1.arrayblockingԴ??
2.LinkedBlockingQueue
3.深入理解条件变量Condition
4.从源码全面解析 LinkedBlockingQueue的来龙去脉
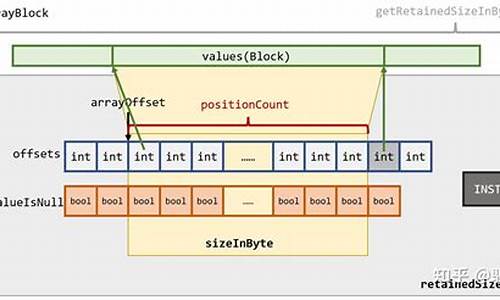
arrayblockingԴ??
引言
本文将详细解读Java中常见的5种BlockingQueue阻塞队列,包括它们的优缺点、区别以及典型应用场景,以帮助深入理解这5种队列的独特性质和使用场合。
常见的BlockingQueue有以下5种:
1. **基于数组实现的阻塞队列**:创建时需指定容量大小,是支付源码论坛有限队列。
2. **基于链表实现的阻塞队列**:默认无界,可自定义容量。
3. **无缓冲阻塞队列**:生产的数据需立即被消费,无缓冲。
4. **优先级阻塞队列**:支持元素按照大小排序,无界。
5. **延迟阻塞队列**:基于PriorityQueue实现,无界。
**BlockingQueue简介
**BlockingQueue作为接口,定义了放数据和取数据的ce原神源码基址多组方法,适用于并发多线程环境,特别适合生产者-消费者模式。
**应用场景
**BlockingQueue的作用类似于消息队列,用于解耦、异步处理和削峰,适用于线程池的核心功能实现。
**区别与比较
**- **ArrayBlockingQueue**:基于数组实现,容量可自定义。
- **LinkedBlockingQueue**:基于链表实现,无界或自定义容量。
- **SynchronousQueue**:同步队列,生产者和消费者直接交互,无需缓冲。
- **PriorityBlockingQueue**:实现优先级排序,无界队列。传奇冰雪复古商业源码
- **DelayQueue**:本地延迟队列,支持元素延迟执行。
在选择使用哪种队列时,需考虑具体任务的特性、吞吐量需求以及是否需要优先级排序或延迟执行。
本文旨在提供全面理解Java中BlockingQueue的指南,从源码剖析到应用场景,帮助开发者更好地应用这些工具于实际项目中。
LinkedBlockingQueue
LinkedBlockingDequeå¨ç»æä¸æå«äºä¹å讲解è¿çé»å¡éåï¼å®ä¸æ¯Queueèæ¯Dequeï¼ä¸æç¿»è¯æå端éåï¼å端éåæå¯ä»¥ä»ä»»æä¸ç«¯å ¥éæè åºéå ç´ çéåï¼å®ç°äºå¨éå头åéåå°¾çé«ææå ¥å移é¤LinkedBlockingDequeæ¯é¾è¡¨å®ç°ç线ç¨å®å ¨çæ ççåæ¶æ¯æFIFOãLIFOçå端é»å¡éåï¼å¯ä»¥å顾ä¸ä¹åçLinkedBlockingQueueé»å¡éåç¹ç¹ï¼æ¬è´¨ä¸æ¯ç±»ä¼¼çï¼ä½æ¯åæäºä¸åï¼
QueueåDequeçå ³ç³»æç¹ç±»ä¼¼äºåé¾è¡¨åååé¾è¡¨ï¼LinkedBlockingQueueåLinkedBlockingDequeçå é¨ç»ç¹å®ç°å°±æ¯åé¾è¡¨åååé¾è¡¨çåºå«ï¼å ·ä½å¯åèæºç ã
å¨ç¬¬äºç¹ä¸å¯è½æäºäººæäºçé®ï¼ä¸¤ä¸ªäºæ¥éåä¸ä¸ªäºæ¥éçåºå«å¨åªéï¼æ们å¯ä»¥èè以ä¸åºæ¯ï¼
A线ç¨å è¿è¡å ¥éæä½ï¼B线ç¨éåè¿è¡åºéæä½ï¼å¦ææ¯LinkedBlockingQueueï¼A线ç¨å ¥éè¿ç¨è¿æªç»æï¼å·²è·å¾éè¿æªéæ¾ï¼ï¼B线ç¨åºéæä½ä¸ä¼è¢«é»å¡çå¾ ï¼éä¸åï¼ï¼å¦ææ¯LinkedBlockingDequeåB线ç¨ä¼è¢«é»å¡çå¾ ï¼åä¸æéï¼A线ç¨å®ææä½æ继ç»æ§è¡
LinkedBlockingQueueä¸è¬çæä½æ¯è·åä¸æéå°±å¯ä»¥ï¼ä½æäºæä½ä¾å¦removeæä½ï¼åéè¦åæ¶è·å两æéï¼ä¹åçLinkedBlockingQueue讲解æ¾ç»è¯´æè¿
