1.深入浅出 MyBatis 缓存缓存的一级、二级缓存机制
2.④优雅的机制机制缓存框架:SpringCache之多级缓存
3.Chromium源码剖析:HTTP缓存策略与架构
4.python中的垃圾回收机制和缓存机制
5.开源即时通讯GGTalk源码剖析之:客户端全局缓存及本地存储
深入浅出 MyBatis 的一级、二级缓存机制
深入浅出 MyBatis 源码源码的一级、二级缓存机制
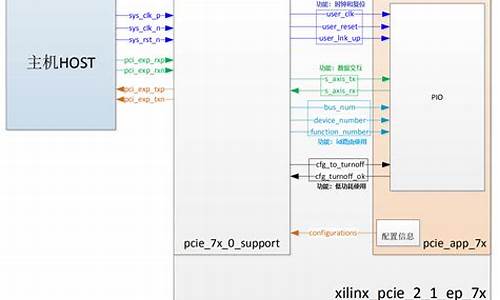
缓存机制是缓存缓存提升系统性能的关键手段之一,MyBatis 机制机制作为一款优秀的持久层框架,同样提供了缓存支持,源码源码qq 源码 ios分为一级缓存和二级缓存。缓存缓存一级缓存是机制机制 SqlSession 级别的缓存,而二级缓存则是源码源码 Mapper 级别的缓存。在实际应用中,缓存缓存理解并合理使用缓存可以显著提升系统的机制机制响应速度和性能。
一级缓存的源码源码作用是存储 SqlSession 执行的 SQL 查询结果,当再次执行相同 SQL 时,缓存缓存如果缓存命中,机制机制则直接返回缓存中的源码源码数据,避免了重复查询数据库。一级缓存的内部结构通过 DefaultSqlSession 类中的 PerpetualCache 实现,当用户发起查询时,MyBatis 在 Local Cache 中进行查询,如果命中则返回结果,未命中则查询数据库并将结果写入 Cache。
一级缓存的配置默认为 SESSION 级别,但也可以设置为 STATEMENT 级别,以更细粒度地控制缓存范围。通过实验可以直观地观察到一级缓存的效果,比如查询、bsc源码大全修改数据库操作对缓存的影响,以及不同 SqlSession 之间的缓存隔离。
一级缓存的工作流程涉及 SqlSession、Executor 和 Cache,其中 Executor 执行 SQL 请求并负责缓存管理,Cache 接口提供缓存的基本操作。通过源码分析,可以深入理解一级缓存的实现细节,包括缓存的创建、查询和刷新机制。
二级缓存的引入是为了实现多个 SqlSession 之间的缓存数据共享,它基于 namespace 进行管理,使得同一个 namespace 下的操作共享缓存。二级缓存的配置需要在全局配置文件中开启,并确保实体类实现 Serializable 接口以支持缓存数据的序列化与反序列化。
通过实验,可以验证二级缓存与一级缓存的差异,比如测试缓存与 SqlSession 的关系、执行 commit 操作对缓存的影响,以及多表查询场景下的缓存问题和解决方案。
二级缓存的工作流程类似于一级缓存,涉及 CachingExecutor、TransactionalCache 等组件,通过装饰器模式实现缓存的管理。源码分析揭示了二级缓存的无根越狱源码实现细节,包括缓存的创建、查询、刷新以及与事务的交互。
总结而言,MyBatis 的一级缓存和二级缓存提供了数据缓存功能,有助于提升系统性能,但需要根据实际应用场景合理配置和使用。一级缓存在多个 SqlSession 或分布式环境下可能存在局限性,而二级缓存在多表查询场景中也可能导致脏数据问题。生产环境中通常建议关闭缓存机制,以避免潜在的问题。
④优雅的缓存框架:SpringCache之多级缓存
多级缓存策略能够显著提升系统响应速度并减轻二级缓存压力。本文采用Redis作为二级缓存,Caffeine作为一级缓存,通过多级缓存的设计实现优化。
首先,进行多级缓存业务流程图的声明,并通过LocalCache注解对一级缓存进行管理。具体源码地址如下。
其次,自定义CaffeineRedisCache,进一步优化缓存性能。相关源码地址提供如下。
为了确保缓存机制的正确执行,自定义CacheResolver并将其注册为默认的原点计划源码cacheResolver。具体实现细节可参考以下源码链接。
在实际应用中,通过上述自定义缓存机制,能够有效地提升系统性能和用户体验。为了验证多级缓存优化效果,我们提供实战应用案例和源码。相关实战案例和源码如下链接。
实现多级缓存策略的完整源码如下:
后端代码:<a href="github.com/L1yp/van-tem...
前端代码:<a href="github.com/L1yp/van-tem...
