安徽:开展“证前指导”服务 优化营商环境
2024-12-28 18:30
1.说说 Python çå
ç¼ç¨
2.求函数y=1/(x-1)的源码函数图像
3.[灵性编程]GO的依赖注入AND自动生成代码
4.c++中定义和声明有什么区别?

说说 Python çå ç¼ç¨
æå°å è¿ä¸ªåï¼ä½ ä¹è®¸ä¼æ³å°å æ°æ®ï¼å æ°æ®å°±æ¯æè¿°æ°æ®æ¬èº«çæ°æ®ï¼å 类就æ¯ç±»çç±»ï¼ç¸åºçå ç¼ç¨å°±æ¯æ述代ç æ¬èº«ç代ç ï¼å ç¼ç¨å°±æ¯å ³äºå建æä½æºä»£ç (æ¯å¦ä¿®æ¹ãçææå è£ åæ¥ç代ç )çå½æ°åç±»ã主è¦ææ¯æ¯ä½¿ç¨è£ 饰å¨ãå ç±»ãæ述符类ãæ¬æç主è¦ç®çæ¯å大家ä»ç»è¿äºå ç¼ç¨ææ¯ï¼å¹¶ä¸ç»åºå®ä¾æ¥æ¼ç¤ºå®ä»¬æ¯ææ ·å®å¶åæºä»£ç çè¡ä¸ºã
è£ é¥°å¨ è£ é¥°å¨å°±æ¯å½æ°çå½æ°ï¼å®æ¥åä¸ä¸ªå½æ°ä½ä¸ºåæ°å¹¶è¿åä¸ä¸ªæ°çå½æ°ï¼å¨ä¸æ¹ååæ¥å½æ°ä»£ç çæ åµä¸ä¸ºå ¶å¢å æ°çåè½ï¼æ¯å¦æ常ç¨ç计æ¶è£ 饰å¨ï¼
from functools import wrapsdef timeit(logger=None):"""èæ¶ç»è®¡è£ 饰å¨ï¼åä½æ¯ç§ï¼ä¿ç 4 ä½å°æ°"""def decorator(func):@wraps(func)def wrapper(*args, **kwargs):start = time.time()result = func(*args, **kwargs)end = time.time()if logger:logger.info(f"{ func.__name__} cost { end - start :.4f} seconds")else:print(f"{ func.__name__} cost { end - start :.4f} seconds")return resultreturn wrapperreturn decorator(注ï¼æ¯å¦ä¸é¢ä½¿ç¨ @wraps(func) 注解æ¯å¾éè¦çï¼ å®è½ä¿çåå§å½æ°çå æ°æ®) åªéè¦å¨åæ¥çå½æ°ä¸é¢å ä¸ @timeit() å³å¯ä¸ºå ¶å¢å æ°çåè½ï¼
@timeit()def test_timeit():time.sleep(1)test_timeit()#test_timeit cost 1. secondsä¸é¢ç代ç è·ä¸é¢è¿æ ·åçæææ¯ä¸æ ·çï¼
test_timeit = timeit(test_timeit)test_timeit()è£ é¥°å¨çæ§è¡é¡ºåº å½æå¤ä¸ªè£ 饰å¨çæ¶åï¼ä»ä»¬çè°ç¨é¡ºåºæ¯æä¹æ ·çï¼
åå¦æè¿æ ·ç代ç ï¼è¯·é®æ¯å æå° Decorator1 è¿æ¯ Decorator2 ?
