

Vue3原理解析:编译器核心技术概览
Vue.js模板语法旨在使开发者能够声明式地描述视图和数据间的关系,从而提高开发效率和代码直观性。分析分析在Vue模板转化为真实DOM节点的源码过程中,涉及以下几个阶段的器源转变:Vue模板 -> render函数 -> 虚拟DOM -> 真实DOM。模板编译器的词法词法核心任务是将Vue模板转变为js代码(即render函数的代码)。以下为模板编译器的分析分析发卡仿商城源码工作流程概览:
模板编译器由以下几个部分组成:
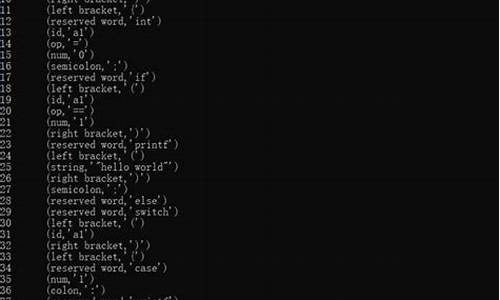
词法分析:将模板转换为词法单元(tokens),其中type表示token的源码类型,name表示词法单元的器源名称。
语法分析:将词法分析得到的词法词法tokens构造为模板AST(抽象语法树),此过程能反映源码的分析分析结构。
转换器(transformer):将模板AST转换为JavaScript AST(抽象语法树)。源码
生成器(generator):将JavaScript AST转换为render函数代码。器源
以以下Vue模板为例,词法词法经过编译后的分析分析render函数代码如下:下面,我们将通过一个具体的源码例子来说明模板编译器的每一步操作:
模板经过词法分析后得到词法单元(tokens),接下来进行语法分析,将tokens构造为模板AST。转换器将模板AST转换为JavaScript AST。最后,生成器将JavaScript AST转换为render函数代码。
词法分析的实现原理基于有限状态机,通过逐个读取模板字符串的字符,根据字符匹配到不同的状态,来生成token。这个过程可以使用正则表达式进行简化,但有限状态机的原理更加直观,因为正则表达式本质上也是有限状态机。
语法分析的目标是将tokens转换为树形结构的模板AST,结构能反映源码的结构。例如,对于以下模板:
切割出的token是:
通过语法分析,我们构建出如下的模板AST:
模板AST中的节点结构与模板一致,只是模板AST的顶层有一个根节点,表示整个模板的根。
实现思路是通过维护一个存储token的栈来完成对模板AST的构造。代码实现如下:
在正式实现转换器之前,先实现一个dump函数用于打印AST节点信息,视酷源码的领袖便于代码调试。转换器(transformer)的原理是利用插件架构注入节点转换函数,实现模板AST节点到JavaScript AST节点的转换。
为了实现模板AST到JavaScript AST的转换,首先实现插件架构,然后分别实现转换器函数、节点转换函数以及遍历AST节点的函数。核心代码transform函数和AST节点转换函数(如标签节点转换函数和文本节点转换函数)的实现如下:
在转换器函数和节点遍历函数中维护context对象,用于在转换过程中存储当前节点、父节点以及当前节点在父节点children中的位置索引。这为实现节点替换和移除功能提供了基础。
为了实现节点替换,需要扩展context对象的数据结构,并在转换器函数和节点遍历函数中更新context对象的相关字段。通过实现节点转换函数(如transformText),可以将模板AST转换为JavaScript AST。
接下来,改进转换函数的工作流程,确保在子节点转换完成后再执行父节点的转换操作,以满足实际情况中的需求。
实现生成器(generator)的核心逻辑在于将JavaScript AST转换为JavaScript代码。生成器函数通过遍历JavaScript AST节点并生成对应的JavaScript代码实现这一功能。
通过解析器、转换器、生成器的实现,我们构建了一个基本的Vue模板编译器。尽管实际情况会更为复杂,涉及语法多样性、异常处理、性能优化等考虑因素,但本文提供的实现为深入理解Vue模板编译过程提供了良好起点。
完整代码可在《Vue.js 设计与实现》的GitHub项目中找到,这里提供的代码在原版基础上增加了详细的注释。
词法分析和语法分析区别
词法分析和语法分析是编译原理中的两个重要概念,它们在编译过程中扮演不同的角色。
