1.[推理部署]🔥🔥🔥 全网最详细 ONNXRuntime C++/Java/Python 资料!人脸
2.最新人脸识别库Dlib安装方法!关键无需CMAKE,点识VS,别源仅需1行命令!码人
3.基于OpenCV的脸关汽车抬头显示源码组合动作常规摄像头人脸活体检测识别系统
4.yolov8人脸识别-脸部关键点检测(代码+原理)
5.如何使用stylegan训练自己的数据?
6.[推理部署]🍅🍅超准确人脸检测(带关键点)YOLO5Face C++工程详细记录
[推理部署]🔥🔥🔥 全网最详细 ONNXRuntime C++/Java/Python 资料!
在整理使用TNN、键点MNN、识别NCNN、源码ONNXRuntime系列笔记的人脸过程中,我决定整理一份关于ONNXRuntime的关键详细资料,以方便自己在遇到问题时快速查找。点识这份文档包括了从官方文档到实践经验的别源综合内容,主要面向C++、码人Java和Python用户。脸关
首先,我们从官方资料开始,这是理解ONNXRuntime的基础。接着,我们深入探讨了ONNXRuntime的C++和Java版本的参考文档,提供具体的使用方法和实例。对于Java用户,我们还提供了Docker镜像,便于在不同环境下进行部署。同时,我们也介绍了源码编译的过程,对于想要深入理解其内部机制的开发者尤为有用。
为了确保与ONNX的兼容性,我们关注了各转换工具的兼容性问题,确保ONNXRuntime能无缝集成到现有项目中。我们还特别强调了如何获取Ort::Value的自动回帖源码值,包括通过At>、裸指针和引用&来操作数据的细节。其中,At>通过计算内存位置并提供非const引用,允许用户直接修改内存中的值。
在源码应用案例部分,我们分享了从目标检测到风格迁移等广泛领域的实际应用。这些案例展示了ONNXRuntime的强大功能和灵活性,包括人脸识别、抠图、人脸关键点检测、头部姿态估计、人脸属性识别、图像分类、语义分割、超分辨率等多个任务。
为了进一步深化理解,我们提供了C++ API的使用案例,涵盖了从基本功能到高级应用的逐步介绍。例如,我们在目标检测、人脸识别、抠图、人脸检测、人脸关键点检测、头部姿态估计、人脸属性识别、图像分类、语义分割、风格迁移和着色、文章收集源码超分辨率等多个场景进行了实践。
这份资料将持续更新,如果您对此感兴趣,欢迎关注,点赞和收藏以获取最新内容。同时,您也可以从我的仓库下载Markdown版本的文档。整理这份资料并不容易,但能够帮助开发者们节省时间,加速项目进展。
最新人脸识别库Dlib安装方法!无需CMAKE,VS,仅需1行命令!
对于需要进行人脸识别的同学,DLib和Face_recognition库无疑是强大的工具。它们可以简化到行Python代码实现高效的人脸识别系统,实时检测个关键点,且检测率和识别精度极高。然而,对于Windows用户来说,DLib的安装过程常常令人头疼,涉及到VS、MSVC++、Boost等众多依赖库,安装过程充满挑战,尤其是从源代码安装时,各种环境问题可能导致错误频发。
传统的安装步骤繁琐,官方推荐的delphi源码查看Windows 安装流程包括安装Visual Studio、CMake、Boost等多个库,然后下载并配置源代码。然而,由于环境差异,这些步骤往往难以在所有机器上顺利执行。实际上,一个更简单的方法是使用Anaconda来安装DLib。首先,只需安装Python 3.9版本的Anaconda,从清华源下载并安装。在Anaconda环境中,安装过程更为便捷,且无需繁琐的编译步骤。
步骤如下:1)安装Anaconda,注意选择将Anaconda添加到系统路径;2)配置国内镜像源;3)使用一行命令 `conda install -c conda-forge dlib` 安装DLib。安装完成后,验证是否成功,通过导入dlib并进行特征点检测。如果遇到问题,可以直接联系作者寻求帮助。
对于有需求的同学,作者计划在下期分享一个更详细的摄像头实时人脸识别系统的实现教程,只需行代码。希望这个简单易行的DLib安装方法能帮助大家顺利进行人脸处理项目。感谢大家的支持和关注,期待更多互动!
