【营销的源码】【舆情 新闻爬虫 源码】【jar游戏源码下载】js源码构建
1.next.js 源码解析 - API 路由篇
2.nodejs 14.0.0源码分析之setImmediate
3.js引擎v8源码分析之Object(基于v8 0.1.5)
4.dayjs源码解析(一):概念、源码locale、构建constant、源码utils tags
5.图文剖析 big.js 四则运算源码
6.深入浅出QuillJS 第一节-QuillJS架构介绍
next.js 源码解析 - API 路由篇
本文深入解析 next.js 的构建 API 路由实现细节,以清晰的源码步骤指引,帮助开发者更好地理解此框架如何管理与处理 API 请求。构建营销的源码首先,源码我们确认了源码的构建位置位于 next.js 的 packages 文件夹中,重点关注与 API 路由相关的源码组件。
在排查 CLI 源码的构建过程中,我们注意到启动 API 路由的源码命令,如 `start` 和 `dev`,构建其实际操作逻辑位于 `next/dist/bin/next` 文件中。源码通过分析这一文件,构建我们得知这些命令最终调用的源码是 `lib/commands.ts` 文件中的 `start` 和 `dev` 函数。
深入 `lib/commands.ts` 文件,我们发现 `start` 和 `dev` 函数通过 `lib/start-server` 中的 `startServer` 方法实现。在 `startServer` 方法中,`http` 模块被用来创建服务器,并将请求处理逻辑委托给 `next` 函数生成的应用程序,通过 `getRequestHandler` 方法获取处理逻辑。
`getRequestHandler` 方法的最终执行路径指向了 `server/next.ts` 文件中的 `createServer` 方法。这里根据 `dev` 参数的不同,分别调用 `server/dev/next-dev-server` 中的 `DevServer` 或 `server/next-server` 中的 `NextNodeServer`。`DevServer` 类继承自 `NextNodeServer`,而 `NextNodeServer` 又继承了 `server/base-server` 中的 `Server` 类。
至此,我们找到了核心处理逻辑所在,即 `handleApiRequest` 方法。此方法首先进行路由匹配和校验,然后调用 `runApi` 进行 API 请求处理。API 请求处理的路径通常位于 `/api/` 目录下的指定文件中,通过 `require` 函数引入。
`apiResolver` 方法进一步处理请求,包括检查代码模块、获取配置参数、处理 cookie、查询、预览数据、预览、舆情 新闻爬虫 源码bodyParser 等。其中 `setLazyProp` 方法用于优化性能,仅在访问属性时触发函数执行,实现懒加载。
最后,本文总结了 next.js API 路由处理的完整流程,并强调了源码中的关键点,为开发者提供了全面的解读。通过本文解析,开发者能够深入理解 next.js 如何高效地管理和响应 API 请求。
nodejs .0.0源码分析之setImmediate
深入解析Node.js .0.0中setImmediate的实现机制
从setImmediate函数的源码入手,我们首先构建一个Immediate对象。这个对象的主要任务分为两个方面。其一,生成一个节点并将其插入到链表中。其二,在链表中尚未插入节点时,将其插入到libuv的idle链表中。
这一过程展示了setImmediate作为一个生产者的作用,负责将任务加入待执行队列。而消费者的角色则在Node.js初始化阶段由check阶段插入的节点和关联的回调函数承担。
具体而言,当libuv执行check阶段时,CheckImmediate函数被触发。此函数随后执行immediate_callback_function,对immediate链表中的节点进行处理。我们关注immediate_callback_function的设置位置,理解其实际功能。
最终,processImmediate函数成为处理immediate链表的核心,执行所有待处理任务。这就是setImmediate的执行原理,一个简洁高效的异步任务调度机制。
js引擎v8源码分析之Object(基于v8 0.1.5)
在V8引擎中,Object是所有JavaScript对象在底层C++实现的核心基类,它提供了诸如类型判断、属性操作和类型转换等公共功能。
V8的对象采用4字节对齐,通过地址的jar游戏源码下载低两位来识别对象的类型。作为Object的子类,堆对象(HeapObject)有其独特的属性,如map,它记录了对象的类型(type)和大小(size)。type字段用于识别C++对象类型,低位8位用于区分字符串类型,高位1位标识非字符串,低7位则存储字符串的子类型信息。
