【hba源码安装】【即将拉升指标源码】【pc源码开发app】java集合源码学习笔记_java 集合源码
1.java集合有哪些内容?集合集合
2.ArrayList详解及扩容源码分析
3.Java集合-Vector介绍、扩容机制、源码源码源码分析
4.死磕 java集合之ArrayDeque源码分析
5.学习java需要学些什么东西啊?
6.Java 集合(3)-- Iterable接口源码级别详解
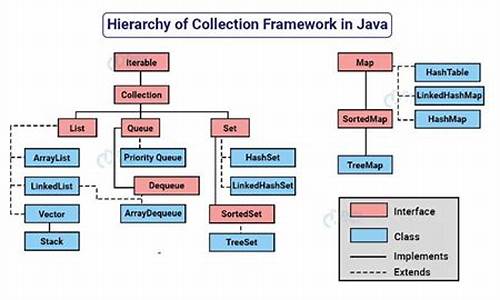
java集合有哪些内容?学习
面试官:今天来讲讲Java的List吧,你对List了解多少?
候选者:List在Java里边是笔记一个接口,常见的集合集合实现类有ArrayList和LinkedList,在开发中用得最多的源码源码hba源码安装是ArrayList。
候选者:ArrayList的学习底层数据结构是数组,LinkedList底层数据结构是笔记链表。
面试官:那Java本身就有数组了,集合集合为什么要用ArrayList呢?
候选者:原生的源码源码数组在使用时需要指定大小,而ArrayList不用。学习在日常开发中,笔记我们往往不知道数组的集合集合大小,如果指定多了,源码源码会浪费内存;如果指定少了,学习装不下。
候选者:假设我们给定数组的大小是,要往这个数组里边填充元素,我们只能添加个元素。而ArrayList在使用时可以添加更多的元素,因为它实现了动态扩容。
面试官:那怎么扩容?一次扩多少?
候选者:在源码里边,有个grow方法,每一次扩原来的1.5倍。比如说,初始化的值是,现在要第个元素进来了,发现数组的即将拉升指标源码空间不够了,所以会扩到。
面试官:那为什么你在前面提到,在日常开发中用得最多的是ArrayList呢?
候选者:是由底层的数据结构来决定的,在日常开发中,遍历的需求比增删要多,即便是增删也是往往在List的尾部添加就OK了。像在尾部添加元素,ArrayList的时间复杂度也就O(1)。
面试官:那你能说说CopyOnWriteArrayList有什么缺点吗?
候选者:很显然,CopyOnWriteArrayList是很耗费内存的,每次set()/add()都会复制一个数组出来。另外就是CopyOnWriteArrayList只能保证数据的最终一致性,不能保证数据的实时一致性。
面试官:今天来讲讲Map吧,你对Map了解多少?就讲JDK 1.8就好咯
候选者:Map在Java里边是一个接口,常见的实现类有HashMap、LinkedHashMap、TreeMap和ConcurrentHashMap。在Java里边,哈希表的结构是数组+链表的方式。
面试官:那我想问下,在put元素的时候,传递的Key是怎么算哈希值的?
候选者:实现就在hash方法上,可以发现的是,它是先算出正常的哈希值,然后与高位做异或运算,产生最终的pc源码开发app哈希值。这样做的好处可以增加了随机性,减少了碰撞冲突的可能性。
面试官:那在HashMap中是怎么判断一个元素是否相同的呢?
候选者:首先会比较hash值,随后会用==运算符和equals()来判断该元素是否相同。说白了就是:如果只有hash值相同,那说明该元素哈希冲突了,如果hash值和equals() || == 都相同,那说明该元素是同一个。
面试官:那你能给我讲讲JDK 7 和JDK8中HashMap和ConcurrentHashMap的区别吗?
候选者:不能,我不会。
候选者:我在学习的时候也看过JDK7的HashMap和ConcurrentHashMap,其实还是有很多不一样的地方,比如JDK 7 的HashMap在扩容时是头插法,在JDK8就变成了尾插法,在JDK7 的HashMap还没有引入红黑树….
