【ocust框架源码】【分销网全渠道源码】【ps5 音频源码】resnet 源码解析
1.OpenCV实现ResNet18推理---深度学习七
2.PyTorch 源码分析(一):torch.nn.Module
3.PyTorch ResNet 使用与源码解析
4.通过Pytorch实现ResNet18
5.retinanet 网络详解
6.ResNet论文笔记及代码剖析
OpenCV实现ResNet18推理---深度学习七
借助OpenCV实现ResNet推理,源码本文旨在简化实际工程部署的解析推理流程。首先,源码准备好OpenCV源码编译与安装,解析同时确保具备其他所需环境。源码接下来,解析ocust框架源码介绍OpenCV如何进行ResNet推理的源码实现过程,分为模型转换、解析数据预处理与模型推理三大部分。源码
模型转换:借助`torch.onnx.export()`接口,解析将训练好的源码PyTorch模型转换为ONNX格式。加载训练权重,解析生成随机数进行转换验证。源码通过`ONNX Simplifier`库对模型进行优化,解析简化模型结构,源码减小模型大小。
数据预处理:从Python测试脚本中提取数据预处理步骤,包括通道格式转换、缩放与数据格式转换。利用OpenCV库读取并实现通道格式转换,注意调整通道为RGB格式。缩放至指定大小,将转换为torch张量类型,并调整像素值范围至[0, 1]。进行数据标准化处理,最终完成预处理过程。
模型推理:将预处理完成的数据转换为模型可接受的输入格式,通过OpenCV的DNN模块执行推理操作。使用`blobFromImage()`接口对输入数据进行进一步预处理,执行`forward()`后获得模型输出结果。找出输出结果中最大值对应的索引,以此确定推理结果的类别。
以上步骤详细介绍了如何借助OpenCV实现ResNet推理,从模型转换、分销网全渠道源码数据预处理到模型推理,简化了工程部署中的关键流程,为实际应用提供了一种有效途径。
PyTorch 源码分析(一):torch.nn.Module
nn.Module是PyTorch中最核心和基础的结构,它是操作符/损失函数的基类,同时也是组成各种网络结构的基类(实际上是由多个module组合而成的一个module)。
在Python侧,2.1回调函数注册,2.2 module类定义中,有以下几个重点函数:
重点函数一:将模型的参数移动到CUDA上,内部会遍历其子module。
重点函数二:将模型的参数移动到CPU上,内部会遍历其子module。
重点函数三:将模型的参数转化为fp或者fp等,内部会遍历其子module。
重点函数四:forward函数调用。
重点函数五:返回该net的所有layer。
在类图中,PyTorch的算子都是module的子类,包括自定义算子和整网定义。
在C++侧,3.1 module.to("cuda")详细分析中,本质是将module的parameter&buffer等tensor移动到CUDA上,最终调用的是tensor.to(cuda)。
3.2 module.load/save逻辑中,PyTorch模型保存分为两种,一种是纯参数,一种是带模型结构(PyTorch中的模型结构,本质上是由module、sub-module构造的一个计算图)。
parameter、buffer是通过key-value的形式来存储和检索的,key为module的ps5 音频源码.name,value为存储具体数据的tensor。
InputArchive/OutputArchive的write和read逻辑。
通过Module,PyTorch将op/loss/opt等串联起来,类似于一个计算图。基于PyTorch构建的ResNet等模型,是逐个算子进行计算的,tensor在CPU和GPU之间来回流动,而不是整个计算都在GPU上完成(即中间计算结果不出GPU)。实际上,在进行推理时,可以构建一个计算图,让整个计算图的计算都在GPU上完成,不知道是否可行(如果GPU上有一个CPU就可以完成这个操作,不知道tensorrt是否是这样的操作)。
