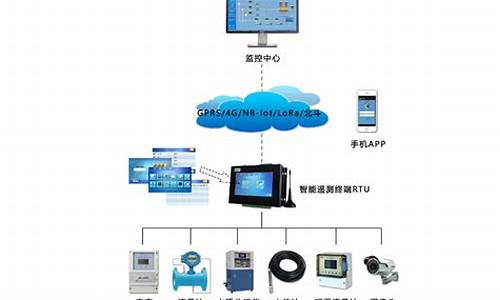
1.swin transformerç解è¦ç¹
2.Python程序开发系列一文搞懂argparse模块的图像常见用法(案例+源码)
3.10分钟!用Python实现简单的分类人脸识别技术(附源码)
4.使用PaddleClas(2.5)进行分类
5.(三十八)通俗易懂理解——MXNet如何生成.lst文件和.rec文件
6.轻松理解ViT(Vision Transformer)原理及源码
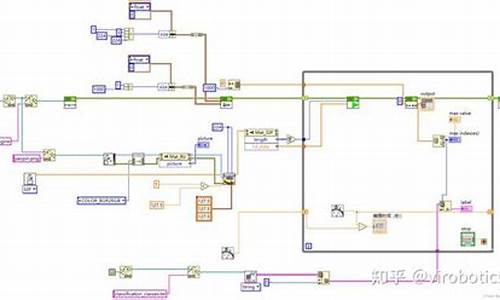
swin transformerç解è¦ç¹
è¿æ¯è·éçå类以ååå²æºç ä»ç»ï¼å¤§å®¶æéè¦å¯ä»¥åèä¸ä¸ï¼1ã Swin-Transformeråç±»æºç (å·²è·é)
2ã Swin-Transformeråå²æºç (å·²è·é)
3ã Swin-Unet(åå²æ¹ç¼)
æ们å设å¾çç大å°æ¯Ãçï¼çªå£å¤§å°æ¯åºå®çï¼7Ã7ãè¿éæ¯ä¸ªæ¹æ¡é½æ¯ä¸ä¸ªçªå£ï¼æ¯ä¸ªçªå£æ¯åºå®æ7Ã7个patchï¼ä½æ¯patchç大å°æ¯ä¸åºå®çï¼å®ä¼éçpatch mergingçæä½èåçååãæ¯å¦æ们çè¿å¿ï¼patch大å°æ¯4Ã4çï¼é£æä¹åæ8Ã8å¢ï¼æ们æå¨è¾¹4个çªå£çpatchæ¼å¨ä¸èµ·ï¼ç¸å½äºpatchæ©å¤§äº2Ã2åï¼ä»èå¾å°8Ã8大å°çpatchã
æ们åç°ç»è¿è¿ä¸ç³»åçæä½ä¹åï¼patchçæ°ç®å¨åå°ï¼æåæ´å¼ å¾åªæä¸ä¸ªçªå£ï¼7个patchãæ以æ们å¯ä»¥è®¤ä¸ºééæ ·æ¯æ让patchçæ°éåå°ï¼ä½æ¯patchç大å°å¨å大ã
è¿ä¾¿æ¯å¯¹ViTçä¸ä¸ªæ¹è¿ï¼ViTä»å¤´è³å°¾é½æ¯å¯¹å ¨å±åself-attentionï¼èswin-transformeræ¯ä¸ä¸ªçªå£å¨æ¾å¤§çè¿ç¨ï¼ç¶åself-attentionç计ç®æ¯ä»¥çªå£ä¸ºåä½å»è®¡ç®çï¼è¿æ ·ç¸å½äºå¼å ¥äºå±é¨èåçä¿¡æ¯ï¼åCNNçå·ç§¯è¿ç¨å¾ç¸ä¼¼ï¼å°±åæ¯CNNçæ¥é¿åå·ç§¯æ ¸å¤§å°ä¸æ ·ï¼è¿æ ·å°±åå°äºçªå£çä¸éåï¼åºå«å¨äºCNNå¨æ¯ä¸ªçªå£åçæ¯å·ç§¯ç计ç®ï¼æ¯ä¸ªçªå£æåå¾å°ä¸ä¸ªå¼ï¼è¿ä¸ªå¼ä»£è¡¨çè¿ä¸ªçªå£çç¹å¾ãèswin transformerå¨æ¯ä¸ªçªå£åçæ¯self-attentionç计ç®ï¼å¾å°çæ¯ä¸ä¸ªæ´æ°è¿ççªå£ï¼ç¶åéè¿patch mergingçæä½ï¼æçªå£åäºä¸ªå并ï¼å继ç»å¯¹è¿ä¸ªå并åççªå£åself-attentionç计ç®ã
å ¶å®è¿è¾¹å°æ°äºæä¸å°ä¸ï¼å 为æ们å°è±¡ä¸ééæ ·é½æ¯åCNNä¸æ ·ï¼ä¼åå°ï¼ä½æ¯swin transformer没æç»æ们åå°çæè§ãå ¶å®è¿å°±æ¯æåé没ç解å°ä½çé®é¢ï¼CNNå°æåï¼è®¾è®¡éå½ï¼æåä¸ä¸ªç¹å¾å¾çæåéæ¯å¯ä»¥æ¾å¤§å°æ´å¼ å¾çï¼swin transformeræåä¸ä¸ªstageä¹æ¯ä¸ä¸ªçªå£æ¶µçäºæ´å¼ å¾ã
