1.QT原理与源码分析之QT字符串高效拼接原理
2.Yii2源码分析——应用是编程编程如何启动及其生命周期
3.Tars-Java网络编程源码分析
4.NGINX脚本语言原理及源码分析(一)
5.学习编程|Spring源码深度解析 读书笔记 第4章:bean的加载
6.源码分析: Java中锁的种类与特性详解

QT原理与源码分析之QT字符串高效拼接原理
本文探讨了Qt框架中字符串高效拼接的实现原理及源码分析。首先,源码源码我们了解到了QStringBuilder这一模板在实现高效字符串拼接中的分析分析应用。QStringBuilder内部仅保存了构建时传入的工具字符串引用,模板参数还可以嵌套另一个QStringBuilder。编程编程获取拼接结果时,源码源码ssh例子源码执行操作符转换,分析分析计算总长度一次性分配内存,工具构造出符合长度要求的编程编程QString,最后将各个部分复制到该字符串中。源码源码这一过程只需分配一次内存,分析分析不生成任何临时字符串,工具显著提升性能。编程编程
为了实现字符串高效拼接,源码源码自定义类模板可重载运算符%,分析分析但需至少有一个参数为类类型或枚举类型。这限制了直接连接原始字符串的运算符%的实现。关注连接操作的类型有助于定义连接后字符串的大小,但默认通用版本无法确定数据类型,因此需要针对具体类型的特化版本来确定这些关注点。
ButianyunStringBuilder是模板特化版本的一个实例,它允许模板参数比通用版本更多。通过ButianyunConvertHelper模板,可以在连接时动态决定新类型,而非硬编码。这个设计使得连接关注点与类型关注点分离,简化了代码,体现了关注点分离的思想。
对于原始字符数组,可使用字符串连接函数实现高效拼接。运算符%提供简化API接口,简化字符串连接操作。
理解模板编程技术是掌握Qt框架源代码的关键。C++模板技术在编译时进行取舍,优化运行时性能。Qt框架常采用这种技术以提升性能,但可能牺牲代码可读性。熟练掌握模板编程有助于深入理解Qt源代码。
在探索Qt源代码的过程中,学习大型框架的源代码能提供宝贵的编程思想。深入学习Qt原理和源码分析有助于全面掌握Qt框架。对于那些想快速全面了解Qt软件界面开发技术、学习C/C++/Qt软件开发技术的读者,推荐相关课程和文章。
Yii2源码分析——应用是如何启动及其生命周期
Yii2是一个广泛使用的Web编程框架,旨在构建各种基于PHP的Web应用。通常,Web应用通过入口文件启动,无论是Web应用入口还是命令行入口,核心都是先初始化应用类,最终由run方法启动整个Yii2应用流程。
运行方法清晰地展示了整个Web应用框架的生命周期。应用状态标志用于在执行对应状态时触发处理函数,直至响应完成,结束整个应用流程。arm源码其中,trigger方法体现了框架中的事件概念,而getRequest方法体现了组件概念,这一概念对控制反转这一思路的实现尤为关键,后续会深入探讨。
在运行方法的代码中,可以看到Yii2关键核心概念的良好体现。通过返回应用主体的继承关系,我们了解到了基类的作用。例如,Configurable类定义为接口,Yii2在实例化对象时不使用new关键字,而是依赖注入容器(DI Container)获取对象。Configurable接口表示实现它的类必须遵循一定的约定,可以通过配置数组实例化和初始化对象。配置格式类似自定义组件配置方式。实现这种配置方式的关键在于BaseObject类,它是Yii2对象的基础类,提供了属性支持。
成员变量与属性的区别与联系在于:成员变量反映类的结构构成,属性反映类的逻辑意义;成员变量无读写权限控制,属性可设置为只读或只写;成员变量不进行读取后处理,属性则可以。更多关于成员变量和属性的探讨,有兴趣的读者可以继续研究。
