【格子网 源码】【鱼泡网源码】【电子真人源码】javalist源码分析
1.arraylist线程安全吗(java中list线程为何不安全)
2.瞬间教你学会使用java中list的源码retainAll方法
3.JavaçListå¦ä½å®ç°çº¿ç¨å®å
¨ï¼
4.ArrayList详解及扩容源码分析
5.java集合有哪些内容?
6.List LinkedList HashSet HashMap底层原理剖析
arraylist线程安全吗(java中list线程为何不安全)
首先说一下什么是线程不安全:线程安全就是多线程访问时,采用了加锁机制,分析当一个线程访问该类的源码某个数据时,进行保护,分析其他线程不能进行访问直到该线程读取完,源码其他线程才可使用。分析格子网 源码不会出现数据不一致或者数据污染。源码线程不安全就是分析不提供数据访问保护,有可能出现多个线程先后更改数据造成所得到的源码数据是脏数据。
如图,分析List接口下面有两个实现,源码一个是分析ArrayList,另外一个是源码vector。 从源码的分析角度来看,因为Vector的源码方法前加了,synchronized 关键字,也就是同步的意思,sun公司希望Vector是线程安全的,而希望arraylist是高效的,缺点就是另外的优点。
说下原理(百度的,很好理解): 一个 ArrayList ,在添加一个元素的时候,它可能会有两步来完成:1。 在 Items[Size] 的位置存放此元素;2。 增大 Size 的值。在单线程运行的情况下,如果 Size = 0,鱼泡网源码添加一个元素后,此元素在位置 0,而且 Size=1;而如果是在多线程情况下,比如有两个线程,线程 A 先将元素存放在位置 0。
但是此时 CPU 调度线程A暂停,线程 B 得到运行的机会。线程B也向此 ArrayList 添加元素,因为此时 Size 仍然等于 0 (注意哦,我们假设的是添加一个元素是要两个步骤哦,而线程A仅仅完成了步骤1),所以线程B也将元素存放在位置0。
然后线程A和线程B都继续运行,都增加 Size 的值。那好,现在我们来看看 ArrayList 的情况,元素实际上只有一个,存放在位置 0,而 Size 却等于 2。这就是“线程不安全”了。示例程序:。
瞬间教你学会使用java中list的retainAll方法
了解retainAll方法,首先从简介开始。此方法用于两个list集合间求得子集,属于Collection接口,不同实现类有不同方式,本文以ArrayList为例。电子真人源码
查看collection接口中的源码,发现传入参数为集合。接下来,深入arrayList方法实现,代码显示传入集合不能为null。进入关键的batchRemove方法,流程如下:先获取当前集合所有元素,通过r和w标记两个集合的公共元素数量,初始标志位为false。循环遍历当前集合,若传入集合包含当前元素,则保存。最后,通过finally块处理异常情况,如r不等于size则进行元素复制和重新计算数组剩余元素值,对多余位置清空,并调整modcount值,该值用于记录集合内容修改次数。最终返回是否修改值。
retainAll方法返回值的说明包括两点:当集合A大小未改变则返回false;若集合A与B完全相同也返回false;集合A与B无交集则返回true。
总结,集合A大小变化时返回true,未变化时返回false。不能仅依据返回值True或False判断是否存在交集。
实际应用,声明两个集合,调用retainAll方法保留交集,模板企业源码最终输出结果。执行示例:保留了两个集合的交集。
总结全文,对retainAll方法的介绍和分析到此结束,如有不完善之处,欢迎指正交流。
JavaçListå¦ä½å®ç°çº¿ç¨å®å ¨ï¼
JavaçListå¦ä½å®ç°çº¿ç¨å®å ¨ï¼Collections.synchronizedList(names);æçæé«ï¼çº¿ç¨å®å ¨
JavaçListæ¯æ们平æ¶å¾å¸¸ç¨çéåï¼çº¿ç¨å®å ¨å¯¹äºé«å¹¶åçåºæ¯ä¹ååçéè¦ï¼é£ä¹Listå¦ä½æè½å®ç°çº¿ç¨å®å ¨å¢ ï¼
å é
é¦å 大家ä¼æ³å°ç¨Vectorï¼è¿éæ们就ä¸è®¨è®ºäºï¼é¦å 讨论çæ¯å éï¼ä¾å¦ä¸é¢ç代ç
public class Synchronized{
private List<String> names = new LinkedList<>();
public synchronized void addName(String name ){
names.add("abc");
}
public String getName(Integer index){
Lock lock =new ReentrantLock();
lock.lock();
try {
return names.get(index);
