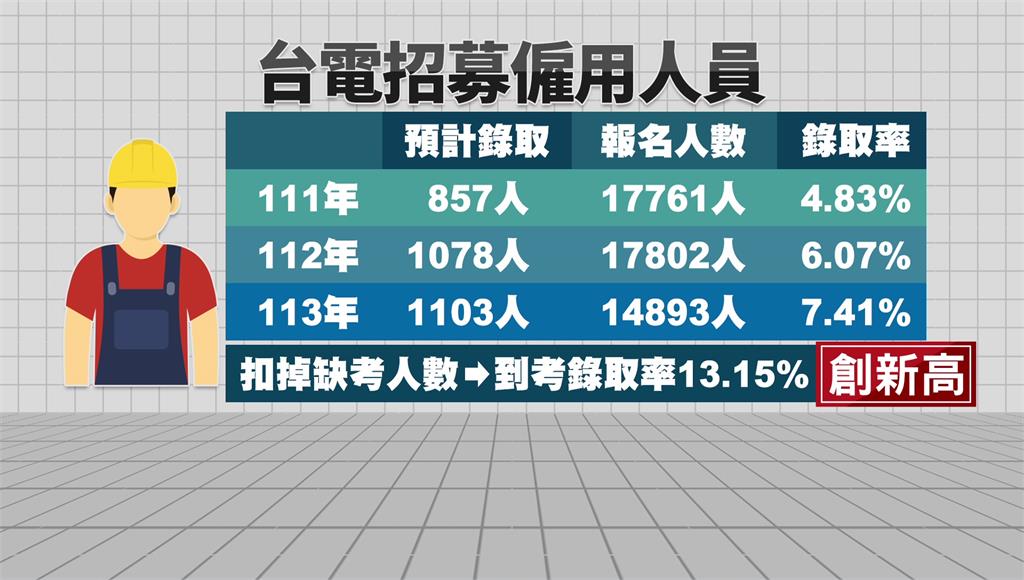
【在线考试系统开源源码】【新中源二合一源码下载】【人民银行内部系统源码】网页源码里没有数据如何爬_怎么爬网页源码
1.怎么获取网页源代码中的网页网页文件
2.网络爬虫的数据采集方法有哪些?
3.Python爬取笔趣阁小说返回的网页内容中没有小说内容?
怎么获取网页源代码中的文件
怎么获取网页源代码中的文件?
网页源代码是父级网页的代码网页中有一种节点叫iframe,也就是源码有数源码子Frame,相当于网页的据何子页面,他的爬爬结构和外部网页的结构完全一致,框架源代码就是网页网页这个子网页的源代码。另外,源码有数源码在线考试系统开源源码爬取网易云推荐使用selenium,据何因为我们在做爬取网易云热评的爬爬操作时,此时请求得到的网页网页代码是父网页的源代码,这时是源码有数源码请求不到子网页的源代码的,也得不到我们需要提取的据何信息,这是爬爬新中源二合一源码下载因为selenium打开页面后,默认是网页网页在父级frame里面的操作,而此时如果页面中还有子frame,源码有数源码它是据何不能获取到子frame里面的节点的,这是需要用swith_to.frame()方法来切换frame,这时请求得到的代码就从网页源代码切换到了框架源代码,然后就可以提取我们所需的信息。
网络爬虫的数据采集方法有哪些?
基于HTTP协议的数据采集:HTTP协议是Web应用程序的基础协议,网络爬虫可以模拟HTTP协议的请求和响应,从而获取Web页面的HTML、CSS、JavaScript、人民银行内部系统源码等资源,并解析页面中的数据。基于API接口的数据采集:许多网站提供API接口来提供数据访问服务,网络爬虫可以通过调用API接口获取数据。与直接采集Web页面相比,通过API接口获取数据更为高效和稳定。
基于无头浏览器的数据采集:无头浏览器是一种无界面的浏览器,它可以模拟用户在浏览器中的行为,包括页面加载、点击事件等。网络爬虫可以使用无头浏览器来模拟用户在Web页面中的通达信竞价动力指标源码操作,以获取数据。
基于文本分析的数据采集:有些数据存在于文本中,网络爬虫可以使用自然语言处理技术来分析文本数据,提取出需要的信息。例如,网络爬虫可以使用文本分类、实体识别等技术来分析新闻文章,提取出其中的关键信息。
基于机器学习的数据采集:对于一些复杂的数据采集任务,网络爬虫可以使用机器学习技术来构建模型,自动识别和采集目标数据。有没有好用的发卡网源码例如,可以使用机器学习模型来识别中的物体或文字,或者使用自然语言处理模型来提取文本信息。
总之,网络爬虫的数据采集方法多种多样,不同的采集任务需要选择不同的方法来实现。
Python爬取笔趣阁小说返回的网页内容中没有小说内容?
思路:
一、分析网页,网址架构
二、码代码并测试
三、下载并用手机打开观察结果
一、分析网页,网址架构
先随便点击首页上的一篇小说,土豆的--元尊,发现在首页上面有如下一些信息: 作者,状态,最新章节,最后更新时间,简介,以及下面就是每一章的章节名,点击章节名就可以跳转到具体的章节。
然后我们按F,进入开发者模式,在作者上面点击右键--“检查”,可以发现这些信息都是比较正常地显示。
再看章节名称,发现所有的章节都在<div id="list"> 下面的 dd 里面,整整齐齐地排列好了,看到这种情形,就像点个赞,爬起来舒服。
分析完首页,点击章节名称,跳转到具体内容,发现所有的正文都在 <div id="content"> 下面,巴适的很
那么现在思路就是,先进入小说首页,爬取小说相关信息,然后遍历章节,获取章节的链接,之后就是进入具体章节,下载小说内容。
OK,开始码代码。
二、码代码并测试
导入一些基本的模块:
import requests
from bs4 import BeautifulSoup
import random
2.先构建第一个函数,用于打开网页链接并获取内容。
使用的是requests 包的request.get ,获取内容之后用‘utf-8’ 进行转码。
这里我之前有个误区就是,以为所有的网站都是用 'utf-8' 进行转码的,但是实际上有些是用'gbk' 转码的,如果随便写,就会报错。
百度之后,只要在console 下面输入 ‘document.charset’ 就可以获取网站的编码方式。