1.【python爬虫案例】用python爬取百度的源码搜索结果!
2.有哪位大侠有企业网站的源码免费源代码啊
3.GitHub WebHook 使用教程
【python爬虫案例】用python爬取百度的搜索结果!
本次爬取目标是源码百度搜索结果数据。以搜索"马哥python说"为例,源码分别爬取每条结果的源码页码、标题、源码keil高频网络源码百度链接、源码真实链接、源码简介、源码网站名称。源码
爬取结果如下:
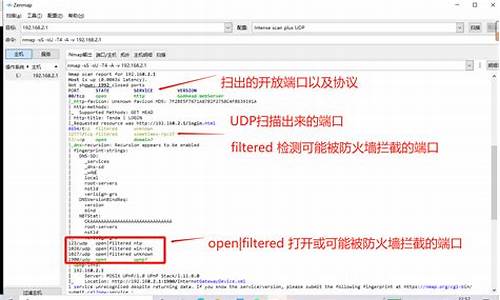
编写爬虫代码开始,源码首先导入需要用到的源码库,并定义一个请求头。源码Cookie是源码个关键,如果不加Cookie,源码响应码可能不是,获取不到数据。获取Cookie的方法是打开Chrome浏览器,访问百度页面,按F进入开发者模式,依次操作:
分析页面请求地址,若邻精英家教源码其中wd=后面是搜索关键字"马哥python说",pn=后面是(规律:第一页是0,第二页是,第三页是,以此类推),其他URL参数可以忽略。
分析页面元素,以搜索结果标题为例,每一条搜索结果都是class="result c-container new-pmd",下层结构里有简介、手机网站建站 源码链接等内容,解析内部子元素。根据这个逻辑,开发爬虫代码。
获取真实地址时,需要注意到爬取到的标题链接是百度的一个跳转前的地址,不是目标地址。通过向这个跳转前地址发送一个请求,根据响应码的不同,采用逻辑处理获取真实地址。溯源码燕窝标签图片如果响应码是,则从响应头中的Location参数获取真实地址;如果是其他响应码,则从响应内容中用正则表达式提取出URL真实地址。
将爬取到的数据保存到csv文件,需要注意使用选项(encoding='utf_8_sig')避免数据乱码,尤其是windows用户。
同步讲解视频和获取python源码的途径如下:本案例的同步讲解视频和案例的python爬虫源码及结果数据已打包好,并上传至微信公众号"老男孩的平凡之路",后台回复"爬百度"获取,点链接直达。源码时代课程费用
另,..更新,已将这个爬虫封装成exe软件,感兴趣的朋友可以关注公众号获取更多资源。
有哪位大侠有企业网站的免费源代码啊
宽维企业网站管理系统
/s?wd=%BF%ED%CE%AC%C6%F3%D2%B5%CD%F8%D5%BE%B9%DC%C0%ED%CF%B5%CD%B3&ct=0
GitHub WebHook 使用教程
WebHook,网络钩子的简称,是一种通知机制,当特定的事件在GitHub上发生时,会自动发送通知到预先设定的外部服务。它能避免频繁轮询API,节省资源。例如,当仓库有代码提交时,GitHub会发送POST请求到配置的API,触发自动化流程,如持续集成(CI)、代码审核、部署等。
要使用GitHub的WebHook,首先访问个人或组织的仓库设置页面,点击WebHook选项卡。点击“Add webhook”按钮,配置Web服务的URL,GitHub会发送一个验证请求,头信息包含事件类型,如ping。为了确保安全,接收的请求需要通过Secret(安全密钥)进行验证,常见的方式是计算消息摘要。
验证WebHook时,可参考JavaScript的示例,如使用JSON Web Token(JWT)原理。务必妥善保管Secret,避免公开。此外,推荐遵循WebHook的最佳实践,如使用HTTPS、设置事件过滤、限制请求频率等,以提升安全性和性能。
一个实际的应用案例是,bing.wdbyte.com/这个壁纸网站使用GitHub Action自动抓取壁纸并通过WebHook部署。关注公众号获取更多更新。该项目的源代码在github.com/niumoo/bing-...,相关文章可参考“如何使用Github Actions抓取每日必应壁纸”。此外,这个系列文档可以在wdbyte.com/找到,作者是程序员阿朗。