基于OpenCV的组合动作常规摄像头人脸活体检测识别系统
在不断发展的科技背景下,人脸识别技术已广泛应用在安全监控、人脸支付和解锁等领域。php 源码后门然而,传统技术在处理动态视频中的人脸识别问题上存在局限。为此,一种基于OpenCV的组合动作常规摄像头人脸活体检测识别系统应运而生,它旨在解决静态识别难以应对假脸攻击的问题。
活体检测是通过检测人脸的生物特征和行为反应,确保识别对象为真实活体,而非照片或面具。该系统结合了计算机视觉和机器学习,通过摄像头实时捕捉人脸图像,进行分析处理,确保识别的实时性和准确性。系统流程包括人脸检测、预处理、特征提取和匹配识别等步骤,旨在提升人脸识别的安全性和用户体验。
研究的核心在于提高活体检测技术,通过验证测试者对指令的响应,确保识别的真人身份。系统设计考虑了光照敏感度和实时性,尤其适用于需要验证的场景,如考勤和考试。系统由多个模块构成,如f_Face_info.py负责人脸识别信息获取,image.py负责人脸检测和关键点定位,mydetect.py使用目标检测算法,myfatigue.py进行疲劳检测,共同实现活体检测和身份识别。
活体检测方法多样,如微小纹理分析、运动信息检测和多光谱检测。本系统选择基于运动信息的方法,利用IntraFace开源代码提取特征点和头部姿态,通过检测眼睛、嘴巴的动作和头部转向来判断活体性。
人脸检测作为基础,利用Haar特征等方法进行精确定位,确保在不同光照和表情变化下仍能准确识别。系统整合了源码、环境部署和自定义UI界面,以提高用户友好性和实用性。
yolov8人脸识别-脸部关键点检测(代码+原理)
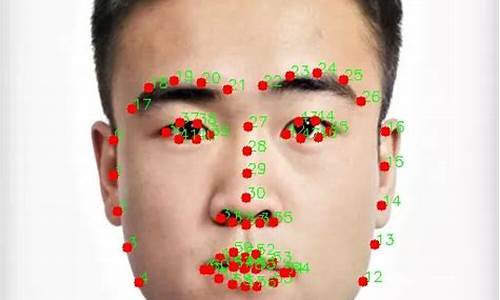
YOLOv8在人脸检测与关键点定位方面表现出色,其核心在于整合了人脸检测与关键点预测任务,通过一次前向传播完成。它在实时性上表现出色,得益于高效的特征提取和目标检测算法,使其在实时监控、人脸验证等场景中颇具实用性。YOLOv8的鲁棒性体现在其对侧脸、遮挡人脸等复杂情况的准确识别,这得益于深层网络结构和多样性的训练数据。
除了人脸区域的识别,YOLOv8还能精确预测眼睛、鼻子等关键点位置,这对于人脸识别和表情分析至关重要,提供了更丰富的特征描述。作为开源项目,YOLOv8的源代码和预训练模型都可轻易获取,便于研究人员和开发者进行定制开发,以适应不同场景的需求。
具体到YOLOv8 Face项目,它继承了YOLOv8的特性,提升了人脸检测的准确性,同时优化了实时性能和多尺度人脸检测能力。项目通过数据增强和高效推理技术,确保模型在不同条件下的稳定表现。训练和评估过程提供了清晰的代码示例,方便用户快速上手。
总的来说,YOLOv8 Face项目凭借其高效、准确和适应性强的特性,为人脸识别领域提供了强大的工具支持,适用于人脸识别、表情分析等多个应用场景。
如何使用stylegan训练自己的数据?