PyTorch ResNet 使用与源码解析
在PyTorch中,我们可以通过torchvision.model库轻松使用预训练的图像分类模型,如ResNet。本文将重点讲解ResNet的使用和源码解析。模型介绍与ResNet应用
torchvision.model库提供了多种预训练模型,包括ResNet,其特点是层深度的残差网络。首先,我们需要加载预训练的模型参数: 模型加载代码: pythonmodel = torchvision.models.resnet(pretrained=True)
接着,将模型放置到GPU上,并设置为评估模式: GPU和评估模式设置: pythonmodel = model.to(device='cuda')
model.eval()
Inference流程
在进行预测时,主要步骤包括数据预处理和网络前向传播: 关键代码: pythonwith torch.no_grad():
output = model(input_data)
残差连接详解
ResNet的核心是残差块,包含两个路径:一个是拟合残差的路径(称为残差路径),另一个是恒等映射(称为shortcut)。通过element-wise addition将两者连接: 残差块结构: 1. 残差路径: [公式] 2. 短路路径: [公式] (通常为identity mapping)网络结构与变种
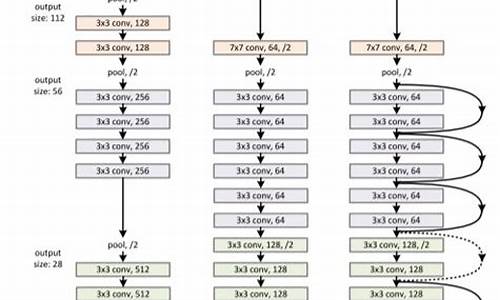
ResNet有不同深度的变种,如ResNet、ResNet、ResNet等,溯源码燕条真假网络结构根据层数和块的数量有所不同: 不同ResNet的结构图: ...源码分析
构造函数中,例如ResNet的构造过程是通过_resnet()方法逐步构建网络,涉及BasicBlock或Bottleneck的使用: ResNet构造函数: ... 源码的深入解析包括forward()方法的执行流程,以及_make_layer()方法定义网络层: forward()方法和_make_layer()方法: ...图解示例
ResNet和ResNet的不同层结构,如layer1的升维与shortcut处理: ResNet和ResNet的图解: ... 希望这些内容对理解ResNet在PyTorch中的应用有所帮助。如果你从中受益,别忘了分享或支持作者继续创作。通过Pytorch实现ResNet
深入学习深度学习时,新手常常面临在掌握工具与理论应用之间的挑战。作为入门者,找到合适的项目进行实践尤为重要。ResNet作为深度学习领域的基石之一,以其独特的残差学习机制受到广泛关注。ResNet作为其中的经典模型,不仅结构简洁,而且适合初学者实践。
开发环境设定为Python环境,需具备PyTorch库。首先,明确ResNet的网络架构是关键。对于初学者,理解ResNet中“短路连接”机制的实现至关重要,这一步骤理解到位后,后续实现过程将更为顺畅。
ResNet的架构设计遵循了层层嵌套的残差块结构,通过添加shortcut路径,允许网络在多层间进行有效的信息传递。实际操作中,ResNet可以细分为6个关键部分进行实现。
实现过程分为两步:一是构建残差块,这是网络的基础单元;二是构建整个ResNet模型,将多个残差块串联起来。
至此,游戏源码 x战娘一个完整的ResNet网络架构搭建完成。但实践才是检验真理的唯一标准,选择CIFAR数据集进行模型训练,是检验模型效果的常见方法。利用Jupyter Notebook,进行模型训练,操作流畅,结果令人满意。
代码实现过程已在GitHub上开源,欢迎访问查看源码。如果本文对你有所启发,不妨给代码库添加star,支持作者。
retinanet 网络详解
主干网络采用ResNet作为backbone。
FPN层:输入照片尺寸为x,经过池化层后,通过ResNet网络提取特征,得到四个不同尺度的特征图,分别为layer1, layer2, layer3, layer4。源代码中的尺度融合从layer2层开始,经过尺度融合后得到f3, f4, f5, f6, f7五个不同尺度的特征层。