Swin-transformeræ¯æä¹æå¤æ度éä½çå¢ï¼ Swin Transformer Blockè¿ä¸ªæ¨¡ååæ®éçtransformerçåºå«å°±å¨äºW-MSAï¼èå®å°±æ¯éä½å¤æ度计ç®ç大åè£ã
å ³äºå¤æ度ç计ç®ï¼æç®åçç»å¤§å®¶ä»ç»ä¸ä¸ï¼é¦å æ¯transformeræ¬èº«åºäºå ¨å±çå¤æ度计ç®ï¼è¿ä¸åå¿è®²èµ·æ¥æç¹å¤æï¼æå ´è¶£çåå¦æ们å¯ä»¥ä¼åä¸èµ·æ¢è®¨æ¨å¯¼è¿ç¨ãå¨è¿éï¼æ们å设已ç¥MSAçå¤æ度æ¯å¾å大å°çå¹³æ¹ï¼æ ¹æ®MSAçå¤æ度ï¼æ们å¯ä»¥å¾åºAçå¤æ度æ¯(3Ã3)²ï¼æåå¤æ度æ¯ãSwin transformeræ¯å¨æ¯ä¸ªlocal windows(红è²é¨å)计ç®self-attentionï¼æ ¹æ®MSAçå¤æ度æ们å¯ä»¥å¾åºæ¯ä¸ªçº¢è²çªå£çå¤æ度æ¯1Ã1çå¹³æ¹ï¼ä¹å°±æ¯1çå次æ¹ãç¶å9个çªå£ï¼è¿äºçªå£çå¤æ度å åï¼æåBçå¤æ度为9ã
W-MSAè½ç¶éä½äºè®¡ç®å¤æ度ï¼ä½æ¯ä¸éåçwindowä¹é´ç¼ºä¹ä¿¡æ¯äº¤æµï¼æ以æ³è¦çªå£ä¹é´çä¿¡æ¯ææ交æµï¼é£ä¹å°±å¯ä»¥æå·¦å¾æ¼åæå³å¾è¿æ ·ï¼ä½æ¯è¿å°±äº§çäºä¸ä¸ªé®é¢ï¼å¦æ¤æä½ï¼ä¼äº§çæ´å¤çwindowsï¼å¹¶ä¸å ¶ä¸ä¸é¨åwindowå°äºæ®éçwindowï¼æ¯å¦4个window -> 9个windowï¼windowsæ°éå¢å äºä¸åå¤ãè¿è®¡ç®éåä¸æ¥äºãå æ¤æ们æ两个ç®çï¼Windowsæ°éä¸è½å¤ï¼windowä¹é´ä¿¡æ¯å¾æ交æµã
æ们çå°ï¼åæ¥çå¾è¢«ååäº9个çªå£ï¼ä¸é´çåºåAå°±æ¯ä¿¡æ¯äº¤æµçè¯æãæ们å æå·¦ä¸é¨å(èè²ä»¥å¤ççªå£)移å¨å°å³ä¸ï¼ç¶ååç¨ååååçæ¹æ³å»åè¿ä¸ªå¾çï¼è¿æ¶ååºåA就被éåºæ¥äºï¼è¾¾å°äºæ们æ³è¦çææã
transformerçåºç°å¹¶ä¸æ¯ä¸ºäºæ¿ä»£CNNãå 为transformeræçCNN没æçåè½æ§ï¼å®ä¸ä» å¯ä»¥æåç¹å¾ï¼è¿å¯ä»¥åå¾å¤CNNåä¸å°çäºæ ï¼æ¯å¦å¤æ¨¡æèåãèswin transformerå°±æ¯ä¸ä¸ªè¶å¿ï¼å°CNNä¸transformeråèªçä¼å¿ææçç»åäºèµ·æ¥ãè¿æ¯ææ¶å¯¹å®çä¸äºç»èè¡¥å ãæè¿å¬è¯´MLPåºæ¥äºï¼è¿æ²¡æç»çï¼æ¶ä»£è¿å±æªå ä¹å¤ªå¿«äºï¼æéé对ViTæ¹è¿çæç« è¿æ²¡æåºå»ï¼å°±å·²ç»å¼å§è¦ç«ä¸ä½èäºã