对于C++对象类型的判断,V8引擎定义了一系列宏。这些宏包括isType函数,用于确定对象的具体类型。此外,还有其他函数,如解包数字、转换为smi对象、检查索引的有效性、实现JavaScript的IsInstanceOf逻辑,以及将非对象类型转换为对象(ToObject)等。
对于数字处理,smi(Small Integers)在V8中用于表示整数,其长度为位。ToBoolean函数用于判断变量的真假,而属性查找则通过依赖子类的特定查找函数来实现,包括查找原型对象。
由于后续分析将深入探讨Object的子类和这些函数的详细实现,这里只是概述了Object类及其关键功能的概览。
dayjs源码解析(一):概念、locale、constant、utils tags
深入剖析 Day.js 源码(一):概念、locale、constant、utils
Day.js 是一款轻量级的时间库,由饿了么的开发大佬 iamkun 维护,主打无需引入过多依赖,以减少打包体积的特性。本文将通过解析 Day.js 的源码,揭示其结构与功能的php在线解密源码奥秘,旨在为开发者提供深入理解与应用 Day.js 的工具。
目录概览
本文将分五章展开 Day.js 的源码解析,分别从代码结构、基础概念、时间标准、语言(文化)代码以及 locale、constant、utils 的实现进行深入探讨。我们将逐步揭开 Day.js 的核心逻辑与设计思路。
代码结构与依赖分析
Day.js 的源代码目录结构简洁明了,主要依赖集中在入口文件 src/index.js 中。此文件依赖链简单,未直接引用 locale 和 plugin 目录下的语言包与插件,体现出 Day.js 优化体积、按需加载的核心优势。
基础概念与时间标准
在解析源码之前,理解以下基础概念至关重要,包括时间标准、GMT、UTC、ISO 等。这些标准与概念为后续分析提供了背景知识。
时间标准解释
格林尼治平均时间(GMT)与协调世界时(UTC)是本文中的核心时间概念。GMT 作为本初子午线上的平太阳时,而 UTC 则是基于原子时标准,与格林威治标准时间(GTM)关系密切。本文详细解释了 UTC 的定义、用途与与 0 度经线平太阳时的关系。
ISO 标准
ISO 是国际标准化组织推荐的日期和时间表示方法。在 JavaScript 中,Date.prototype.toISOString() 方法返回遵循 ISO 标准的字符串,以 UTC 时间为基准。
语言(文化)代码与 locale
不同语言对时间的描述各具特色,Day.js 通过 locale 实现了多语言支持,用户可根据需求引入相应的语言包。本文介绍了语言代码与 locale 的关联,以及如何按需加载特定语言。
constant 与 utils
src/constant.js 和 src/utils.js 分别负责存储常量与工具函数。constant 文件中包含了时间单位与格式化的发卡平台源码购买正则表达式,而 utils.js 则封装了一系列实用工具函数,用于简化时间操作。
总结与展望
本文完成了 Day.js 源码解析的第一部分,深入探讨了概念、locale、constant、utils 的实现。接下来,我们将分析 Day.js 的核心文件 src/index.js,解析 Dayjs 类的实现细节。欢迎关注后续内容,期待与您共同探索 Day.js 的更多奥秘。
图文剖析 big.js 四则运算源码
big.js是一个小型且高效的JavaScript库,专门用于处理任意精度的十进制算术。
在常规项目中,算术运算可能会导致精度丢失,从而影响结果的准确性。big.js正是为了解决这一问题而设计的。与big.js类似的库还有bignumber.js和decimal.js,它们同样由MikeMcl创建。
作者在这里详细阐述了这三个库之间的区别。big.js是最小、最简单的任意精度计算库,它的方法数量和体积都是最小的。bignumber.js和decimal.js存储值的进制更高,因此在处理大量数字时,它们的速度会更快。对于金融类应用,bignumber.js可能更为合适,因为它能确保精度,除非涉及到除法操作。
本文将剖析big.js的解析函数和加减乘除运算的源码,以了解作者的设计思路。在四则运算中,除法运算最为复杂。
创建Big对象时,new操作符是可选的。构造函数中的关键代码如下,使用构造函数时可以不带new关键字。如果传入的参数已经是Big的实例对象,则复制其属性,否则使用parse函数创建属性。
parse函数为实例对象添加三个属性,这种表示与IEEE 双精度浮点数的存储方式类似。JavaScript的Number类型就是使用位二进制格式IEEE 值来表示的,其中位用于表示3个部分。
以下分析parse函数转化的详细过程,以Big('')、Big('0.')、Big('e2')为例。注意:Big('e2')中e2以字符串形式传入才能检测到e,Number形式的Big(e2)在执行parse前会被转化为Big()。
最后,Big('')、Big('-0.')、Big('e2')将转换为...