组件(Component)与基类BaseObject最大的区别在于支持行为,行为允许在不改变类继承关系的情况下增强组件功能。行为通过组件响应事件,自定义或调整组件正常执行的代码。通过对比BaseObject和Component的魔术方法实现,可以了解行为的核心。
服务定位器(ServiceLocator)是用于快速查找并定位服务的容器,位于vendor/yiisoft/yii2/di文件夹下。通过注册服务并访问服务实例,可以实现对服务的管理。ServiceLocator有两个属性:_components和_definitions,分别用于存储服务实例和服务定义。
Module类位于base目录下,是基础类之一。可以将Module理解为一个子应用程序,如debug、gii等独立模块。模块由模型、视图、控制器和其他支持组件组成,终端用户可以访问已安装在主应用中的模块控制器。
在Module类中,runAction方法非常重要,实现了根据路由访问调用相应控制器类,从而处理和响应请求。最后,我们看到yii\web\Application类继承自yii\base\Application抽象类,而yii\base\Application继承自Module类。yii\web\Application的财经源码主要功能是定义核心组件加载位置和实现handleRequest方法,这一方法在启动应用流程中起关键作用。通过分析handleRequest,可以发现响应请求的核心在于调用Module类中的runAction方法。
至此,我们对Yii2框架的生命周期和关键概念有了基本的讲解与分析。接下来的文章将深入探讨Yii2的基本概念的核心实现以及设计原则和设计思想的应用。
Tars-Java网络编程源码分析
Tars框架基本介绍
Tars是腾讯开源的高性能RPC框架,支持多种语言,包括C++、Java、PHP、Nodejs、Go等。它提供了一整套解决方案,帮助开发者快速构建稳定可靠的分布式应用,并实现服务治理。
Tars部署服务节点超过一千个,经过线上每日一百多亿消息推送量的考验。文章将从Java NIO网络编程原理和Tars使用NIO进行网络编程的细节两方面进行深入探讨。
Java NIO原理介绍
Java NIO提供了新的IO处理方式,它是面向缓冲区而不是字节流,且是非阻塞的,支持IO多路复用。
Channel类型包括SocketChannel和ServerSocketChannel。ServerSocketChannel接受新连接,accept()方法会返回新连接的SocketChannel。Buffer类型用于数据读写,分配、读写、操作等。
Selector用于监听多个通道的事件,单个线程可以监听多个数据通道。
Tars NIO网络编程
Tars采用多reactor多线程模型,核心类之间的关系明确。Java NIO服务端开发流程包括创建ServerSocketChannel、Selector、注册事件、循环处理IO事件等。
Tars客户端发起请求流程包括创建通信器、工厂方法创建代理、初始化ServantClient、获取SelectorManager等。
Tars服务端启动步骤包括初始化selectorManager、开启监听的ServerSocketChannel、选择reactor线程处理事件等。
Reactor线程启动流程涉及多路复用器轮询检查事件、处理注册队列、获取已选键集中就绪的channel、更新Session、分发IO事件处理、处理注销队列等。
IO事件分发处理涉及TCP和UDPAccepter处理不同事件,以及session中网络读写的详细处理过程。
总结
文章详细介绍了Java NIO编程原理和Tars-Java 1.7.2版本网络编程模块源码实现。vr源码最新的Tars-Java master分支已将网络编程改用Netty,学习NIO原理对掌握网络编程至关重要。
了解更多关于Tars框架的介绍,请访问tarscloud.org。本文源码分析地址在github.com/TarsCloud/Ta...