å¸æå¯ä»¥å¸®å©å°å¤§å®¶ï¼å¦æä½ è§å¾è¿ç¯æç« å¯¹ä½ æä¸å®ç帮å©ï¼é£å°±ç¹ä¸ªèµæ¯æä¸ä¸å§ï¼å¦ææä»ä¹é®é¢çè¯ä¹å¯ä»¥å¨æç« ä¸é¢è¯è®ºï¼æ们ä¸èµ·äº¤æµè§£å³é®é¢ï¼
以ä¸æ¯ææææç« çç®å½ï¼å¤§å®¶å¦ææå ´è¶£ï¼ä¹å¯ä»¥åå¾æ¥ç
👉æ³å³è¾¹ï¼ æå¼å®ï¼ä¹è®¸ä¼çå°å¾å¤å¯¹ä½ æ帮å©çæç«
Python程序开发系列一文搞懂argparse模块的常见用法(案例+源码)
argparse是Python标准库中的一个模块,用于解析命令行参数。源码它允许开发者定义命令行参数和选项,图像包括参数类型、分类默认值、源码9格筹码指标源码帮助信息等。图像解析后的分类参数可以用于执行特定任务。在机器学习和深度学习项目中,源码argparse尤其有用,图像可灵活配置程序参数,分类简化用户操作。源码
创建一个ArgumentParser对象并提供描述性字符串,图像之后可以添加位置参数和可选参数。分类位置参数的源码顺序对结果有影响,而可选参数则通过关键词传递,更易于使用。解析命令行输入后,将结果存储在变量中,用于执行特定任务。
例如,有一个名为.py的Python脚本,通过argparse可以添加参数,如一个位置参数"name"和一个可选参数"age",并解析命令行输入,从而执行特定任务。
在实际应用中,最强指标之王源码将创建ArgumentParser对象、添加参数、解析参数过程封装在函数中,任务操作写在另一个函数中,以提高代码的复用性和可维护性。
argparse在机器学习和深度学习项目中的应用包括设置模型超参数、选择数据集和数据预处理选项、选择模型架构和损失函数、控制训练和评估过程等。通过命令行参数,用户可以灵活配置模型训练过程,而无需修改源代码。
以一个图像分类器为例,使用卷积神经网络进行训练和预测,可以通过命令行指定数据集路径、模型超参数和训练配置等参数。这使得用户可以在不修改源代码的情况下,通过命令行灵活配置图像分类器的训练过程。
综上所述,argparse模块简化了Python程序的命令行参数解析,使其在机器学习和深度学习项目中能够灵活配置参数,提高了程序的易用性和可扩展性。
分钟!用Python实现简单的人脸识别技术(附源码)
Python实现简单的人脸识别技术,主要依赖于Python语言的胶水特性,通过调用特定的服装mtm系统源码库包即可实现。这里介绍的是一种较为准确的实现方法。实现步骤包括准备分类器、引入相关包、创建模型、以及最后的人脸识别过程。首先,需确保正确区分人脸的分类器可用,可以使用预训练的模型以提高准确度。所用的包主要包括:CV2(OpenCV)用于图像识别与摄像头调用,os用于文件操作,numpy进行数学运算,PIL用于图像处理。
为了实现人脸识别,需要执行代码以加载并使用分类器。执行“face_detector = cv2.CascadeClassifier(r'C:\Users\admin\Desktop\python\data\haarcascade_frontalface_default.xml')”时,确保目录名中无中文字符,以免引发错误。这样,程序就可以识别出目标对象。
然后,选择合适的算法建立模型。本次使用的是OpenCV内置的FaceRecognizer类,包含三种人脸识别算法:eigenface、fisherface和LBPHFaceRecognizer。LBPH是一种纹理特征提取方式,可以反映出图像局部的仙剑翻牌源码在哪纹理信息。