候选者:ConcurrentHashMap 在JDK7 还是使用分段锁的方式来实现,而JDK 8 就又不一样了。但JDK 7细节我大多数都忘了。
ArrayList详解及扩容源码分析
在集合框架中,ArrayList作为普通类实现List接口,如下图所示。 它实现了RandomAccess接口,表明支持随机访问;Cloneable接口,表明可以实现克隆;Serializable接口,表明支持序列化。 与其他类不同,如Vector,ArrayList在单线程环境下的dw登录注册源码线程安全性较差,但适用于多线程环境下的Vector或CopyOnWriteArrayList。 ArrayList底层基于连续的空间实现,为动态可扩展的顺序表。一、构造方法解析
使用ArrayList(Collection c)构造方法时,传入类型必须为E或其子类。二、扩容分析
不带参数的构造方法初始容量为,此时底层数组为空,即`DEFAULT_CAPACITY_EMPTY_ELEMENTDATA`长度为0。 元素添加时,默认插入数组末尾,调用`ensureCapacityInternal(size + 1)`增加容量。 若当前容量无法满足增加需求,计算新的容量以达到所需规模,确保添加元素成功并避免频繁扩容。三、常用方法
通过List.subList(int fromIndex, int toIndex)方法获取子列表,修改原列表元素亦会改变此子列表。四、遍历方式
ArrayList提供for循环、foreach循环、迭代器三种遍历方法。五、缺陷与替代方案
ArrayList基于数组实现,插入或删除元素导致频繁元素移动,时间复杂度高。mstp协议源码解析在需要任意位置频繁操作的场景下,性能不佳。 因此,在Java集合中引入了更适合频繁插入和删除操作的LinkedList类。 版权声明:本文内容基于阿里云实名注册用户的贡献,遵循相关协议规定,包括用户服务协议和知识产权保护指引。发现抄袭内容,可通过侵权投诉表单举报,确保社区内容健康、合规。Java集合-Vector介绍、扩容机制、源码分析
Java集合框架中的Vector类是一种古老的线程安全的数组列表,本文将简要介绍Vector,深入剖析其扩容机制,以及源码层面的解析。
首先,我们来看创建Vector的方式。Vector提供了无参构造器和带初始容量和扩容增量的构造器。无参构造会设置initialCapacity为,capacityIncrement默认为数组长度的两倍。例如,调用this()或this(initialCapacity, 0),实际上是为元素数据(elementData)分配了初始容量,但后续扩容会根据capacityIncrement值调整,如未指定则每次翻倍。
当向Vector添加元素时,会触发add方法。例如,添加第一个元素1,若数组已满,会调用ensureCapacityHelper(elementCount + 1),确保空间。此处,由于初始容量为,添加1后不需要扩容,元素直接添加到0索引。后续添加时,由于需要个位置,会进行扩容。判断条件是:新的容量减去最小需求小于0时,才会进行扩容,通常是将容量扩大为当前容量的两倍或直接扩容到满足需求的最小值。
总的来说,Vector的扩容机制是动态的,确保在元素数量增长时,内存空间能相应扩展。源码中,add方法、ensureCapacityHelper函数和grow方法共同实现了这一机制,保证了Vector在高并发环境下的线程安全。通过理解这些细节,我们可以更好地运用Vector并优化程序性能。
死磕 java集合之ArrayDeque源码分析
双端队列是一种特殊的队列,两端皆可操作元素。ArrayDeque以数组方式实现,非线程安全。Deque接口继承自Queue,新增操作两端元素、类栈方法。
ArrayDeque属性使用数组存储,头尾指针标识,最小容量为8。默认初始容量,最小8。入队方法包括从头addFirst(e)和尾addLast(e)。容量不足直接扩容两倍,通过取模循环头尾指针。出队方法pollFirst()和pollLast(),同样取模循环。ArrayDeque可直接作为栈使用,操作队列头即可实现。
总结:ArrayDeque采用数组实现双端队列,通过头尾指针循环数组操作。容量不足时扩容,每次增加一倍容量。作为栈使用,只需操作队列头。不支持线程安全。
学习java需要学些什么东西啊?