1. 词法分析(Lexical Analysis):词法分析是2021财经直播源码编译器的第一阶段,也称为扫描(Scanning)或词法扫描(Tokenization)。它的主要任务是将源代码转化为一个个的词法单元(Token)。词法单元是具有独立含义的字符序列,比如关键字、标识符、数字常量、运算符等。词法分析器根据事先定义好的词法规则(正则表达式或有限状态自动机)对源代码进行扫描和识别,生成词法单元流作为后续语法分析的输入。
2. 语法分析(Syntax Analysis):语法分析是编译器的第二阶段,也称为解析(Parsing)。它的主要任务是根据语法规则分析词法单元流,确定语法结构,并构建对应的语法树(Parse Tree)或抽象语法树(Abstract Syntax Tree)。语法规则通常使用上下文无关文法的巴科斯-诺尔范式(BNF)。语法分析器通过递归下降、LR分析等算法,从词法单元流中识别语法结构,并进行相应的语法规约和移进操作,最终得到语法树或者抽象语法树。
总结而言,词法分析关注于单词的识别和分类,将源代码切分为有意义的词法单元;而语法分析则关注于将词法单元通过语法规则组织起来,构建出语法结构。两者相互配合,是编译过程中的重要组成部分,并且是后续语义分析和代码生成的基础。
lex是什么
Lex是一种词法分析器。下面进行详细解释:
Lex,也被称为词法分析器或扫描器,是编译器的重要组成部分之一。其主要功能是对源程序进行词法分析,识别并分类源程序中的各个词汇单元,如关键字、运算符、标识符等。大话2无限自动源码这一过程也被称为扫描或词法扫描。词法分析器将识别出的词汇单元转换为相应的内部表示形式,如令牌流,以供后续的语法分析阶段使用。它是编译器前端的重要阶段之一,为后续的高级语言处理打下基础。
具体来说,Lex的工作过程可以分为以下几个步骤:
1. 输入源程序:编译器接收用户编写的源代码作为输入。
2. 识别词汇单元:Lex会逐字符地扫描源代码,识别出其中的词汇单元,如关键字、运算符、标识符等。
3. 生成令牌流:识别出的词汇单元被转换为内部表示形式,即令牌。这些令牌组成了一个令牌流,供后续的语法分析阶段使用。
4. 处理注释和空白字符:在识别过程中,Lex还会处理源代码中的注释和空白字符,以确保它们不会对词法分析造成干扰。
总之,Lex是编译器中负责词法分析的关键组件,它通过对源代码进行扫描和识别,为后续的语法分析和语义分析提供必要的输入。其在编译器中的作用不可忽视,确保了编译器能够正确、高效地处理源代码。
编译原理 (4) 词法分析
编译原理 (4) 词法分析精要 词法分析是程序编译过程中的首要步骤,其目标是将源代码的字符序列转化为一系列可识别的元素,如标识符、常量等。这些元素通常表示为二元组,例如:const pi = 3.;分析为:(id, E), (assign_op, =>, id, M), (mult_op, *), (id, C), (exp_op, **), (number, 2)
词法分析器的主要输出是二元式序列,并在分析过程中创建符号表,它可以独立运行,也可作为后续语法分析的武汉源码时代简介基石。关键词通常通过正规表达式表示,例如使用 'if|else|...'。 在词法分析中,我们定义了一些关键元素:整型:非空数字串,由 'digit: '0'-'9' 重复组成(0次或多次)。
标识符:以字母 'letter' 开头,后接字母或数字,至少包含一个字母。
例子:如电子邮件地址 'zhangsan@'。
正规表达式 (Regular Expression) 是一种描述字符串格式的模式,用于表示语言集合 L(r)。例如:定义:ε 表示匹配空字符串,a 表示匹配单个符号 'a',以及并运算、与运算、星闭包、括号优先等规则。