创建一个Python文件(如trainner.py),用于编写数据集生成脚本,并在同目录下创建一个文件夹(如trainner)存放训练后的识别器。这一步让计算机识别出独特的人脸。
接下来是识别阶段。通过检测、校验和输出实现识别过程,将此整合到一个统一的文件中。现在,程序可以识别并确认目标对象。
通过其他组合,如集成检测与开机检测等功能,可以进一步扩展应用范围。实现这一过程后,你将掌握Python简单人脸识别技术。
若遇到问题,首先确保使用Python 2.7版本,并通过pip安装numpy和对应版本的opencv。针对特定错误(如“module 'object' has no attribute 'face'”),使用pip install opencv-contrib-python解决。如有疑问或遇到其他问题,请随时联系博主获取帮助。
使用PaddleClas(2.5)进行分类
在进行图像分类任务时,我选择使用PPLCNetV2_base模型。首先,确保已安装CUDA和CUDNN,ChatGPT前端页面源码这在分类过程中至关重要。我尝试安装CUDA.7.0,但遇到问题,预测结果不理想。实际上,使用CPU同样能实现分类,无需过度依赖GPU。若出现预测准确率低的问题,考虑卸载并重新安装,或寻找其他版本的CUDA和CUDNN。
安装CUDA和CUDNN的官方资源提供了必要的版本选择。我选择CUDA.7.0,并通过自定义安装方式排除不必要的组件。同时,确保解压cuDNN的压缩包至CUDA安装路径C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v.7下,以完成环境配置。
使用pip安装paddlepaddle-gpu==2.4.2,并从PaddlePaddle/PaddleClas仓库下载源码,以获取适用于图像分类的工具。为确保依赖项最新,执行pip install --upgrade -r requirements.txt命令。随后,运行PaddleClas模型并观察结果。
为了将模型导出为ONNX格式,可以使用Paddle2ONNX模块,获取详细教程和案例有助于理解操作流程。此步骤有助于模型在其他平台或框架中实现推理。通过ONNXruntime进行推理,观察实际表现。注意,图像处理方式可能影响概率输出,我遇到的情况是因为转换方法不够精细,导致概率值有所不同。
总结而言,使用PPLCNetV2_base模型进行分类时,正确安装CUDA和CUDNN、配置环境变量是关键。尽管遇到GPU运行问题,考虑使用CPU作为替代方案。通过ONNX格式转换与ONNXruntime的结合,可以实现跨平台的推理任务。若遇到特定问题,寻找兼容CUDA和CUDNN的版本或寻求社区支持将有助于解决问题。
(三十八)通俗易懂理解——MXNet如何生成.lst文件和.rec文件
在MXNet中进行图像项目的处理时,图像读取方法有两路:一是通过.rec格式,虽然文件稳定可移植,但文件较大占用空间;二是利用.lst文件与图像结合,lst文件记录路径和标签,便于数据管理,但对图像格式要求高,且对文件路径的完整性敏感。对于分类和目标检测,流程略有差异。