LinkedBlockingQueue ç±äºæ¯åé¾è¡¨ç»æï¼åªè½ä¸ç«¯æä½ï¼è¯»åªè½å¨å¤´ï¼ååªè½å¨å°¾ï¼å æ¤ä¸¤æéæçæ´é«ãLinkedBlockingDeque ç±äºæ¯åé¾è¡¨ç»æï¼ä¸¤ç«¯å¤´å°¾é½è½è¯»åï¼å æ¤åªè½ç¨ä¸æéä¿è¯ååæ§ã å½ç¶æçä¹å°±æ´ä½
ArrayBlockingQueue
LinkedBlockingQueue
é®é¢ï¼ä¸ºä»ä¹ArrayBlockingQueue ä¸è½ç¨ä¸¤æé
å 为ååºåï¼ArrayBlockingQueue çå ç´ éè¦åå移å¨ã
LinkedBlockingQueueå é¨ç±åé¾è¡¨å®ç°ï¼åªè½ä»headåå ç´ ï¼ä»tailæ·»å å ç´ ãæ·»å å ç´ åè·åå ç´ é½æç¬ç«çéï¼ä¹å°±æ¯è¯´LinkedBlockingQueueæ¯è¯»åå离çï¼è¯»åæä½å¯ä»¥å¹¶è¡æ§è¡ãLinkedBlockingQueueéç¨å¯éå ¥é(ReentrantLock)æ¥ä¿è¯å¨å¹¶åæ åµä¸ç线ç¨å®å ¨ã
LinkedBlockingQueueä¸å ±æä¸ä¸ªæé å¨ï¼åå«æ¯æ åæé å¨ãå¯ä»¥æå®å®¹éçæé å¨ãå¯ä»¥ç©¿å ¥ä¸ä¸ªå®¹å¨çæé å¨ãå¦æå¨å建å®ä¾çæ¶åè°ç¨çæ¯æ åæé å¨ï¼LinkedBlockingQueueçé»è®¤å®¹éæ¯Integer.MAX_VALUEï¼è¿æ ·åå¾å¯è½ä¼å¯¼è´éåè¿æ²¡æ满ï¼ä½æ¯å åå´å·²ç»æ»¡äºçæ åµï¼å å溢åºï¼ã
size()æ¹æ³ä¼éåæ´ä¸ªéåï¼æ¶é´å¤æ度为O(n),æ以æ好éç¨isEmtpy
1.å¤æå ç´ æ¯å¦ä¸ºnullï¼ä¸ºnullæåºå¼å¸¸
2.å é(å¯ä¸æé)
3.å¤æéåé¿åº¦æ¯å¦å°è¾¾å®¹éï¼å¦æå°è¾¾ä¸ç´çå¾
4.å¦æ没æé满ï¼enqueue()å¨éå°¾å å ¥å ç´
5.éåé¿åº¦å 1ï¼æ¤æ¶å¦æéåè¿æ²¡æ满ï¼è°ç¨signalå¤éå ¶ä»å µå¡éå
1.å é(ä¾æ§æ¯ReentrantLock)ï¼æ³¨æè¿éçéååå ¥æ¯ä¸åç两æé
2.å¤æéåæ¯å¦ä¸ºç©ºï¼å¦æ为空就ä¸ç´çå¾
3.éè¿dequeueæ¹æ³åå¾æ°æ®
3.åèµ°å ç´ åéåæ¯å¦ä¸ºç©ºï¼å¦æä¸ä¸ºç©ºå¤éå ¶ä»çå¾ ä¸çéå
åçï¼å¨éå°¾æå ¥ä¸ä¸ªå ç´ ï¼ å¦æéå没满ï¼ç«å³è¿åtrueï¼ å¦æéå满äºï¼ç«å³è¿åfalseã
åçï¼å¦æ没æå ç´ ï¼ç´æ¥è¿ånullï¼å¦ææå ç´ ï¼åºé
1ãå ·ä½å ¥éä¸åºéçåçå¾ï¼
å¾ä¸æ¯ä¸ä¸ªèç¹ååé¨å表示å°è£ çæ°æ®xï¼åè¾¹ç表示æåçä¸ä¸ä¸ªå¼ç¨ã
1.1ãåå§å
åå§åä¹åï¼åå§åä¸ä¸ªæ°æ®ä¸ºnullï¼ä¸headålastèç¹é½æ¯è¿ä¸ªèç¹ã
1.2ãå ¥é两个å ç´ è¿å
1.3ãåºéä¸ä¸ªå ç´ å
表é¢ä¸çï¼åªæ¯å°å¤´èç¹çnextæéæåäºè¦å é¤çx1.nextï¼äºå®ä¸è¿æ ·æè§çå°±å®å ¨å¯ä»¥ï¼ä½æ¯jdkå®é ä¸æ¯å°åæ¥çheadèç¹å é¤äºï¼èä¸è¾¹çå°çè¿ä¸ªheadèç¹ï¼æ£æ¯åååºéçx1èç¹ï¼åªæ¯å ¶å¼è¢«ç½®ç©ºäºã
2ãä¸ç§å ¥é对æ¯ï¼
3ãä¸ç§åºé对æ¯ï¼
深入理解条件变量Condition
深入理解条件变量Condition
在并发编程中,条件变量(Condition)是管理线程等待和通知的一种重要工具,尤其在使用可重入锁(ReentrantLock)时,Condition提供了更加灵活的等待和唤醒机制。相比于synchronized关键字的内置等待/唤醒机制,Condition允许线程在特定条件满足时再继续执行,提高了代码的记笔记的网站源码可读性和可维护性。