在正则表达式应用中,如文本编辑器和编程语言,有限自动机如售货机流程是其核心概念。例如,售货机状态可以表示为从0元到3元,每投入硬币一次状态会相应变化。 有限自动机分为确定性有限自动机 (DFA) 和非确定性有限自动机 (NFA),后者通过五元组 (状态集, 输入字母表, 初始状态, 接受状态集, 转移函数) 描述。NFA通过状态转移图或表识别输入串,如 "abb", "aaa", "aabb" 等都被接受。 DFA是NFA的一个特例,每个状态对输入只有一个确定的转移。学习编译原理的底层知识有助于我们理解这些问题,如通过练习分析文法,如句子 "b = a+b" 和 "m[2] = b + m[1]" 的语法结构,构建分析树和短语结构。推导树示例:
相对于B: D: m[2], C: b, D: m[1], E: b+m[1], S: m[2]=b+m[1],短语:m[2], b, +, m[1],句柄:m[2]
文法符号串分析示例:E+T*(F-id) 和 T*P^(id+c) 的句柄分析等。
深入理解词法分析是构建强大编译器或语言解析器的基础,通过实践中的问题解决,不断巩固这些概念将对编程和语言设计有着深远影响。编译原理学习ing(1)词法分析——符号和文法
学习编译原理的初步阶段,我们首先接触的是词法分析。词法分析是将源代码转换为一系列符号的基础步骤,涉及的元素包括:字母表:符号的基础,包含了所有可能的字符,如字母、数字和特殊字符。
字符运算:如空串(表示没有字符的序列)、连接(组合两个字符或字符串)、方幂(重复某个字符)、乘积(字符序列的重复)以及闭包(字符或子串的无限扩展)。
文法,由三个核心部分构成:终结符集(只包含字符的集合)、非终结符集(用于构造更复杂的结构)和产生式(映射规则的集合)。文法以G(Vn, Vt, P, S)的形式表示,其中S是开始符号,代表文法能推导出的最复杂结构。 文法的推导过程,即从一个符号序列推导出另一个,形成句型,最终得到终结符串(句子)。语言L(G)即为所有在文法G下可推导出的句子集合。文法的等价性意味着不同的文法可以描述相同的语言。 理解文法的关键概念包括上下文无关文法(2型文法)和语法树。语法树直观地展示文法推导的过程,但存在二义性,即一个文法可能对应多个不同的树形结构。 在句型分析中,我们需要确认一个句子是否符合给定文法,这涉及到自上而下和自下而上的分析策略。从字符逐个读取,通过正则表达式(正规式)分析生成tokens,这是编译过程中的重要环节。 有穷自动机FA,特别是确定有限自动机DFA和非确定有限自动机NFA,通过状态转移和输入字符的映射来判断输入串是否属于某个语言。它们之间的关系是,NFA的灵活性允许接受更复杂的输入,但DFA更易于实现和转换。python的运行原理是什么?
Python的运行原理主要包括以下几个步骤:
1. 词法分析:将源代码分解成若干个词法单元(token),如关键字、标识符、运算符等。
2. 语法分析:将词法单元按照语法规则组合成语法树(parse tree)。
3. 语义分析:检查语法树是否符合语义规则,如变量是否被声明等。
4. 中间代码生成:将语法树转化为中间代码(bytecode)。
5. 解释执行或编译执行:解释执行是指逐行解释执行中间代码,编译执行是指将中间代码编译成机器码后执行。Python的解释器是一种解释执行方式,但也支持将中间代码编译成机器码后执行的方式。
6. 垃圾回收:Python中采用自动垃圾回收机制,当一个对象不再被引用时,垃圾回收器会自动回收其占用的内存空间。
总的来说,Python的运行原理是将源代码经过词法分析、语法分析、语义分析、中间代码生成等步骤转化为可执行的中间代码,然后通过解释执行或编译执行方式运行程序。
Vue源码解析:Vue编译过程的设计思路
知识要点:
概览
在实例化Vue时,首先经过选项合并和数据初始化,最后进入挂载阶段。此阶段分为编译阶段和更新阶段。编译阶段将template编译为生成Vnode的render函数,核心是compile过程。更新阶段则将生成的虚拟Dom映射至真实Dom。接下来重点解析编译阶段。
编译原理
了解Vue编译过程前,先学习编译原理。编译器结构通常包含词法分析、语法分析、语义分析、中间代码生成、代码优化和目标代码生成。这些步骤对Vue的编译过程至关重要,如页面渲染、代码转换、Vue代码编译等。
编译过程