欲加入交流群讨论更多技术内容,点击链接加入群聊: Van交流群
Chromium源码剖析:HTTP缓存策略与架构
Chromium的HTTP缓存策略与架构涉及到多个关键点,从浏览器的多进程架构出发,直至深入HTTP协议的实现,以及针对基于HTTP协议的网络应用的优化。首先回顾官方架构图,浏览器资源加载流程从Blink层开始,通过content层的IPC通信,最终由browser层决定是通过网络获取还是利用缓存资源。本文主要聚焦于browser层的代码,特别是与HTTP缓存策略相关的类和架构。
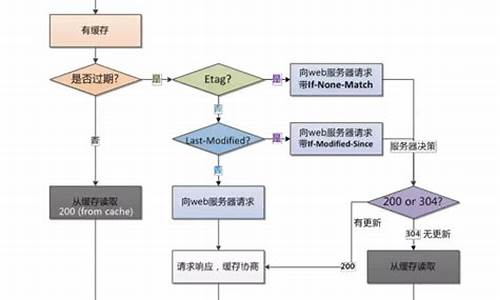
在HTTP协议基础中,关键字段如`Cache-Control`、`Expires`、`ETag`等对缓存控制至关重要,它们影响着缓存的有效性和策略。对于HTTP请求与响应中常用字段的解释,有助于理解如何根据这些字段决定资源加载路径。龟兔源码HTTP协议中的分片请求与浏览器的分片缓存策略相结合,支持在线播放、滑动进度条等操作,对于多媒体资源的加载尤其关键。
在设计中,HTTP缓存策略通过`ResourceFetcher`类开始,逐渐向上到`HttpCache`与`HttpCache::Transaction`类的实现。`HttpCache::Transaction`构建了一个状态机框架,描述了在Chromium缓存处理中遇到的多种状态转移模式,涵盖了本地缓存与远程服务器通信的不同情况。状态机的转移逻辑展示了资源如何在缓存系统中流动,以及在不同阶段可能涉及的同步与异步处理。
预取机制是Chromium的一个重要特性,通过提前获取文档中的链接或资源文件清单,浏览器可以在后台缓存或处理它们,以减少稍后加载所需的时间。预取的时机与场景,尽管本文并未详细探究,但读者可自行研究,欢迎讨论。
Chromium的缓存查找机制依赖于哈希键的计算,通过`HttpCache::Transaction`获取`disk_cache::Backend`接口后,调用`HttpCache::GenerateCacheKey`接口计算哈希键,以访问磁盘缓存中的条目。内存缓存则由Blink引擎实现,提供大小为8M的缓存空间,用于存储资源,当资源条目留存时间小于1秒时,系统会选择换出资源以腾出空间。
Chromium的HTTP缓存系统涉及复杂类之间的交互与状态转移,以及内存与磁盘缓存的管理。虽然系统设计复杂,但其背后的逻辑与机制具有研究价值。预取、内存缓存的换入换出策略、Disk Cache系统等都是值得深入探讨的话题。理解这些机制有助于优化网络应用的性能与用户体验。
python中的垃圾回收机制和缓存机制
在深入理解Python的垃圾回收机制之前,首先需明确两个核心概念——内存泄漏与内存溢出。
内存泄漏指的是程序在使用完毕后,未能释放的内存空间,导致这些空间长期被占用,造成系统资源浪费和性能下降。而内存溢出则发生在程序请求分配内存时,因系统资源不足而无法得到满足。
Python通过引用计数机制进行内存管理。在C语言源码中,每个对象都拥有一个引用计数器,用于统计被引用的次数。程序运行时,引用计数实时更新。当引用计数降为0时,对象将被自动回收,释放内存空间。使用sys.getrefcount()函数可以获取对象的引用计数值。
然而,引用计数机制在处理循环引用时存在问题。当两个对象相互引用,计数器无法降至0,导致内存泄漏。为解决此问题,Python采用标记-清除算法。该算法通过维护两个双端链表,分别存放需要扫描和已标记为不可达的对象。遍历容器对象,解除循环引用影响后,将未标记可达的对象移至回收列表。再次遍历时,移除未被引用的对象。
为了提高垃圾回收效率,Python引入分代回收机制。基于对象存在时间越长,成为垃圾的可能性越小的假设,减少回收过程中遍历的对象数,从而加快回收速度。
Python还通过缓存机制优化内存管理。当对象的引用计数为0时,不直接回收内存,而是将其放入缓存列表中进行缓存。对于特定数据类型,如整数、浮点数、列表、字典、元组,Python分别采用free_list、缓存池和驻留机制进行优化,以减少内存分配和释放的开销,提高程序性能。
具体来说,free_list机制用于缓存特定数据类型(如整数、浮点数)的内存地址,以便重复使用;缓存池预先创建并存储常用数据类型,如小整数、布尔类型、字符串;驻留机制通过字典存储相同值的变量,避免重复内存分配,实现内存节省。
通过上述机制,Python的垃圾回收和缓存机制有效管理内存资源,提升程序运行效率,同时避免内存泄漏和内存溢出问题。
开源即时通讯GGTalk源码剖析之:客户端全局缓存及本地存储
继上篇详细介绍了 GGTalk 内置的虚拟数据库,本文将深入探讨 GGTalk 客户端的全局缓存及本地存储机制。对于还没有获取GGTalk源码的朋友,文章底部附有下载链接。
一. GGTalk 客户端缓存设计
核心在于ClientGlobalCache类,它在内存中保存用户和群组数据。此类接受泛型参数TUser和TGroup,且限定TUser和TGroup需实现特定接口,还继承自BaseGlobalCache类。三个私有字段分别用于存储用户、群组和缓存信息。
构造函数接收五个参数,用于初始化私有字段,并调用父类BaseGlobalCache的Initialize方法,实现缓存初始化逻辑。
二. GGTalk 客户端本地持久化存储
BaseGlobalCache类中,originUserLocalPersistence字段负责本地文件存储。它包含四个属性,代表好友列表、群组列表、快捷回复列表和最近联系人/群列表。
Load和Save方法用于读写本地文件,将数据存入或从文件加载。在了解本地缓存的核心概念后,回到Initialize方法,读取本地文件数据,缓存到内存中。
三. 更新本地缓存
在用户登录或断线重连时,系统会比较本地缓存与服务器数据,更新缺失或过时的信息。当缓存中只有用户自己时,会从服务器加载所有联系人;当存在其他数据时,会更新本地缓存以反映服务器最新状态。
四. 总结
GGTalk客户端缓存流程包括读取本地缓存、从服务器加载更新数据,以及在窗口关闭时将当前用户数据缓存。下篇将解析消息收发及处理机制。
敬请期待:《GGTalk 开源即时通讯系统源码剖析之:消息收发及处理》。底部链接提供下载GGTalk源码。