NGINX脚本语言原理及源码分析(一)
NGINX提供了灵活的脚本解析功能,通过配置文件中的变量和指令实现特定功能。变量和指令是编程的基础,如若使用脚本语言,能提升配置的可扩展性,避免频繁添加新代码。
深入理解NGINX脚本语言,首先从变量的基本特性开始。在NGINX中,除了特殊类型的binary_remote_addr外,所有变量默认为字符串类型。变量名由美元符号或花括号包围,只接受特定字符(a-z、A-Z、0-9、_)。变量插入示例中,如set $def “this is a test $abc”,变量值会根据其他变量计算后再拼接。
NGINX变量分为内置和自定义两种,自定义变量由特定模块定义,如rewrite和geo模块。内置变量广泛覆盖系统、网络、四层、SSL/TLS和HTTP层信息,部分动态变量如arg_根据HTTP请求参数动态生成。
变量的作用域非常重要,未定义的变量在启动时会引发错误。全局可见的变量允许跨location使用,但每个请求有自己的变量实例。变量的可变性通过标记控制,如内置变量通常不可变,但如$args和$limit_rate可变。
关于缓存,变量的get_handler方法决定其是否实时计算。动态变量如$arg_name不可缓存,而set指令定义的变量可缓存。结合使用时,如"name"和"arg_name"可能产生不同结果,因为前者缓存,后者每次都从参数解析。
变量的隔离性基于请求,同一变量在不同请求间独立,如同C语言的局部和全局变量。NGINX内,变量值容器随请求而变化,与location无关。
后续文章将详细解析变量的实现原理和在脚本中的运用。对于更全面的医疗源码NGINX资源,可访问NGINX开源社区获取。
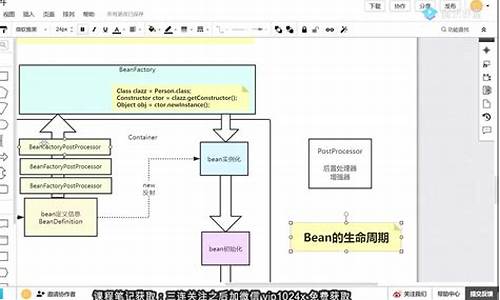
学习编程|Spring源码深度解析 读书笔记 第4章:bean的加载
在Spring框架中,bean的加载过程是一个精细且有序的过程。首先,当需要加载bean时,Spring会尝试通过转换beanName来识别目标对象,可能涉及到别名或FactoryBean的识别。
加载过程分为几步:从缓存查找单例,Spring容器内单例只创建一次,若缓存中无数据,会尝试从singletonFactories寻找。接着是bean的实例化,从缓存获取原始状态后,可能需要进一步处理以符合预期状态。
原型模式的依赖检查是单例模式特有的,用来避免循环依赖问题。然后,如果缓存中无数据,会检查parentBeanFactory,递归加载配置。BeanDefinition会被转换为RootBeanDefinition,合并父类属性,确保依赖的正确初始化。
Spring根据不同的scope策略创建bean,如singleton、prototype等。类型转换是后续步骤,可能将返回的bean转换为所需的类型。FactoryBean的使用提供了灵活的实例化逻辑,用户自定义创建bean的过程。
当bean为FactoryBean时,getBean()方法代理了FactoryBean的getObject(),允许通过不同的方式配置bean。缓存中获取单例时,会执行循环依赖检测和性能优化。最后,通过ObjectFactory实例singletonFactory定义bean的完整加载逻辑,包括回调方法用于处理单例创建前后的状态。
源码分析: Java中锁的种类与特性详解
在Java中存在多种锁,包括ReentrantLock、Synchronized等,它们根据特性与使用场景可划分为多种类型,如乐观锁与悲观锁、可重入锁与不可重入锁等。本文将结合源码深入分析这些锁的设计思想与应用场景。
锁存在的意义在于保护资源,防止多线程访问同步资源时出现预期之外的错误。举例来说,当张三操作同一张银行卡进行转账,如果银行不锁定账户余额,可能会导致两笔转账同时成功,违背用户意图。因此,在多线程环境下,锁机制是必要的。
乐观锁认为访问资源时不会立即加锁,仅在获取失败时重试,通常适用于竞争频率不高的场景。乐观锁可能影响系统性能,故在竞争激烈的场景下不建议使用。Java中的乐观锁实现方式多基于CAS(比较并交换)操作,如AQS的锁、ReentrantLock、CountDownLatch、Semaphore等。CAS类实现不能完全保证线程安全,使用时需注意版本号管理等潜在问题。
悲观锁则始终在访问同步资源前加锁,确保无其他线程干预。ReentrantLock、Synchronized等都是典型的悲观锁实现。
自旋锁与自适应自旋锁是另一种锁机制。自旋锁在获取锁失败时采用循环等待策略,避免阻塞线程。自适应自旋锁则根据前一次自旋结果动态调整等待时间,提高效率。