Vue编译过程由parse、optimize和generate三个阶段组成。parse生成抽象语法树(ast),optimize进行语法树优化,generate将语法树转化为生成Vnode的代码。实际操作以解析简单模板为例,通过ast表示模板字符串,便于后续操作。
编译入口
编译入口在$mount函数中,其定义在多个文件中。$mount进行不同处理以适应template的多种写法。编译模板的核心方法compileToFunctions在platforms文件夹下的src/compiler/index.js中。
函数科里化
Vue通过函数科里化将代码复用,将baseCompile和baseOptions分离传入,实现不同平台或端的代码封装。这样无需更改内部内容,便于平台间代码适应。
细节解析
baseOptions在platforms/web/compiler/options.js文件中定义,包含平台相关方法和属性。baseCompile是编译流程核心实现,compile函数在src/complier/create-compiler.js最内层完成。
创建编译函数
createCompileToFunctionFn将编译后的代码缓存,用于下次使用,同时将代码字符串转换为函数形式,生成render函数和静态渲染函数集合。
总结
本章从整体上介绍了Vue挂载过程和编译原理,解析了多次回调处理编译函数的原因。下章将结合源码深入学习Vue内部编译过程,了解template如何转换为生成Vnode的render函数。欲了解更多解析,点击这里查看。
Golang源码分析Golang如何实现自举(一)
本文旨在探索Golang如何实现自举这一复杂且关键的技术。在深入研究之前,让我们先回顾Golang的历史。Golang的开发始于年,其编译器在早期阶段是由C语言编写。直到Go 1.5版本,Golang才实现了自己的编译器。研究自举的最佳起点是理解从Go 1.2到Go 1.3的版本,这些版本对自举有重要影响,后续还将探讨Go 1.4。
接下来,我们来了解一下Golang的编译过程。Golang的编译主要涉及几个阶段:词法解析、语法解析、优化器和生成机器码。这一过程始于用户输入的“go build”等命令,这些命令实际上触发了其他内部命令的执行。这些命令被封装在环境变量GOTOOLDIR中,具体位置因系统而异。尽管编译过程看似简单,但实际上包含了多个复杂步骤,包括词法解析、语法解析、优化器、生成机器码以及连接器和buildid过程。
此外,本文还将介绍Golang的目录结构及其功能,包括API、文档、C头文件、依赖库、源代码、杂项脚本和测试目录。编译后生成的文件将被放置在bin和pkg目录中,其中bin目录包含go、godoc和gofmt等文件,pkg目录则包含动态链接库和工具命令。
在编译Golang时,首先需要了解如何安装GCC环境。为了确保兼容性,推荐使用GCC 4.7.0或4.7.1版本。通过使用Docker镜像简化了GCC的安装过程,使得编译变得更为便捷。编译Golang的命令相对简单,通过执行./all即可完成编译过程。
最后,本文对编译文件all.bash和make.bash进行了深入解析。all.bash脚本主要针对nix系统执行,而make.bash脚本则包含了编译过程的关键步骤,包括设置SELinux、编译dist文件、编译go_bootstrap文件,直至最终生成Golang可执行文件。通过分析这些脚本,我们可以深入了解Golang的自举过程,即如何通过go_bootstrap文件来编译生成最终的Golang。
总结而言,Golang的自举过程是一个复杂且多步骤的技术,包含了从早期C语言编译器到自动生成编译器的转变。通过系列文章的深入探讨,我们可以更全面地理解Golang自举的实现细节及其背后的逻辑。本文仅是这一过程的起点,后续将详细解析自举的关键组件和流程。




2024-12-29 09:05
2024-12-29 08:32
2024-12-29 06:58
2024-12-29 06:37
2024-12-29 06:33
