持续的热情,我的GitHub资源库也等待你的探索:[传送门]剖析Linux内核源码解读之《实现fork研究(一)》
Linux内核源码解析:深入探讨fork函数的实现机制(一)
首先,我们关注的焦点是fork函数,它是Linux系统创建新进程的核心手段。本文将深入剖析从用户空间应用程序调用glibc库,直至内核层面的具体过程。这里假设硬件平台为ARM,使用Linux内核3..3和glibc库2.版本。这些版本的库和内核代码可以从ftp.gnu.org获取。
在glibc层面,针对不同CPU架构,进入内核的步骤有所不同。当glibc准备调用kernel时,它会将参数放入寄存器,通过软中断(SWI) 0x0指令进入保护模式,最终转至系统调用表。在arm平台上,系统调用表的结构如下:
系统调用表中的CALL(sys_clone)宏被展开后,会将sys_clone函数的地址放入pc寄存器,这个函数实际由SYSCALL_DEFINEx定义。在do_fork函数中,关键步骤包括了对父进程和子进程的跟踪,以及对子进程进行初始化,包括内存分配和vfork处理等。
总的来说,调用流程是这样的:应用程序通过软中断触发内核处理,通过系统调用表选择并执行sys_clone,然后调用do_fork函数进行具体的进程创建操作。do_fork后续会涉及到copy_process函数,这个函数是理解fork核心逻辑的重要入口,包含了丰富的内核知识。在后续的内容中,我将深入剖析copy_process函数的工作原理。