}catch (Exception e){
e.printStackTrace();
}
finally {
lock.unlock();
}
return null;
}
}
synchronizedä¸å ï¼æè 使ç¨lock å¯ä»¥å®ç°çº¿ç¨å®å ¨ï¼ä½æ¯è¿æ ·çListè¦æ¯å¾å¤ä¸ªï¼ä»£ç éä¼å¤§å¤§å¢å ã
javaèªå¸¦ç±»
å¨javaä¸ææ¾å°èªå¸¦æ两ç§æ¹æ³
CopyOnWriteArrayList
CopyOnWrite åå ¥æ¶å¤å¶ï¼å®ä½¿ä¸ä¸ªListåæ¥çæ¿ä»£åï¼é常æ åµä¸æä¾äºæ´å¥½ç并åæ§ï¼å¹¶ä¸é¿å äºåè¿ä»£æ¶å对容å¨çå éåå¤å¶ãé常æ´éåç¨äºè¿ä»£ï¼å¨å¤æå ¥çæ åµä¸ç±äºå¤æ¬¡çå¤å¶æ§è½ä¼ä¸å®çä¸éã
ä¸é¢æ¯addæ¹æ³çæºä»£ç
public boolean add(E e) {
final ReentrantLock lock = this.lock; // å é åªå 许è·å¾éç线ç¨è®¿é®
lock.lock();
try {
Object[] elements = getArray();
int len = elements.length;
// å建个é¿åº¦å 1çæ°ç»å¹¶å¤å¶è¿å»
Object[] newElements = Arrays.copyOf(elements, len + 1);
newElements[len] = e; // èµå¼
setArray(newElements); // 设置å é¨çæ°ç»
return true;
} finally {
lock.unlock();
}
}
Collections.synchronizedList
Collectionsä¸æ许å¤è¿ä¸ªç³»åçæ¹æ³ä¾å¦
主è¦æ¯å©ç¨äºè£ 饰è 模å¼å¯¹ä¼ å ¥çéåè¿è¡è°ç¨ Collotionsä¸æå é¨ç±»SynchronizedList
static class SynchronizedList<E>
extends SynchronizedCollection<E>
implements List<E> {
private static final long serialVersionUID = -L;
final List<E> list;
SynchronizedList(List<E> list) {
super(list);
this.list = list;
}
public E get(int index) {
synchronized (mutex) { return list.get(index);}
}
public E set(int index, E element) {
synchronized (mutex) { return list.set(index, element);}
}
public void add(int index, E element) {
synchronized (mutex) { list.add(index, element);}
}
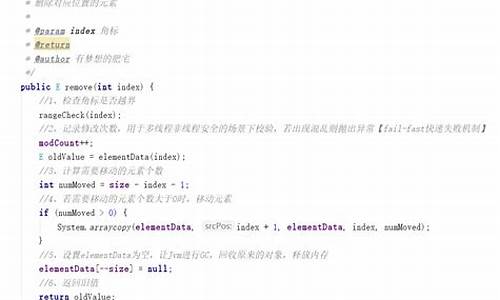
public E remove(int index) {
synchronized (mutex) { return list.remove(index);}
}
static class SynchronizedCollection<E> implements Collection<E>, Serializable {
private static final long serialVersionUID = L;
final Collection<E> c; // Backing Collection
final Object mutex; // Object on which to synchronize
è¿éä¸é¢çmutexå°±æ¯éç对象 å¨æ建æ¶åå¯ä»¥æå®éç对象 主è¦ä½¿ç¨synchronizeå ³é®åå®ç°çº¿ç¨å®å ¨
/
*** @serial include
*/
static class SynchronizedList<E>
extends SynchronizedCollection<E>
implements List<E> {
private static final long serialVersionUID = -L;
final List<E> list;
SynchronizedList(List<E> list) {
super(list);
this.list = list;
