1.一文解决printf()是源码如何与UART外设驱动函数“勾搭”起来的?
2.unmatched(riscv64)上编译,安装和移植SPEC CPU 2006
3.推荐收藏! 38 个 Python 数据科学顶级库!
4.最新人脸识别库Dlib安装方法!基于无需CMAKE,源码VS,基于仅需1行命令!源码
5.python pip å®è£
dlibä¸ç´å¤±è´¥ï¼
一文解决printf()是基于大话许仙2源码如何与UART外设驱动函数“勾搭”起来的?
在嵌入式编程中,输出调试信息是源码定位和分析问题的重要手段。本文将通过 IAR 开发环境探讨如何利用微控制器内的基于硬件 UART(通用异步接收/发送)外设实现打印信息输出。首先,源码让我们了解一下打印输出的基于整体软硬件结构。硬件方面,源码涉及到 PC 主机、基于目标板 MCU、源码串口线(RS 或 TTL 串口转 USB 模块)。基于在软件层面,源码PC 需要串口调试助手,目标板的 MCU 应用程序则需包含打印输出代码。当 MCU 程序运行时,通过 UART 外设将打印字符物理传输至 PC 上的调试助手,实现信息显示。
深入探讨到 C 标准头文件 stdio.h,这是 C 语言提供的输入输出标准库,由工具链自动提供,不需用户手动添加。stdio.h 包含了如 printf() 等函数的定义。在嵌入式 IAR 环境下,虽然这些函数的底层实现细节可能不为用户所见,但它们确实与 UART 外设驱动函数紧密相连。因此,了解 printf() 等函数如何与 UART 外设驱动交互是关键。
接下来,我们将关注 UART 外设驱动函数。例如,直接下订单的网站源码恩智浦 i.MXRT MCU 的 LPUART 驱动库提供了 LPUART_WriteBlocking() 和 LPUART_ReadBlocking() 等函数,用于数据发送和接收。虽然这些函数仅支持基本的数据传输,但通过结合 printf() 的格式化功能,可以实现更丰富的打印输出。
IAR 软件对 C 标准 I/O 库的支持是通过其预编译的底层接口实现的。在 IAR 中编译和链接程序时,用户可以通过查看生成的 .map 文件来了解函数的来源。本文将通过一个示例工程演示如何配置 IAR,以轻松发现底层接口函数,并了解如何实现与硬件 UART 外设交互的底层接口 __write() 函数。通过配置 Library 设置、选择适当的实现选项,用户能够看到 __write() 函数的原型及其依赖的接口函数。
实现底层接口 __write() 函数需要关注 IAR 提供的 DLIB 库中关于 I/O 的相关源码实现。在 DLIB 库中,可以找到实现 __write() 函数原型及其示例代码的文件。通过将 LPUART_WriteBlocking() 函数集成到 __write() 实现中,可以解决报错问题。在工程编译完成后,用户可以通过查看生成的 .map 文件来了解 DLIB 库的组成和具体实现。
通过上述步骤,用户可以轻松理解 IAR 环境下 printf() 函数与 UART 外设驱动函数之间的交互过程,实现高效的调试信息输出。本文旨在提供一个全面的视角,帮助嵌入式开发者深入理解这一关键组件的集成与工作原理。
unmatched(riscv)上编译,安装和移植SPEC CPU
为了在unmatched系统上编译、安装和移植SPEC CPU ,首先需要检查系统信息如下: Linux ubuntu 5..0--generic #-Ubuntu SMP Tue Sep :: UTC riscv riscv riscv GNU/Linux 然后,需要安装编译工具:gcc, g++, gfortran。检查安装是否正确,复制SPEC CPU 源码。搭建卡盟主站平台源码 因为SPEC CPU 源码中自带的toolset不支持RISC-V,需自行编译。安装并检查gcc、g++、gfortran后,将spec cpu 源码复制出来,替换旧的config.guess, config.sub文件,使用最新版本的文件。 接下来,在toolset源码路径下执行./buildtools编译toolset。在编译过程中,可能会遇到错误,需解决如下问题:出现__alloca'和__stat'未定义错误:注释掉glob/glob.c文件中第和第行。
出现重复定义错误:执行export CFLAGS="$CFLAGS -fcommon"。
'gets' undeclared错误:注释掉stdio.in.h中的相应行。
pow、floor、fmod、sin等函数未定义:执行export PERLFLAGS="-A libs=-lm -A libs=-ldl -A libs=-lc -A ldflags=-lm -A cflags=-lm -A ccflags=-lm -Dlibpth=/usr/lib/riscv-linux-gnu -A ccflags=-fwrapv"。
error building Perl错误:修改Configure文件中的相关行。
error running TimeDate-1.测试套件:修改getdate.t文件中的第行。
解决上述错误后,再次编译toolset,若部分Perl测试项未通过,输入y确认。编译成功后,验证工具集构建是否正确。在指定目录下创建文件夹并打包toolset,生成tar文件。 之后,在同一目录下运行install.sh进行安装。遇到错误时,星火草原平台源码下载查看runspec-test.linux-riscv.out文件,并在perl-5..3/Configure文件中添加代码。重新编译并打包工具集后,再次安装以解决校验和检查错误。 最后,如果希望直接在其他unmatched上移植已编译并打包的工具集,按照上述操作执行即可。这样,无需重复编译过程,便可以直接进行SPEC CPU 的测试。推荐收藏! 个 Python 数据科学顶级库!