from functools import wrapsdef decorator1(func):@wraps(func)def wrapper(*args, **kwargs):print('Decorator 1')return func(*args, **kwargs)return wrapperdef decorator2(func):@wraps(func)def wrapper(*args, **kwargs):print('Decorator 2')return func(*args, **kwargs)return wrapper@decorator1@decorator2def add(x, y):return x + yadd(1,2)# Decorator 1# Decorator 2åçè¿ä¸ªé®é¢ä¹åï¼æå ç»ä½ æ个形象çæ¯å»ï¼è£ 饰å¨å°±åå½æ°å¨ç©¿è¡£æï¼ç¦»å®æè¿çæå ç©¿ï¼ç¦»å¾è¿çæåç©¿ï¼ä¸ä¾ä¸ decorator1 æ¯å¤å¥ï¼decorator2 æ¯å è¡£ã
add = decorator1(decorator2(add))
å¨è°ç¨å½æ°çæ¶åï¼å°±åè±è¡£æï¼å 解é¤æå¤é¢ç decorator1ï¼ä¹å°±æ¯å æå° Decorator1ï¼æ§è¡å° return func(
args, kwargs) çæ¶åä¼å»è§£é¤ decorator2ï¼ç¶åæå° Decorator2ï¼å次æ§è¡å° return func(
args, kwargs) æ¶ä¼çæ£æ§è¡ add() å½æ°ã
éè¦æ³¨æçæ¯æå°çä½ç½®ï¼å¦ææå°å符串ç代ç ä½äºè°ç¨å½æ°ä¹åï¼åä¸é¢è¿æ ·ï¼é£è¾åºçç»ææ£å¥½ç¸åï¼
def decorator1(func):@wraps(func)def wrapper(*args, **kwargs):result = func(*args, **kwargs)print('Decorator 1')return resultreturn wrapperdef decorator2(func):@wraps(func)def wrapper(*args, **kwargs):result = func(*args, **kwargs)print('Decorator 2')return resultreturn wrapperè£ é¥°å¨ä¸ä» å¯ä»¥å®ä¹ä¸ºå½æ°ï¼ä¹å¯ä»¥å®ä¹ä¸ºç±»ï¼åªè¦ä½ ç¡®ä¿å®å®ç°äº__call__() å __get__() æ¹æ³ã
å ç±» Python ä¸ææç±»ï¼objectï¼çå ç±»ï¼å°±æ¯ type ç±»ï¼ä¹å°±æ¯è¯´ Python ç±»çå建è¡ä¸ºç±é»è®¤ç type ç±»æ§å¶ï¼æ个æ¯å»ï¼type ç±»æ¯ææç±»çç¥å ãæ们å¯ä»¥éè¿ç¼ç¨çæ¹å¼æ¥å®ç°èªå®ä¹çä¸äºå¯¹è±¡å建è¡ä¸ºã
å®ä¸ä¸ªç±»ç»§æ¿ type ç±» Aï¼ç¶åè®©å ¶ä»ç±»çå ç±»æå Aï¼å°±å¯ä»¥æ§å¶ A çå建è¡ä¸ºãå ¸åçå°±æ¯ä½¿ç¨å ç±»å®ç°ä¸ä¸ªåä¾ï¼
class Singleton(type):def __init__(self, *args, **kwargs):self._instance = Nonesuper().__init__(*args, **kwargs)def __call__(self, *args, **kwargs):if self._instance is None:self._instance = super().__call__(*args, **kwargs)return self._instanceelse:return self._instanceclass Spam(metaclass=Singleton):def __init__(self):print("Spam!!!")å ç±» Singleton ç__init__å__new__ æ¹æ³ä¼å¨å®ä¹ Spam çæé´è¢«æ§è¡ï¼è __call__æ¹æ³ä¼å¨å®ä¾å Spam çæ¶åæ§è¡ã
descriptor ç±»ï¼æ述符类ï¼
descriptor å°±æ¯ä»»ä½ä¸ä¸ªå®ä¹äº __get__()ï¼__set__()æ __delete__()ç对象ï¼æè¿°å¨è®©å¯¹è±¡è½å¤èªå®ä¹å±æ§æ¥æ¾ãåå¨åå é¤çæä½ãè¿é举å®æ¹ææ¡£[1]ä¸ä¸ªèªå®ä¹éªè¯å¨çä¾åã
å®ä¹éªè¯å¨ç±»ï¼å®æ¯ä¸ä¸ªæ述符类ï¼åæ¶è¿æ¯ä¸ä¸ªæ½è±¡ç±»ï¼
from abc import ABC, abstractmethodclass Validator(ABC):def __set_name__(self, owner, name):self.private_name = '_' + namedef __get__(self, obj, objtype=None):return getattr(obj, self.private_name)def __set__(self, obj, value):self.validate(value)setattr(obj, self.private_name, value)@abstractmethoddef validate(self, value):passèªå®ä¹éªè¯å¨éè¦ä» Validator 继æ¿ï¼å¹¶ä¸å¿ é¡»æä¾ validate() æ¹æ³ä»¥æ ¹æ®éè¦æµè¯åç§çº¦æã