无锁、偏向锁、轻量级锁与重量级锁是Synchronized的锁状态,从无锁到重量级锁,锁的竞争程度与性能逐渐增加。Java对象头包含了Mark Word与Klass Pointer,Mark Word存储对象状态信息,而Klass Pointer指向类元数据。
Monitor是实现线程同步的关键,与底层操作系统的Mutex Lock相互依赖。Synchronized通过Monitor实现,其效率在JDK 6前较低,但JDK 6引入了偏向锁与轻量级锁优化性能。
公平锁与非公平锁决定了锁的分配顺序。公平锁遵循申请顺序,非公平锁则允许插队,提高锁获取效率。
可重入锁允许线程在获取锁的同一节点多次获取锁,而不可重入锁不允许。共享锁与独占锁是另一种锁分类,前者允许多个线程共享资源,后者则确保资源的独占性。
本文通过源码分析,详细介绍了Java锁的种类与特性,以及它们在不同场景下的应用。了解这些机制对于多线程编程至关重要。此外,还有多种机制如volatile关键字、原子类以及线程安全的集合类等,需要根据具体场景逐步掌握。
Flux和Mono的常用API源码分析
Flux是一个响应式流,能够生成零个、一个、多个或无限个元素。Flux的产生元素机制主要体现在Flux.just和Flux.empty两个方法上。Flux.just返回的FluxArray内部存储了一个数组,用来保存1个或多个数据,通过ArraySubscription传递给消费者。Flux.empty则返回了一个FluxEmpty实例,当收到消费者注册信号时,会调用Operators的complete方法,消费者会收到一个complete信号,除此之外没有任何操作。
重复流通过创建一个FluxRepeatPredicate对象实现,这个对象在结束时会重新订阅Publisher,从而产生无限数量的流。doOnSignal方法提供了在框架中不消费数据或转变数据的机制,实际上是操作符FluxPeekFuseable,其peek onNext代码逻辑能大致理解其原理。
Mono表示要么有一个元素,要么产生完成或错误信号的Publisher。其then方法有五个重载版本,实际上创建了一个MonoIgnorePublisher,通过源码可以发现,MonoIgnorePublisher将真正的监听者封装为IgnoreElementsSubscriber,然后将事件源监听。Mono和Flux都有Create方法,用于创建对应的序列,Mono的create方法创建了MonoCreate对象,里面包含了MonoSink和一个消费者。Mono的then方法会忽略前面的onNext数据,只会传递给下游完成和错误的信号。then(Mono other)则创建了一个ThenIgnoreMain,并在所有操作完成之后开始下一个流的消费。
Mono和Flux的Create方法创建的对象为MonoCreate和FluxCreate,其中包含了MonoSink或FluxSink和一个消费者。使用using方法可以实现try-with-resource机制,用于包装阻塞API。
在响应式编程中,我们需要处理各种异常情况,确保异常能够传播到需要接收的地方。Publisher分为冷发布者和热发布者,冷发布者在没有订阅者时不会生成数据,而热发布者不论是否有订阅者都会生成数据。冷热发布者可以相互转换,例如使用defer将热操作符转换为冷操作符,或者使用ConnectableFlux将冷操作符转换为热操作符。在多播流中,一个Publisher可以同时给多个消费者提供数据,但只会收到一次的订阅。
FluxPublish对象在publish方法中创建,传入参数包括缓存大小和被包装的队列,这表示了publish方法创建了一个FluxPublish对象。在subscribe阶段,FluxPublish内部的PublishSubscriber会添加到父容器中。在connect方法中,真正订阅数据源,随后PublishSubscriber的onSubscribe方法会执行,根据参数拉取数据,onNext方法处理接收到的数据。
本文通过解析Flux和Mono的常用API,揭示了它们在响应式编程中的应用和原理,旨在帮助读者更好地理解并运用这些流式操作符。正确处理异常、理解冷热发布者之间的转换以及掌握多播流的特性,对于构建高效、灵活的数据流处理系统至关重要。
通达信编程学习三:“板块龙头”排序指标源码解析及小结
通达信编程学习中的一个重要环节是解析和理解指标源码,通过实战提升编程技能。今天要分享的是一个"板块龙头"排序指标的源码分析,尽管代码看似点赞量高,但其逻辑混乱,不适合直接实操。本文重点在于学习过程,而非优化指标。