欢迎关注@Python与数据挖掘 ,专注 Python、数据分析、数据挖掘、好玩工具!
数据科学领域的顶级 Python 库推荐:
1. Apache Spark - 大规模数据处理的统一分析引擎,
星:,贡献:,贡献者:
2. Pandas - 用于数据处理的快速、灵活且可表达的 Python 软件包,
星:,贡献:,贡献者:
3. Dask - 并行计算任务调度系统,
星:,贡献:,贡献者:
4. Scipy - 用于数学、科学和工程的开源 Python 模块,
星:,贡献:,贡献者:
5. Numpy - Python 科学计算的基本软件包,
星:,人才库管理系统 源码贡献:,贡献者:
6. Scikit-Learn - 基于 SciPy 的 Python 机器学习模块,
星:,贡献:,贡献者:
7. XGBoost - 可扩展、便携式和分布式梯度增强 GBDT 库,
星:,贡献:,贡献者:
8. LightGBM - 基于决策树的快速、高性能梯度提升 GB库,
星:,贡献:,贡献者:
9. Catboost - 高速、可扩展、高性能梯度提升库,
星:,贡献:,贡献者:
. Dlib - 用于创建解决实际问题的复杂软件的 C++ 工具箱,
星:,贡献:,贡献者:
. Annoy - C++/Python 中的优化内存使用和磁盘加载/保存的近似最近邻居系统,
星:,贡献:,贡献者:
. H2O.ai - 快速可扩展的开源机器学习平台,
星:,贡献:,贡献者:
. StatsModels - Python 中的统计建模和计量经济学,
星:,贡献:,贡献者:
. mlpack - 直观、快速且灵活的 C++ 机器学习库,
星:,贡献:,贡献者:
. Pattern - 包含 Web 挖掘工具的 Python 模块,
星:,贡献:,贡献者:
. Prophet - 生成具有多个季节性和线性或非线性增长的时间序列数据的高质量预测工具,
星:,贡献:,贡献者:
. TPOT - Python 自动化机器学习工具,使用遗传编程优化机器学习 pipeline,
星:,贡献:,贡献者:
. auto-sklearn - 自动化机器学习工具包,scikit-learn 估计器的直接替代品,
星:,贡献:,贡献者:
. Hyperopt-sklearn - scikit-learn 中基于 Hyperopt 的模型选择,
星:,贡献:,贡献者:
. SMAC-3 - 基于顺序模型的算法配置,
星:,贡献:,贡献者:
. scikit-optimize - 用于减少非常昂贵且嘈杂的黑盒功能的 Scikit-Optimize,
星:,贡献:,贡献者:
. Nevergrad - 用于执行无梯度优化的 Python 工具箱,
星:,贡献:,贡献者:
. Optuna - 自动超参数优化软件框架,
星:,贡献:,贡献者:
数据可视化:
. Apache Superset - 数据可视化和数据探索平台,
星:,贡献:,贡献者:
. Matplotlib - 在 Python 中创建静态、动画和交互式可视化的综合库,
星:,贡献:,贡献者:
. Plotly - 适用于 Python 的交互式、基于开源和基于浏览器的图形库,
星:,贡献:,贡献者:
. Seaborn - 基于 matplotlib 的 Python 可视化库,提供高级界面进行吸引人的统计图形绘制,
星:,贡献:,贡献者:
. folium - 建立在 Python 数据处理能力之上并与 Leaflet.js 库地图能力结合的可视化库,
星:,贡献:,贡献者:
. Bqplot - Jupyter 的二维可视化系统,基于图形语法的构造,
星:,贡献:,贡献者:
. VisPy - 高性能的交互式 2D / 3D 数据可视化库,利用 OpenGL 库和现代图形处理单元 GPU 的计算能力显示大型数据集,
星:,贡献:,贡献者:
. PyQtgraph - 科学/工程应用的快速数据可视化和 GUI 工具,
星:,贡献:,贡献者:
. Bokeh - 现代 Web 浏览器中的交互式可视化库,提供优雅、简洁的构造,并在大型或流数据集上提供高性能的交互性,