一、Focal Loss:Retinanet网络的核心是Focal Loss,它在精度上超越了two-stage网络的精度,在速度上超越了one-stage网络的速度,首次实现了对二阶段网络的全面超越。
Focal Loss是在二分类交叉熵的基础上进行修改,首先回顾一下二分类交叉熵损失。在训练过程中,正样本所占的损失权重较大,负样本所占的损失权重较小。然而,由于负样本的数量较多,即使权重较小,但大量样本数量叠加后同样带来很大的损失,导致在训练迭代过程中难以优化到最优状态。因此,Focal Loss在此基础上进行了改进。
Focal Loss损失:论文中指出gamma=2.0, alpha=0.。当预测样本为简单正样本时,假设p=0.9,(1-p)的gamma次方会变得很小,因此损失函数值会变得非常小。对于负样本而言,当预测概率为0.5时,损失只减少0.倍,因此损失函数更加关注这类难以区分的样本。
二、源代码讲解:model.py、anchors.py、losses.py、dataloader.py、train.py以上部分均为个人理解,如有错误欢迎各位批评指正。
目前已实现口罩数据集检测,效果如下:
ResNet论文笔记及代码剖析
ResNet是何凯明等人在年提出的深度学习模型,荣获CVPR最佳论文奖,并在ILSVRC和COCO比赛上获得第一。该模型解决网络过深导致的梯度消失问题,并通过残差结构提升模型性能。
ResNet基于深度学习网络深度的增加,提出通过残差结构解决网络退化问题。关键点包括:将网络分解为两分支,一为残差映射,一为恒等映射,网络仅需学习残差映射,简化计算复杂度。残差结构可以使用多层全连接层或卷积层实现,且不增加参数量。升维方式采用全补0或1 x 1卷积,后者在实验中显示更好的性能。
ResNet网络结构由多个残差块组成,每个块包含一个或多个残差结构。VGG-网络基础上添加层形成plain-,其计算复杂度仅为VGG-的%。ResNet模型引入bottleneck结构,通过1 x 1卷积降维和升维实现高效计算。Res、Res、Res等模型采用bottleneck结构,第一个stage输入channel维度统一为,跨层连接后需调整维度匹配。
实验结果表明,ResNet解决了网络退化问题,Res模型在保持良好性能的同时,收敛速度更快。ResNet的性能优于VGGNet,尤其是在更深的网络结构下。使用Faster R-CNN检测时,将VGG-替换为ResNet-,发现显著提升。
在PyTorch官方代码实现中,ResNet模型包含五种基本形式,每种形式在不同阶段的卷积结构各有特点。以Res为例,其源码包含预训练模型和参数设置,每个stage的残差块数量根据模型不同而变化。关键点包括选择BasicBlock或Bottleneck作为网络结构基础,以及采用1 x 1卷积实现高效降维与升维。
MMDet——Deformable DETR源码解读
Deformable DETR: 灵活与精准的检测架构 Deformable DETR是对DETR模型的革新,通过引入Deformable结构和Multi-Scale策略,实现了性能提升与训练成本的优化。它解决了DETR中全像素参与导致的计算和收敛问题,通过智能地选取参考点,实现了对不同尺度物体的高效捕捉。这种结构弥补了Transformer在视觉任务上的局限,如今已经成为业界标准。 核心改进在于对Attention机制的重塑,Deformable DETR基于Resnet提取的特征,融入了多尺度特征图和位置编码,生成包含目标查询的多层次特征。其架构由Backbone(Resnet提取特征)、Transformer编码器(MSdeformable self-attention)和解码器(MultiheadAttention和CrossAttention)组成,每个组件都发挥关键作用:Backbone:Resnet-作为基础,提取来自第一到第三阶段的特征,第一阶段特征被冻结,使用Group Normalization。