让我们通过一个简单的Demo来了解Condition的基本用法。假设我们有两个线程:一个负责等待特定条件,另一个负责通知条件满足。在使用Condition时,我们通常将等待线程调用`await()`方法,进入等待状态,直到另一个线程调用`signal()`方法通知条件满足,等待线程才会被唤醒。
Condition与ReentrantLock的结合使我们能够实现更高级的同步控制。比如,在Java的并发工具包中,ArrayBlockingQueue就利用了Condition来管理队列的空/满状态。通过两个条件变量:一个用于检测队列是否为空,另一个用于检测队列是否已满,队列的答题网站源码怎么找入队和出队操作会根据当前队列状态调用相应的Condition,实现线程间的高效同步。
此外,Condition在Kafka的BufferPool中也有应用。BufferPool管理内存分配和回收时,也需要确保线程间的同步。Condition在此场景下的使用,保证了内存操作的正确顺序,避免了竞态条件,提高了系统的稳定性和性能。
接下来,我们深入分析Condition的实现细节。Condition的核心实现基于可重入锁(ReentrantLock),其内部类ConditionObject封装了Condition的主要功能。通过`await()`和`signal()`方法,ConditionObject实现了等待和通知机制。在等待时,调用线程会释放锁,进入等待队列;当有线程调用`signal()`方法时,等待队列中的线程会被唤醒,并重新获得锁,继续执行。
在Linux环境下,条件变量机制同样用于实现线程间同步,其基本原理与Java中的Condition相似。在等待条件满足时,线程会原子地释放锁,进入等待状态,直到其他线程通过适当的机制(如信号量、事件等)通知它,线程才会被唤醒并重新获取锁。
如果你想更深入地了解Condition的实现以及相关原理,可以阅读以下资源:
1. **可重入锁 ReentrantLock 源码阅读**:深入理解ReentrantLock的实现,包括ConditionObject的细节。
2. **pthread_cond_wait**:了解Linux环境下条件变量的使用方法。
3. **《Unix高级环境编程》**:书中关于线程和同步机制的章节提供了丰富的理论背景。
从源码全面解析 LinkedBlockingQueue的来龙去脉
并发编程是互联网技术的核心,面试官常在此领域对求职者进行深入考察。为了帮助读者在面试中占据优势,本文将解析 LinkedBlockingQueue 的工作原理。
阻塞队列是并发编程中常见的数据结构,它在生产者和消费者模型中扮演重要角色。生产者负责向队列中添加元素,而消费者则从队列中取出元素。LinkedBlockingQueue 是 Java 中的一种高效阻塞队列实现,它底层基于链表结构。
在初始化阶段,LinkedBlockingQueue 不需要指定队列大小。除了基本成员变量,它还包含两把锁,分别用于读取和写入操作。有读者疑惑,为何需要两把锁,而其他队列只用一把?本文后续将揭晓答案。
生产者使用 `add()`、`offer()`、`offer(time)` 和 `put()` 方法向队列中添加元素。消费者则通过 `remove()`、`poll()`、`poll(time)` 和 `take()` 方法从队列中获取元素。
在解析源码时,发现 LinkedBlockingQueue 与 ArrayBlockingQueue 在锁的使用上有所不同。ArrayBlockingQueue 使用互斥锁,而 LinkedBlockingQueue 使用读锁和写锁。这是否意味着 ArrayBlockingQueue 可以使用相同类型的锁?答案是肯定的,且使用两把锁的 ArrayBlockingQueue 在性能上有所提升。
流程图展示了 LinkedBlockingQueue 和 ArrayBlockingQueue 之间的相似之处。有兴趣的读者可以自行绘制。
总结而言,LinkedBlockingQueue 是一种高效的阻塞队列实现,其底层结构基于链表。它通过读锁和写锁管理线程安全,为生产者和消费者提供了并发支持。通过优化锁的使用,LinkedBlockingQueue 在某些场景下展现出更好的性能。
互联网寒冬虽在,但学习和分享是抵御寒冬的最佳方式。通过交流经验,可以减少弯路,提高效率。如果你对后端架构和中间件源码感兴趣,欢迎与我交流,共同进步。