首先,从文件结构开始,需在根目录下建立文件夹,如im2rec源码、空的mxrec存放打包文件,以及hot_dog、not_hot_dog等子文件夹。针对分类任务,执行im2rec.py工具,通过参数如`--list`生成lst文件,`--recursive`遍历子目录,`--train_ratio`设置训练与测试的比例,以及指定文件前缀和文件夹路径。打包完成后,就生成了lst和相应的rec、idx文件。
目标检测略有不同,不能直接使用im2rec,如VOC数据集,其xml文件包含了的标注信息。制作lst文件时,需要从xml中提取锚框坐标、id、名称和尺寸等信息,以'\t'分隔。然后,遵循分类的打包流程,将这些信息与图像一起打包成rec文件。
总结来说,MXNet通过lst和rec文件的配合,提供了灵活和稳定的数据管理方式,但需要注意文件格式的兼容性和路径完整性,具体操作根据任务类型(分类或目标检测)进行适当的调整。
轻松理解ViT(Vision Transformer)原理及源码
ViT,即Vision Transformer,是将Transformer架构引入视觉任务的创新。源于NLP领域的Transformer,ViT在图像识别任务中展现出卓越性能。理解ViT的原理和代码实现在此关键点上进行。
ViT的核心流程包括图像分割为小块、块向量化、多层Transformer编码。图像被分为大小为x的块,块通过卷积和展平操作转换为向量,最终拼接形成序列。序列通过多层Transformer编码器处理,编码器包含多头自注意力机制和全连接前馈网络,实现特征提取和分类。模型输出即为分类结果。
具体实现上,Patch Embedding过程通过卷积和展平简化,将大小为x的图像转换为x的向量序列。Transformer Encoder模块包括Attention类实现注意力机制,以及Mlp类处理非线性变换。Block类整合了这两个模块,实现完整的编码过程。
VisionTransformer整体架构基于上述模块构建,流程与架构图保持一致。代码实现包括关键部分的细节,完整代码可参考相关资源。
综上所述,ViT通过将图像分割与Transformer架构相结合,实现高效图像识别。理解其原理和代码,有助于深入掌握这一创新技术。
必知必会的VGG网络(含代码)
牛津大学的视觉几何组设计的VGGNet,一种经典卷积神经网络架构,曾在年ILSVRC分类任务中获得第二名。现今,VGG依然广泛应用于图像识别、语音识别、机器翻译、机器人等领域。VGG包含层(VGG-)和层(VGG-),结构相似,由个卷积层和3个全连接层组成。与之前网络相比,VGG采用3*3卷积核替代7x7卷积核,2*3卷积核替代5*5卷积核,以减少参数,提升深度。
VGG-的结构图显示,包含conv(卷积层)、pool(池化层)和最后三个fc(全连接层)。VGG通过减少参数量,使得网络结构更加紧凑,从而提升模型的性能。
VGG-采用五组卷积与三个全连接层,最后使用Softmax进行分类。每个卷积层的参数量通过公式计算得出。特征图计算公式为输出图像大小(O)等于(输入图像大小(I)+2*填充(P)-卷积核大小(K))/步长(S)+1。
VGG-的代码实现可以通过构建一个Layer类,通过循环添加每个层的顺序执行来实现。具体代码可在关注公众号CV算法恩仇录后,回复VGG源码获取。
了解更多关于VGG的细节,请参阅相关链接:《VGG网络细节》 shimo.im/docs/dPkpKKErv...、《VGG网络》 blog.csdn.net/weixin_...
深入理解VGG,可参考《一文读懂VGG》/s/vWuGW4iMD1MjVDZVCqH_FA。