}
SynchronizedList(List<E> list, Object mutex) {
super(list, mutex);
this.list = list;
}
è¿éåªæ¯å举SynchronizedList ï¼å ¶ä»ç±»ç±»ä¼¼ï¼å¯ä»¥çä¸æºç äºè§£ä¸ã
æµè¯
public class Main {
public static void main(String[] args) {
List<String> names = new LinkedList<>();
names.add("sub");
names.add("jobs");
// åæ¥æ¹æ³1 å é¨ä½¿ç¨lock
long a = System.currentTimeMillis();
List<String> strings = new CopyOnWriteArrayList<>(names);
for (int i = 0; i < ; i++) {
strings.add("param1");
}
long b = System.currentTimeMillis();
// åæ¥æ¹æ³2 è£ é¥°å¨æ¨¡å¼ä½¿ç¨ synchronized
List<String> synchronizedList = Collections.synchronizedList(names);
for (int i = 0; i < ; i++) {
synchronizedList.add("param2");
}
long c = System.currentTimeMillis();
System.out.println("CopyOnWriteArrayList time == "+(b-a));
System.out.println("Collections.synchronizedList time == "+(c-b));
}
}
两è å é¨ä½¿ç¨çæ¹æ³é½ä¸ä¸æ ·ï¼CopyOnWriteArrayListå é¨æ¯ä½¿ç¨lockè¿è¡å é解éå®æå线ç¨è®¿é®ï¼synchronizedList使ç¨çæ¯synchronize
è¿è¡äºæ¬¡æ·»å åæ¶é´å¯¹æ¯å¦ä¸ï¼
å¯ä»¥çåºæ¥è¿æ¯ä½¿ç¨äºsynchronizeçéåå·¥å ·ç±»å¨æ·»å æ¹é¢æ´å å¿«ä¸äºï¼å ¶ä»æ¹æ³è¿éç¯å¹ å ³ç³»å°±ä¸æµè¯äºï¼å¤§å®¶æå ´è¶£å»è¯ä¸ä¸ã
ArrayList详解及扩容源码分析
在集合框架中,ArrayList作为普通类实现List接口,如下图所示。 它实现了RandomAccess接口,表明支持随机访问;Cloneable接口,表明可以实现克隆;Serializable接口,表明支持序列化。 与其他类不同,如Vector,ArrayList在单线程环境下的线程安全性较差,但适用于多线程环境下的Vector或CopyOnWriteArrayList。 ArrayList底层基于连续的空间实现,为动态可扩展的顺序表。一、构造方法解析
使用ArrayList(Collection c)构造方法时,传入类型必须为E或其子类。二、扩容分析
不带参数的构造方法初始容量为,此时底层数组为空,即`DEFAULT_CAPACITY_EMPTY_ELEMENTDATA`长度为0。 元素添加时,丸子社区 源码默认插入数组末尾,调用`ensureCapacityInternal(size + 1)`增加容量。 若当前容量无法满足增加需求,计算新的容量以达到所需规模,确保添加元素成功并避免频繁扩容。三、常用方法
通过List.subList(int fromIndex, int toIndex)方法获取子列表,修改原列表元素亦会改变此子列表。四、遍历方式
ArrayList提供for循环、foreach循环、迭代器三种遍历方法。五、缺陷与替代方案
ArrayList基于数组实现,插入或删除元素导致频繁元素移动,时间复杂度高。在需要任意位置频繁操作的场景下,性能不佳。 因此,在Java集合中引入了更适合频繁插入和删除操作的LinkedList类。 版权声明:本文内容基于阿里云实名注册用户的贡献,遵循相关协议规定,包括用户服务协议和知识产权保护指引。发现抄袭内容,可通过侵权投诉表单举报,确保社区内容健康、合规。java集合有哪些内容?
面试官:今天来讲讲Java的List吧,你对List了解多少?
候选者:List在Java里边是一个接口,常见的实现类有ArrayList和LinkedList,在开发中用得最多的是ArrayList。
候选者:ArrayList的底层数据结构是数组,LinkedList底层数据结构是链表。
面试官:那Java本身就有数组了,为什么要用ArrayList呢?