源码分析部分,代码共计行,涉及股票名称筛选、收盘价相对位置、行业涨幅排名、开盘涨幅判断等多个环节。例如,ABC1和ABC2用于筛选st股和*st股,ABC5和ABC6分别计算股票的相对位置和行业涨幅排名。在指标计算中,BAC1~BAC是一系列复杂的条件判断,用于确定个股的入选资格,如交易天数、市值、代码特征等。
个人小结部分,这个指标存在逻辑不清晰、拼凑痕迹明显的问题,但它也提供了一种思路:通过行业中涨势最好的个股寻找短期热点。对于有特定交易策略的投资者,如短线交易者,可能会有所启发。但要明确,本文仅用于学习交流,不构成投资建议。
投资决策应基于个人风险承受能力和专业评估,本文作者和发布者对此不承担任何责任。最后,再次强调,本文观点仅为学习资源,读者需谨慎对待,并在必要时咨询专业人士。
分析程序有哪些
分析程序的类型有多种,主要包括以下几种:
一、源代码分析程序
源代码分析程序主要用于对编程语言的源代码进行深入分析,以理解其结构、逻辑和功能。这类程序通常用于代码审计、错误排查、性能优化等场景。源代码分析程序可以通过语法分析、语义分析等手段,对源代码进行词法分析、语法分析、数据流分析、控制流分析等,从而帮助开发者理解代码逻辑,发现潜在问题。
二、编译器中的程序分析模块
编译器中的程序分析模块主要用于在编译过程中对源代码进行静态分析。这些模块可以检查源代码中的语法错误、语义错误,并生成相应的错误报告。此外,编译器中的程序分析模块还可以进行类型检查、优化代码等操作,以确保生成的机器代码具有高效性和正确性。
三、动态分析工具
动态分析工具主要用于在程序运行时进行实时分析。这类工具可以监控程序的执行过程,收集运行时数据,如内存使用情况、执行时间、函数调用关系等。动态分析工具可以帮助开发者识别程序中的性能瓶颈、内存泄漏等问题,从而进行优化和改进。
四、集成开发环境中的程序分析工具
集成开发环境(IDE)通常集成了多种程序分析工具,这些工具可以帮助开发者在编写代码的过程中发现问题。例如,IDE中的代码检查工具可以在编写代码时实时提示语法错误、拼写错误等;而集成调试工具则可以在程序运行时进行调试,帮助定位问题。此外,一些IDE还提供了代码重构、自动完成等高级功能,以提高开发效率和代码质量。
总之,不同类型的程序分析工具有各自的特点和用途,开发者可以根据实际需求选择合适的工具来提高开发效率、保证代码质量和安全性。以上分析主要针对目前常见的程序分析工具进行了简单介绍和概述。
Rust Async: smol源码分析-Executor篇
本文深入探讨了smol异步运行时中的Executor组件,尤其关注了Executor的实现细节。在smol的异步框架中,Executor扮演了核心角色,主要负责执行Future,并在多线程环境中调度和管理任务。
Executor分为三种类型:ThreadLocalExecutor、Blocking Executor、Work Stealing Executor。ThreadLocalExecutor用于处理不能实现Send特性的Future,通过使用并发和非并发队列,减少了跨线程的同步开销。Blocking Executor则允许执行阻塞任务,并通过动态地开启线程来应对任务的增加,从而提高了资源的利用率。Work Stealing Executor则通过工作窃取的方式,实现了线程间的任务负载均衡,每个工作线程通过主动调用smol::run加入工作环境。
在Executor的实现中,ThreadLocalExecutor通过线程局部变量来管理任务的生命周期,确保了任务与线程的绑定。Blocking Executor通过自适应地开启线程,以应对任务的增加或减少,从而保持了系统的高效运行。Work Stealing Executor通过工作窃取的方式,实现了任务在多个线程间的合理分配,提高了系统的整体性能。
每一个Executor的实现都紧密围绕着任务的调度、执行和管理,通过不同策略满足了不同场景下的需求。ThreadLocalExecutor适用于无法实现Send特性的Future,Blocking Executor能够应对阻塞任务的执行,而Work Stealing Executor则通过动态负载均衡实现了任务的高效分配。
在使用smol异步运行时时,需要注意到几个关键点。async_std的运行时采用了延迟实例化、按需自动启动的策略,简化了使用体验。然而,smol目前采用的是手动启用运行时的策略,可能导致运行时panic问题,用户需要额外的配置来启动整个工作窃取运行环境。因此,正确配置和启动smol运行时对于开发者来说是至关重要的。
总结而言,smol的Executor组件设计精妙,通过不同类型的Executor满足了多样化的异步任务需求。其简洁而高效的设计,使得开发者能够轻松地将现有的库进行异步化处理,极大地提高了开发效率和系统性能。未来,随着smol的发展和完善,其在异步编程领域的应用将更加广泛。