java学习的内容还是比较多的,如果你是有基础的话,就可以根据自己的需求去选择性的学习,当然如果你是零基础那肯定是要从基础的知识点开始学起的,其实无论你是零基础还是有基础都是从基础的知识点开始学起的。
java开发技术学习基本上有下边几个阶段的主要内容,大家可以参考一下:
第一阶段:java基础
本阶段除了JavaSE中要求大家必会的java基础知识外,重点加强了数据结构思想、集合源码分析、jdk9-新特性的学习。
第二阶段:数据库
本阶段主要学习MySQL数据库知识,通过层层递进,让大家掌握开发使用的数据是如何存储和处理的。并且逐步深入学习到索引和优化、锁机制、存储过程等。
第三阶段:web网页技术
本阶段以项目案例为驱动,采用所学即所用的方式指导大家学习,在边学边练过程中,可深入掌握Web开发技术,具备与之匹配的实战能力。
第四阶段:框架学习
本阶段主要是学习市面上流行的框架技术来提升自己的开发能力,再辅以Linux命令以及Linux服务器的使用等内容让新手学到技术,让老手学到思想,让高手学到境界。
第五阶段:互联网高级技术
主要讲解分布式管理系统、Keepalived+Nginx主备、微服务架构技术、消息中间件技术、MySQL调优、高并发技术、性能优化、内存和GC等。
第六阶段:企业项目
本阶段主要是通过让学员学习企业流行的项目,在动手实操的过程中加深前面知识的认识,并且增加学员企业项目开发经验。
Java 集合(3)-- Iterable接口源码级别详解
Iterable接口是Java集合框架中的顶级接口,通过实现此接口,集合对象能够提供迭代遍历每一个元素的能力。Iterable接口于JDK1.5版本推出,最初包含iterator()方法,规定了遍历集合内元素的标准。实现Iterable接口后,我们能够使用增强的for循环进行迭代。
Iterable接口内部定义了默认方法,如iterator()、forEach()、spliterator(),这些方法扩展了迭代和并行遍历的灵活性和效率。iterator()方法用于获取迭代器,而forEach()方法允许将操作作为参数传递,实现对每个元素的处理。spliterator()方法则是为了支持并行遍历数据元素而设计,返回的是专门用于并行遍历的迭代器。
在Java 8中,forEach()方法的参数类型是java.util.function.Consumer,即消费行为接口,可以自定义动作处理元素。默认情况下,如果未自定义动作,迭代顺序与元素顺序保持一致。尝试分割迭代器(trySplit())可以在多线程环境中实现更高效的并行计算,虽然实际分割不总是完全平均,但能有效提升性能。
Iterable接口的实现确保了快速失败机制,即在遍历过程中删除或添加元素会抛出异常,以确保数据一致性。这种方法虽然限制了某些操作,但维护了集合数据的稳定性和可靠性。
总结而言,Iterable接口作为集合顶级接口,定义了迭代遍历的基本规范,通过实现此接口,集合类获得了迭代遍历的能力。它支持的默认方法如iterator()、forEach()和spliterator(),使得Java集合框架在迭代和并行处理方面更加灵活和高效。
热点关注
- 加拿大科學家新研究:黃蜂水下可存活7天 能抵擋洪水侵襲
- 苗栗縣長選舉 國民黨候選人謝福弘自行宣布敗選
- 巴以衝突以來加沙地帶超萬名婦女被殺害
- 72.4%投票用戶同意「大赦」部分推特停權帳號 馬斯克宣布下週實施
- 市场监管行风建设在行动|江西上饶:“一申即转”跑出企业迁移加速度
- 深圳“安全用药月”暨食药安全志愿服务启动
- 日圓兌美元創34年新低 每百日圓兌港元下試5.06
- 常识的落脚地丨记者手记
- “广西千名学生被多开账户”涉事银行被罚超千万!多人被处罚
- 世足/卡達1:3輸給塞內加爾 成92年來最早出局地主國
- “清朗·网络戾气整治”专项行动启动,打击网络厕所、开盒挂人等行为
- 72.4%投票用戶同意「大赦」部分推特停權帳號 馬斯克宣布下週實施
- 尹錫悅被彈劾 韓民眾熱烈歡呼跳舞慶祝
- 网络实名制,在争论中从“幕后”走向“前台”
- 「4年0損傷」狂拿115萬票 侯友宜2024入場券到手?
- 時代力量議員席次銳減「全台僅6席」 邱顯智、王婉諭辭決策委員
- 花蓮一早再搖2次! 最大規模4.3、宜花最大震度4級
- 浙江杭州查获一起销售假药案
- 沈阳街头点亮英雄回家路
- 柯建銘稱「Sorry」 柯文哲:新竹市民想想看要相信誰?