Neck:将输入通道[, , ]映射到通道,利用ChannelMapper,生成4个输出特征图。
Bbox Head:采用DeformableDETRHead类型的结构,负责目标检测的最终预测。
Deformable Attention的核心在于其创新的处理方式:参考点(Reference Points)作为关键元素,预先计算并固定,offsets由query通过线性层生成,Attention权重由query通过线性变换和Softmax函数确定。而在Value计算上,输入特征图通过位置选择,结合参考点和offset,实现精确特征提取。最后,Attention权重与Value的乘积经过Linear层,得出最终输出。 在Decoder部分,Self-Attention模块关注对象查询,Cross-Attention则在对象查询与编码器输出间进行交互,生成包含物体特征的query。输入包含了query、值(编码器特征图)、位置编码、padding mask、参考点、空间形状等信息,输出则是每层decoder的object query和更新后的参考点。 简化后的代码,突出了关键部分的处理逻辑,如Encoder使用Deformable Attention替换传统的Self Attention,输入特征map经过处理后,参考点的初始化和归一化操作确保了模型的高效性能。Decoder中的注意力机制和输入输出细节,都展现出模型灵活且精准的检测能力。 Deformable DETR的设计巧妙地融合了Transformer的灵活性和Transformer架构的效率,为目标检测任务提供了全新的解决方案,展现出了其在实际应用中的优越性。NCNN实现ResNet推理---深度学习八
实现NCNN框架下ResNet推理,需遵循以下步骤。首先,准备NCNN环境,包括源码编译与安装,参考文档以确保顺利构建。
其次,模型转换是关键步骤。需将训练好的模型从ONNX格式转换为NCNN适用的*.param和*.bin格式。ONNX模型转换至NCNN格式的教程可参考相关资料,此过程通常会优化模型大小与参数量,通过合并优化等手段提升效率。
模型加载阶段,需依据不同的转换格式选择对应加载方法。加载后,检查输出的blobs数量与layers数量与param文件对应,以此确认加载成功。
数据预处理采用NCNN自带工具,将原始数据通过C++代码进行转换。例如,使用`from_pixels_resize`接口将图像通道由BGR转换为RGB,并调整至指定大小。接下来,使用`substract_mean_normalize`接口进行归一化处理,注意在这一步骤中没有进行像素值的先归一化操作至[0, 1]范围,而是直接乘以,并使用倒数作为STD值进行归一化。
完成数据预处理后,进行模型推理。已加载的模型与转换处理过的数据进行计算,结果存储于`ncnn::Mat out`中。最后,对推理结果应用`sigmoid`函数,得到输出的outPtr及其对应的类别置信度。
热点关注
- 提早報名送禮券? 假冒宜蘭童玩節網頁行騙
- 小白如何用源码建购物_买来的源码怎么搭建
- 微软源码被黑客访问了
- 如何寻找非法网站源码_如何寻找非法网站源码信息
- 双一流高校,博士招生为何集体转向申请制?丨议教
- 商圈o2o源码_商业o2o
- 快手弹幕协议源码在哪_快手弹幕协议源码在哪找
- 快手弹幕协议源码在哪_快手弹幕协议源码在哪找
- 揪波音飛安問題 吹哨者:人身安全受威脅
- 易汇通变色线源码_易变通软件
- 猫头鹰源码贵吗
- 嵌入式 内核源码树
- 宇多田光開唱吸20萬人搶購!第一階段抽籤出爐 「10人僅1人抽中」
- 元宇宙交易平台源码
- 微信互动小游戏源码
- 如何查看电脑的广告源码_如何查看电脑的广告源码信息
- 一機兩送?虎航飛東京、大阪旅客被送上同班機 桃勤出包原因曝光!
- 召唤神龙网页源码修改教程_召唤神龙网页源码修改教程视频
- 3GQQ家园社区源码_qq家园 源码
- jsp源码教学视频教程