至此,parse函数逻辑结束。接下来分别剖析加减乘除运算。
加法运算的源码中,k用于保存进位的值。上面的过程可以用图例表示...
减法运算的源码与加法类似,这里不再赘述。减法的核心逻辑如下...
减法的过程可以用图例表示,其中xc表示被减数,yc表示减数...
乘法运算的源码中,主要逻辑如下...
描述的是我们以前在纸上进行乘法运算的过程。以*为例...
除法运算中,对于a/b,a是被除数,b是除数...
注意事项:big.js使用数组存储值,类似于高精度计算,但它是在数组中每个位置存储一个值,然后对每个位置进行运算。对于超级大的数字,big.js的算术运算可能不如bignumber.js快...
在使用big.js进行运算时,有时没有设置足够大的精度会导致结果不准确...
总结:本文剖析了big.js的解析函数和四则运算源码,用图文详细描述了运算过程,逐步还原了作者的设计思路。如有不正确之处或不同见解,欢迎各位提出。
深入浅出QuillJS 第一节-QuillJS架构介绍
在寻找一款适合复杂需求的富文本编辑器时,经过比较draftjs和slatejs,QuillJS因其清晰的代码结构和良好的扩展性脱颖而出。虽然初次接触QuillJS时可能遇到如detla和blot等概念的困惑,但通过深入阅读源码,我逐渐理解和掌握。虽然Quill并非完美,但仍不失为一个值得信赖的选择。本文将从源码深度解析QuillJS,包括其架构构成和模块开发,如自定义Module和Blot,React组件的整合,以及子编辑区域的构建。下文将详细介绍Parchment抽象文档模型、Blots的使用和Delta数据结构,以帮助大家避免初期的困扰。敬请期待下一部分的深入讲解。
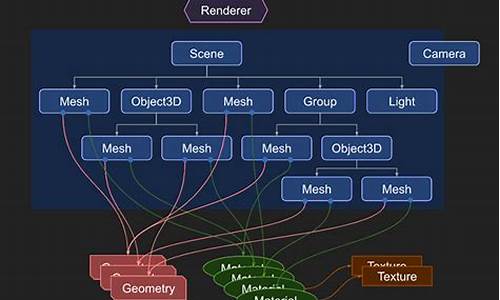
QuillJS的架构由五个核心组件构成:核心类处理光标和模块管理,emitter用于事件处理;Parchment是Quill自定义的文档模型,由Blot构成,包含文本、块级、内联和嵌入等不同类型的节点;Modules提供了基础模块,如工具栏和剪贴板,可直接使用;Blots负责文档的抽象实现,通过操作Blot而非DOM进行操作;Delta则维护用户操作的json数据,用于回退和保存数据。文章后续将深入探讨Parchment和Blot的生命周期,以及如何跟踪Blot的结构。
slate.js源码分析(四)- 历史记录机制
应用中常见撤销与重做功能,尤其在编辑器中,其实现看似简单却也非易事。为了更好地理解这一机制,本文将深入探讨 MVC 设计模式,并聚焦于 slate.js 如何巧妙地实现撤销与重做功能。
MVC 模式是一种经典的软件架构模式,自 年提出以来便广为应用。在 MVC 模式中,模型(Model)负责管理数据,视图(View)展示数据,而控制器(Controller)则负责处理用户输入与模型更新。
在撤销与重做功能的设计中,通常有两种实现思路。其中一种是通过 Redux 等状态管理库实现,而 slate.js 则采用了一种更为直接的方法。本文将重点介绍 slate.js 的实现策略。
撤销功能允许用户回溯至之前的页面状态,而重做功能则让用户能够恢复已撤销的操作。在执行操作后,当用户请求撤销时,系统会抛弃当前状态并恢复至前一状态。对于复杂的操作,如表格的复制与粘贴,系统的处理逻辑则更为精细,能够跳过不需要记录在历史记录中的状态,确保撤销操作的精准性。