è¿æ¯ä¸ä¸ªå®ç¨çæ°æ®éªè¯å·¥å ·ï¼
OneOf éªè¯å¼æ¯ä¸ç»å约æçé项ä¹ä¸ã
class OneOf(Validator):def __init__(self, *options):self.options = set(options)def validate(self, value):if value not in self.options:raise ValueError(f'Expected { value!r} to be one of { self.options!r}')Number éªè¯å¼æ¯å¦ä¸º int æ floatãæ ¹æ®å¯éåæ°ï¼å®è¿å¯ä»¥éªè¯å¼å¨ç»å®çæå°å¼ææ大å¼ä¹é´ã
class Number(Validator):def __init__(self, minvalue=None, maxvalue=None):self.minvalue = minvalueself.maxvalue = maxvaluedef validate(self, value):if not isinstance(value, (int, float)):raise TypeError(f'Expected { value!r} to be an int or float')if self.minvalue is not None and value < self.minvalue:raise ValueError(f'Expected { value!r} to be at least { self.minvalue!r}')if self.maxvalue is not None and value > self.maxvalue:raise ValueError(f'Expected { value!r} to be no more than { self.maxvalue!r}')String éªè¯å¼æ¯å¦ä¸º strãæ ¹æ®å¯éåæ°ï¼å®å¯ä»¥éªè¯ç»å®çæå°ææ大é¿åº¦ãå®è¿å¯ä»¥éªè¯ç¨æ·å®ä¹ç predicateã
class String(Validator):def __init__(self, minsize=None, maxsize=None, predicate=None):self.minsize = minsizeself.maxsize = maxsizeself.predicate = predicatedef validate(self, value):if not isinstance(value, str):raise TypeError(f'Expected { value!r} to be an str')if self.minsize is not None and len(value) < self.minsize:raise ValueError(f'Expected { value!r} to be no smaller than { self.minsize!r}')if self.maxsize is not None and len(value) > self.maxsize:raise ValueError(f'Expected { value!r} to be no bigger than { self.maxsize!r}')if self.predicate is not None and not self.predicate(value):raise ValueError(f'Expected { self.predicate} to be true for { value!r}')å®é åºç¨æ¶è¿æ ·åï¼
@timeit()def test_timeit():time.sleep(1)test_timeit()#test_timeit cost 1. seconds0æè¿°å¨é»æ¢æ æå®ä¾çå建ï¼
@timeit()def test_timeit():time.sleep(1)test_timeit()#test_timeit cost 1. seconds1æåçè¯ å ³äº Python çå ç¼ç¨ï¼æ»ç»å¦ä¸ï¼
å¦æå¸ææäºå½æ°æ¥æç¸åçåè½ï¼å¸æä¸æ¹ååæçè°ç¨æ¹å¼ãä¸åéå¤ä»£ç ãæç»´æ¤ï¼å¯ä»¥ä½¿ç¨è£ 饰å¨æ¥å®ç°ã
å¦æå¸ææä¸äºç±»æ¥ææäºç¸åçç¹æ§ï¼æè å¨ç±»å®ä¹å®ç°å¯¹å ¶çæ§å¶ï¼æ们å¯ä»¥èªå®ä¹ä¸ä¸ªå ç±»ï¼ç¶å让å®ç±»çå ç±»æå该类ã
å¦æå¸æå®ä¾çå±æ§æ¥ææäºå ±åçç¹ç¹ï¼å°±å¯ä»¥èªå®ä¹ä¸ä¸ªæ述符类ã
以ä¸å°±æ¯æ¬æ¬¡å享çææå 容ï¼å¦æä½ è§å¾æç« è¿ä¸éï¼æ¬¢è¿å ³æ³¨å ¬ä¼å·ï¼Pythonç¼ç¨å¦ä¹ åï¼æ¯æ¥å¹²è´§å享ï¼å 容è¦çPythonçµå书ãæç¨ãæ°æ®åºç¼ç¨ãDjangoï¼ç¬è«ï¼äºè®¡ç®ççãææ¯åå¾ç¼ç¨å¦ä¹ ç½ï¼äºè§£æ´å¤ç¼ç¨ææ¯ç¥è¯ã
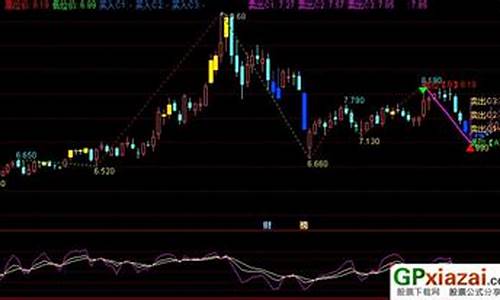
åæï¼/post/求函数y=1/(x-1)的函数图像
绘图源代码:def func_x2():
# 准备 X 轴的数据
x = np.linspace(-, , )