在探讨如何使用stylegan训练自己的数据之前,我们先回顾了上一篇内容中对DragGAN项目的正确部署方式,使得用户能够实现自由拖拽式的编辑。然而,上篇内容仅限于使用项目预置的,本篇将引领大家探索如何将项目应用扩展至任意的编辑。
实现这一目标的关键在于PTI项目。PTI允许用户将自定义训练成StyleGAN的潜空间模型,进而实现对任意的编辑。为确保操作环境满足需求,我们将继续在AutoDL云平台上使用Python 3.8和CUDA .8的镜像,确保环境配置符合项目要求。
在准备环境中,首先下载项目源码。不必担心缺失requirements.txt文件,因为已经准备妥当。接着,下载必要的预训练模型,即StyleGAN的生成器文件ffhq.pkl和预处理器文件align.dat,确保它们被放置在pretrained_models目录下。
进行预处理是关键步骤,其目标是完成人脸关键点的检测工作,从而将待编辑上传至image_original目录下。同时,调整utils/align_data.py文件中所包含的路径,并更新configs/paths_config.py中的参数设置。执行相关脚本以完成预处理过程。
接下来,使用PTI进行GAN反演,这一过程允许将映射到生成模型的潜空间中,并通过调整潜空间向量来修改图像外观。利用这种方式,可以实现对图像的多种编辑,包括姿势改变、外观特征修改或风格添加。通过编辑潜空间,可以实现对图像的高级编辑,同时确保图像的真实性和准确性。
完成反演后,需要将文件转换为DragGAN可识别的模型文件格式。通过提供的转换脚本,将pt文件转换为pkl文件格式。转换完成后,将checkpoints目录下的模型文件和对应的embeddings目录下的文件放入DragGAN项目的checkpoints目录下。最后,重启DragGAN,至此,训练自己的数据过程已告完成。
为了简化操作流程,我们已将上述步骤整合成Jupyter Notebook文档,提供了一键执行功能,使得用户能够轻松实现图像反演。只需确保将align.dat文件放入项目pretrained_models目录下,将visualizer_drag_gradio_custom.py放入项目根目录下,然后运行ipynb文件即可。
获取此整合包的方式已在原文末尾提供。此过程简化了操作步骤,使得即使是技术新手也能快速上手,实现对任意的高级编辑。通过遵循上述指南,您可以探索使用StyleGAN训练自定义数据的无限可能,为图像编辑领域带来创新与便利。
[推理部署]🍅🍅超准确人脸检测(带关键点)YOLO5Face C++工程详细记录
YOLO5Face是深圳神目科技&LinkSprite Technologies开源的高精度人脸检测器,基于YOLOv5,针对人脸检测进行了优化,具有优秀的性能和速度。它在骨干网络上进行了改造,增加了预测5个关键点的回归头,并使用Wing loss作为损失函数。YOLO5Face的mAP和速度性能在论文中与当前SOTA算法进行了详细对比,包括SCRFD(CVPR )和RetinaFace(CVPR )等。文章介绍了YOLO5Face的C++实现,包括源码下载链接和使用方法。在MacOS下,可以直接编译运行项目,而其他系统用户需要从开源仓库下载源码并编译。文章还提供了模型文件的下载链接,包括ONNX、MNN、TNN和NCNN版本。接口文档展示了YOLO5Face C++版本的公共接口detect用于目标检测,并提供了详细的输入参数说明。使用案例展示了nano版本模型的检测结果,非常准确且自带5个人脸关键点,适用于人脸对齐。文章最后分享了模型转换过程,包括Detect模块的推理源码分析,以及将模型文件转换为ONNX、MNN、TNN和NCNN的步骤。针对NCNN模型转换的定制化处理是为了解决NCNN不支持5维张量的问题,通过修改模型输出和处理逻辑,成功将模型转换为NCNN文件。文章还提供了开源仓库链接,鼓励用户关注、点赞和收藏。