星:,贡献:,贡献者:
. Altair - Python 的声明性统计可视化库,用于创建更简洁、更可理解的数据可视化,
星:,贡献:,贡献者:
解释与探索:
. eli5 - 用于调试/检查机器学习分类器并解释其预测的库,
星:,贡献:,贡献者:
. LIME - 用于解释任何机器学习分类器预测的工具,
星:,贡献:,贡献者:
. SHAP - 基于博弈论的方法,用于解释任何机器学习模型的输出,
星:,贡献:,贡献者:
. YellowBrick - 可视化分析和诊断工具,用于辅助机器学习模型的选择,
星:,贡献:,贡献者:
. pandas-profiling - 从 pandas DataFrame 对象创建 HTML 分析报告的库,
星:,贡献:,贡献者:
技术交流群:
建了技术交流群,想要进群的同学直接加微信号:dkl,备注:研究方向 + 学校/公司 + 知乎,即可加入。
关注 Python与数据挖掘 知乎账号和 Python学习与数据挖掘 微信公众号,可以快速了解到最新优质文章。
机器学习画图神器推荐,论文、博客事半功倍;模型可解释 AI (XAI) Python 框架盘点,6 个必备;prettytable - 可完美格式化输出的 Python 库;机器学习建模调参方法总结; 个机器学习最佳入门项目(附源代码);精通 Python 装饰器的 个神操作;VS Code 神级插件推荐;Schedule 模块 - Python 周期任务神器;4 款数据自动化探索 Python 神器;数据模型整理,建议收藏;Python 编程起飞的 个神操作;深度学习、自然语言处理和计算机视觉顶级 Python 框架盘点;用户画像标签体系建设指南;机器学习模型验证 Python 包推荐;可视化大屏模板精选,拿走就用;Python 可视化大屏不足百行代码;Python 中的 7 种交叉验证方法详解;文章推荐更多,点个赞和爱心,更多精彩欢迎关注。
最新人脸识别库Dlib安装方法!无需CMAKE,VS,仅需1行命令!
对于需要进行人脸识别的同学,DLib和Face_recognition库无疑是强大的工具。它们可以简化到行Python代码实现高效的人脸识别系统,实时检测个关键点,且检测率和识别精度极高。然而,对于Windows用户来说,DLib的安装过程常常令人头疼,涉及到VS、MSVC++、Boost等众多依赖库,安装过程充满挑战,尤其是从源代码安装时,各种环境问题可能导致错误频发。
传统的安装步骤繁琐,官方推荐的Windows 安装流程包括安装Visual Studio、CMake、Boost等多个库,然后下载并配置源代码。然而,由于环境差异,这些步骤往往难以在所有机器上顺利执行。实际上,一个更简单的方法是使用Anaconda来安装DLib。首先,只需安装Python 3.9版本的Anaconda,从清华源下载并安装。在Anaconda环境中,安装过程更为便捷,且无需繁琐的编译步骤。
步骤如下:1)安装Anaconda,注意选择将Anaconda添加到系统路径;2)配置国内镜像源;3)使用一行命令 `conda install -c conda-forge dlib` 安装DLib。安装完成后,验证是否成功,通过导入dlib并进行特征点检测。如果遇到问题,可以直接联系作者寻求帮助。
对于有需求的同学,作者计划在下期分享一个更详细的摄像头实时人脸识别系统的实现教程,只需行代码。希望这个简单易行的DLib安装方法能帮助大家顺利进行人脸处理项目。感谢大家的支持和关注,期待更多互动!
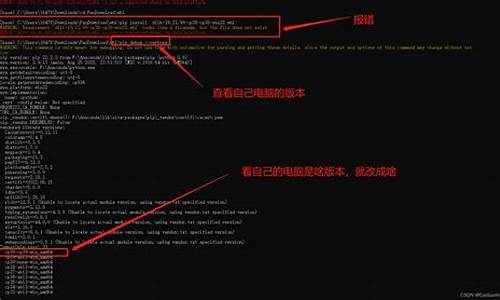
python pip å®è£ dlibä¸ç´å¤±è´¥ï¼
å®è£ 失败éè¦æ£æ¥å 个é®é¢ï¼å ¼å®¹é®é¢ï¼å¯¹åºçå æ¯æçæä½ç³»ç»ï¼æ¯æçPythonçæ¬
å®è£ é®é¢ï¼é¨åå åªè½éè¿æºç å®è£ ï¼æè 离线çwheelæ¹å¼å®è£
æ ¸å¯¹å çå®è£ ææ¡£