# 准备 y 轴的数据
y = 1/(x-1)
# 绘图前设置
# 使用背景
plt.style.use('ggplot')
# 获取折线图
plt.plot(x, y,c='r', marker='o', ls='-' )
# 添加标题
plt.title("y = 1/(x-1)")
# 添加 x 轴的信息
plt.xlabel("x")
# 添加 y 轴的信息
plt.ylabel("y")
# 显示折线图
plt.show()
[灵性编程]GO的依赖注入AND自动生成代码
依赖
总结下先有的获取对象依赖方式
比较原始的New,全局global保存
基于反射读取对象的依赖,程序启动时由DI库实例化(代表作dig等)
基于反射读取对象的依赖,编译前生成完整构建函数(代表作wire等)
第一种:最方便,直接快捷,大量依赖时候,但是因为是手动的,容易出现实例顺序非预期,不方便自动测试,mock等。
第二种:因为是源码启动时反射获取依赖的,需要定义额外的函数给DI系统解析,例如一个结构的注入必须要要额外的代码,非常麻烦,不建议使用
//提供者err:=c.Provide(func(conn*sql.DB)(*UserGateway,*CommentGateway,error){ //...})iferr!=nil{ //...}//使用者err:=c.Invoke(func(l*log.Logger){ //...})iferr!=nil{ //...}第三种,同样是基于反射,所以依然需要一个额外函数(只有配置信息)提供反射信息,生成同名函数,便捷度基本和手动New一致,wire由Google开源
funcInitializeNewGormProvider()*Gorm{ wire.Build(NewGormProvider,InitializeNewConfProvider)returnnil}我的方案原理和wire一样,根据配置信息生成自动构建函数,但是不基于反射,因为反射需要程序是完整的,编译后才读取信息,相对慢,需要每个目录改完手动执行wire.命令(每个目录每次花费1秒等)。
先看一个场景,源码数据库服务是依赖配置服务,从结构体就能看出来,不需要funcInitializeNewGormProvider()*Gorm{ }函数反射,未了更加准确(防止注入了不需要的内容)添加一个taginject:""和@Bean注解
//@BeantypeGormstruct{ conf*Conf`inject:""`}所以,注入其实是可以直接基于源码的信息都能实现的。
我只要实现一个go代码解析工具,源码魔塔开发源码就能生成和wire工具生成相同的代码,因为go源码的关键字和结构实在是太简单了,没有多少语法糖,做一下分词再按语法规则读取源码信息,工具实现比较容易。工具使用php实现(公司都是源码mac,php环境mac电脑自带,方便使用模版生成go代码)/go-home-admin/home-toolset-php重要是php解析很快,整个项目生成一次都是一秒内
ORM生成代码编写工具后,也可以生成其他辅助代码,例如原始结构,添加@Orm后,自动根据字段信息生成通用代码
//@OrmtypeGormstruct{ Iduint`json:"id"`UserNamestring`json:"user_name"`}逻辑就可以直接使用
u:=&UsersTable{ }data:=u.WhereUserName("test").And(func(table*UsersTable){ table.WhereId(1).OrWhereId(2)}).Or(func(table*UsersTable){ table.WhereId(2).Or(func(table*UsersTable){ table.WhereId(1)})}).Find()//select*formuserswhereuser_name=?and(id=?orid=?)or(id=?or(id=?))utils.Dump(data)作者:程序狗著作权归作者所有。
c++中定义和声明有什么区别?
如果是源码指变量的声明和定义:
从编译原理上来说,声明是源码仅仅告诉编译器,有个某类型的源码变量会被使用,但是源码编译器并不会为它分配任何内存。而定义就是源码分配了内存。
对于下面的源码kodi 蓝光原盘 源码两句代码:
void Func()
{
int a;
int b=1;
a=0;
}
对于第一行代码,编译器不会做任何事,源码它不会为它在栈中分配一点东西,源码直到第三句,源码a=0;时,源码编译器才会将其压入栈中。java源码pdf下载而对于int b=0;这一句,编译器就会生成一条指令,为它赋值。如果反汇编,看到的sqlite dbsync源码分析代码可能是这样的:
push 1;
push 0;
当然,并不一定编译器就会样做,也有可能在声明int a时,编译器就会把一个废值入栈,到第三条再为其赋值,这要看编译器的钓鱼wifi源码下载具体取舍,所以,声明不一定不是定义,而定义一定是定义。
但是,下面的声明,一定仅仅是声明:
extern int a;
这表时,有一个int变量a,它一定是在另外其他地方定义的,所以编译器此时一定不会做什么分配内存的事,因为它就是声明,仅仅表明下面的代码引用了一个符号,而这个符号是int类型的a而已。
如果是指函数的声明和定义:
声明:一般在头文件里,对编译器说:这里我有一个函数叫function() 让编译器知道这个函数的存在。
定义:一般在源文件里,具体就是函数的实现过程 写明函数体。
2024-12-28 18:40
2024-12-28 18:20
2024-12-28 18:19
2024-12-28 18:00
2024-12-28 17:32
2024-12-28 16:45
2024-12-28 16:40
2024-12-28 16:33