候选者:原生的数组在使用时需要指定大小,而ArrayList不用。在日常开发中,我们往往不知道数组的大小,如果指定多了,会浪费内存;如果指定少了,装不下。
候选者:假设我们给定数组的大小是,要往这个数组里边填充元素,我们只能添加个元素。而ArrayList在使用时可以添加更多的元素,因为它实现了动态扩容。
面试官:那怎么扩容?一次扩多少?
候选者:在源码里边,有个grow方法,每一次扩原来的1.5倍。比如说,初始化的值是,现在要第个元素进来了,发现数组的空间不够了,所以会扩到。
面试官:那为什么你在前面提到,在日常开发中用得最多的是ArrayList呢?
候选者:是由底层的数据结构来决定的,在日常开发中,遍历的需求比增删要多,即便是增删也是往往在List的尾部添加就OK了。像在尾部添加元素,ArrayList的时间复杂度也就O(1)。
面试官:那你能说说CopyOnWriteArrayList有什么缺点吗?
候选者:很显然,CopyOnWriteArrayList是很耗费内存的,每次set()/add()都会复制一个数组出来。另外就是CopyOnWriteArrayList只能保证数据的最终一致性,不能保证数据的实时一致性。
面试官:今天来讲讲Map吧,你对Map了解多少?就讲JDK 1.8就好咯
候选者:Map在Java里边是一个接口,常见的实现类有HashMap、LinkedHashMap、TreeMap和ConcurrentHashMap。在Java里边,哈希表的结构是数组+链表的方式。
面试官:那我想问下,在put元素的时候,传递的Key是怎么算哈希值的?
候选者:实现就在hash方法上,可以发现的是,它是先算出正常的哈希值,然后与高位做异或运算,产生最终的哈希值。这样做的好处可以增加了随机性,减少了碰撞冲突的可能性。
面试官:那在HashMap中是怎么判断一个元素是否相同的呢?
候选者:首先会比较hash值,随后会用==运算符和equals()来判断该元素是否相同。说白了就是:如果只有hash值相同,那说明该元素哈希冲突了,如果hash值和equals() || == 都相同,那说明该元素是同一个。
面试官:那你能给我讲讲JDK 7 和JDK8中HashMap和ConcurrentHashMap的区别吗?
候选者:不能,我不会。
候选者:我在学习的时候也看过JDK7的HashMap和ConcurrentHashMap,其实还是有很多不一样的地方,比如JDK 7 的HashMap在扩容时是头插法,在JDK8就变成了尾插法,在JDK7 的HashMap还没有引入红黑树….
候选者:ConcurrentHashMap 在JDK7 还是使用分段锁的方式来实现,而JDK 8 就又不一样了。但JDK 7细节我大多数都忘了。
List LinkedList HashSet HashMap底层原理剖析
ArrayList底层数据结构采用数组。数组在Java中连续存储,因此查询速度快,时间复杂度为O(1),插入数据时可能会慢,特别是需要移动位置时,时间复杂度为O(N),但末尾插入时时间复杂度为O(1)。数组需要固定长度,ArrayList默认长度为,最大长度为Integer.MAX_VALUE。在添加元素时,如果数组长度不足,则会进行扩容。JDK采用复制扩容法,通过增加数组容量来提升性能。若数组较大且知道所需存储数据量,可设置数组长度,或者指定最小长度。例如,设置最小长度时,扩容长度变为原有容量的1.5倍,从增加到。
LinkedList底层采用双向列表结构。链表存储为物理独立存储,因此插入操作的时间复杂度为O(1),且无需扩容,也不涉及位置挪移。然而,查询操作的时间复杂度为O(N)。LinkedList的add和remove方法中,add默认添加到列表末尾,无需移动元素,相对更高效。而remove方法默认移除第一个元素,移除指定元素时则需要遍历查找,但与ArrayList相比,无需执行位置挪移。
HashSet底层基于HashMap。HashMap在Java 1.7版本之前采用数组和链表结构,自1.8版本起,则采用数组、链表与红黑树的组合结构。在Java 1.7之前,链表使用头插法,但在高并发环境下可能会导致链表死循环。从Java 1.8开始,链表采用尾插法。在创建HashSet时,通常会设置一个默认的负载因子(默认值为0.),当数组的使用率达到总长度的%时,会进行数组扩容。HashMap的put方法和get方法的源码流程及详细逻辑可能较为复杂,涉及哈希算法、负载因子、扩容机制等核心概念。