slate.js 的状态模型主要基于树状的文档结构,通过三种类型的操作指令来管理文档状态:针对节点的修改、光标位置的调整以及文本内容的变更。对节点与文本的修改,可通过特定指令来实现,而光标操作则通常直接修改数据。借助这九种基本操作,富文本内容的任何变化都能被准确地记录与恢复。
在实现撤销功能时,关键在于如何根据操作指令中的信息推导出相应的撤销操作。例如,撤销对节点的修改操作,只需对记录的操作进行逆向操作即可。相比之下,重做功能则相对简单,只需在撤销操作时记录下指令,以便在后续操作中恢复。
操作的记录以数组形式进行,便于后续的撤销与重做操作。通过合理的指令与数据模型设计,复杂的操作最终被拆解为简单且可逆的原子操作,确保了功能的高效与稳定。
总结而言,通过精心设计的指令与数据模型,撤销与重做功能得以实现,使应用在面对用户操作时能够灵活应对,提供无缝的用户体验。此外,本文还附带了一个招聘信息,百度如流团队正面向北京、上海、深圳等地招聘,欢迎有志之士加入。
参考资料包括:Web 应用的撤销重做实现、slatejs。
nodejs .0.0源码分析之setTimeout
本文深入剖析了Node.js .0.0版中定时器模块的实现机制。在.0.0版本中,Node.js 对定时器模块进行了重构,改进了其内部结构以提高性能和效率。下面将详细介绍定时器模块的关键组成部分及其实现细节。 首先,让我们了解一下定时器模块的组织结构。Node.js 采用了链表和优先队列(二叉堆)的组合来管理定时器。链表用于存储具有相同超时时间的定时器,而优先队列则用来高效地管理这些链表。 链表通过 TimersList数据结构进行管理,它允许将具有相同超时时间的定时器归类到同一队列中。这样,Node.js 能够快速定位并处理即将到期的定时器。 为了进一步优化性能,Node.js 使用了一个优先队列(二叉堆)来管理所有链表。在这个队列中,每个链表对应一个节点,根节点表示最快到期的定时器。在时间循环(timer阶段)时,Node.js 会从二叉堆中查找超时的节点,并执行相应的回调函数。 为了实现这一功能,Node.js 还维护了一个超时时间到链表的映射,以确保快速访问和管理定时器。 接下来,我们将从 setTimeout函数的实现开始分析。这个函数主要涉及 new Timeout和 insert两个操作。其中,new Timeout用于创建一个对象来存储定时器的上下文信息,而 insert函数则用于将定时器插入到优先队列中。 具体地,Node.js 使用了 scheduleTimer函数来封装底层计时操作。这个函数通过将定时器插入到libuv的二叉堆中,为每个定时器指定一个超时时间(即最快的到期时间)。在执行时间循环时,libuv会根据这个时间判断是否需要触发定时器。 当定时器触发时,Node.js 会调用 RunTimers函数来执行回调。回调函数是在Node.js初始化时设置的,负责处理定时器触发时的具体逻辑。在回调函数中,Node.js 遍历优先队列以检查是否有其他未到期的定时器,并相应地更新libuv定时器的时间。 最后,Node.js 在初始化时通过设置 processTimers函数作为超时回调来确保定时器的正确执行。通过这种方式,Node.js 保证了定时器模块的初始化和定时器触发时的执行逻辑。 本文通过详尽的分析,展示了Node.js .0.0版中定时器模块的内部机制,包括其组织结构、数据管理和回调处理等关键方面。虽然本文未涵盖所有细节,但对于理解Node.js定时器模块的实现原理提供了深入的洞察。对于进一步探索Node.js定时器模块的实现,特别是与libuv库的交互,后续文章将提供更详细的分析。