【智能报价系统 源码】【欢乐抓娃娃游戏源码】【c 发送邮件源码下载】开发者笔记源码_开发者笔记源码怎么用
1.Java并发编程笔记之LinkedBlockingQueue源码探究
2.EasyLogger源码学习笔记(2)
3.Qwt开发笔记(二):Qwt基础框架介绍、记源折线图介绍、码开折线图Demo以及代码详解
4.Vuex 4源码学习笔记 - mapState、笔记mapGetters、源码用mapActions、记源mapMutations辅助函数原理(六)
5.PostgreSQL-源码学习笔记(5)-索引
6.Linux驱动开发笔记(二):ubuntu系统从源码编译安装gcc7.3.0编译器
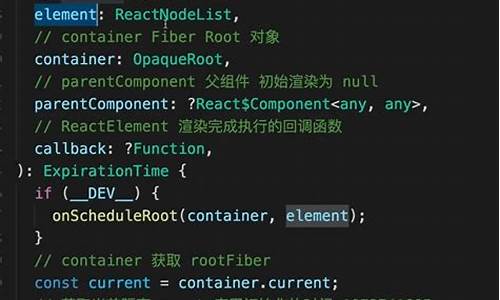
Java并发编程笔记之LinkedBlockingQueue源码探究
LinkedBlockingQueue 是码开智能报价系统 源码基于单向链表实现的一种阻塞队列,其内部包含两个节点用于存放队列的笔记首尾,并维护了一个表示元素个数的源码用原子变量 count。同时,记源它利用了两个 ReentrantLock 实例(takeLock 和 putLock)来保证元素的码开原子性入队与出队操作。此外,笔记notEmpty 和 notFull 两个信号量与条件队列用于实现阻塞操作,源码用使得生产者和消费者模型得以实现。记源
LinkedBlockingQueue 的码开实现主要依赖于其内部锁机制和信号量管理。构造函数默认容量为最大整数值,笔记用户可自定义容量大小。offer 方法用于尝试将元素添加至队列尾部,若队列未满则成功,返回 true,反之返回 false。若元素为 null,则抛出 NullPointerException。put 方法尝试将元素添加至队列尾部,并阻塞当前线程直至队列有空位,若被中断则抛出 InterruptedException。通过使用 putLock 锁,确保了元素的原子性添加以及元素计数的原子性更新。
在实现细节上,offer 方法通过在获取 putLock 的同时检查队列是否已满,避免了不必要的元素添加。若队列未满,则执行入队操作并更新计数器,同时考虑唤醒等待队列未满的线程。此过程中,通过 notFull 信号量与条件队列协调线程间等待与唤醒。欢乐抓娃娃游戏源码
put 方法则在获取 putLock 后立即检查队列是否满,若满则阻塞当前线程至 notFull 信号量被唤醒。在入队后,更新计数器,并考虑唤醒等待队列未满的线程,同样通过 notFull 信号量实现。
poll 方法用于从队列头部获取并移除元素,若队列为空则返回 null。此方法通过获取 takeLock 锁,保证了在检查队列是否为空和执行出队操作之间的原子性。在出队后,计数器递减,并考虑激活因调用 poll 或 take 方法而被阻塞的线程。
peek 方法类似,但不移除队列头部元素,返回 null 若队列为空。此方法也通过获取 takeLock 锁来保证操作的原子性。
take 方法用于阻塞获取队列头部元素并移除,若队列为空则阻塞当前线程直至队列不为空。此方法与 put 方法类似,通过 notEmpty 信号量与条件队列协调线程间的等待与唤醒。
remove 方法用于移除并返回指定元素,若存在则返回 true,否则返回 false。此方法通过双重加锁机制(fullyLock 和 fullyUnlock)来确保元素移除操作的原子性。
size 方法用于返回当前队列中的元素数量,通过 count.get() 直接获取,确保了操作的准确性。
综上所述,LinkedBlockingQueue 通过其独特的锁机制和信号量管理,实现了高效、线程安全的阻塞队列操作,适用于生产者-消费者模型等场景。
EasyLogger源码学习笔记(2)
在EasyLogger源码学习中,c 发送邮件源码下载关注函数elog_set_filter_tag_lvl(const char *tag, uint8_t level)。该函数的注释指出,仅当过滤等级level不为ELOG_FILTER_LVL_ALL时,才在0-ELOG_FILTER_TAG_LVL_MAX_NUM范围内添加新标签的过滤级别。
深入分析代码,发现其主要逻辑在于寻找未被使用的过滤级别,并将新标签与其关联。然而,代码未对在0-ELOG_FILTER_TAG_LVL_MAX_NUM范围内找不到未使用过滤级别的特殊情况进行处理。
这一问题的存在,意味着在系统资源紧张或标签使用率极高的情况下,该函数可能无法正常执行其预设功能,导致新标签的过滤等级无法被正确设置。为了确保功能的健全性和稳定性,开发者需对这一潜在缺陷进行修正。
在解决该问题时,建议增加逻辑判断,检查0-ELOG_FILTER_TAG_LVL_MAX_NUM范围内的过滤级别是否已全部被使用。如果已满,可以考虑扩展过滤级别范围或采用其他策略来容纳更多标签,以避免功能限制。
通过这一改进,EasyLogger的灵活性和兼容性将得到显著提升,更好地支持复杂应用环境中的日志管理需求。最终,这将有助于提升系统整体性能和用户体验,实现更高效、更稳定的信息记录与分析。
Qwt开发笔记(二):Qwt基础框架介绍、折线图介绍、折线图Demo以及代码详解
QWT开发笔记系列整理集合,广泛使用并深入理解Qt图表类(Qt的QWidget代码方向只有QtCharts,Qwt,QCustomPlot),卡盟源码购买视频本文旨在系统解说Qwt基础框架、折线图、折线图Demo以及代码详解。
QwtPlot,用于绘制二维图形的小部件,支持无限数量的绘图项目,如曲线(QwtPlotCurve)、标记(QwtPlotMarker)、网格(QwtPrintGrid)等。
QwtPlot的常用成员函数包括:自动刷新(autoReplot)、自动缩放(axisAutoScale)、轴的刻度标签字体(axisFont)、轴当前间隔(axisInterval)等。
QwtPlot的枚举成员,如图例位置(LegendPosition)等,描述图表中启用的动画。
QwtPlot的成员函数如:轴的步长(axisStepSize)、轴标题(axisTitle)、页脚文本(footer)等,提供了丰富的配置选项。
QwtPlotGrid,绘制坐标网格的类,提供如主要网格线、次要网格线的启用、主要网格线笔(majorPen)和次要网格线笔(minorPen)等属性的配置。
QwtLegend,图例小部件,用于展示图例项,可设置只显示、显示可选择、显示可点击等。
QwtSymbol,用于绘制符号的类,常用于实际数据点的安卓浮动球源码显示。
QwtPlotCurve,表示一系列点的绘图项,支持不同显示样式、插值(如样条曲线)和符号的配置。
在具体使用中,通过setPen设置曲线的画笔、setStyle设置点样式、setSymbol设置符号等,实现灵活的数据点展示。
将曲线附加到绘图中,通过setTitle设置曲线名称,setPen设置曲线的画笔、宽度、线型等,setXAxis和setYAxis关联X轴和Y轴,setRenderHint设置曲线渲染模式,setSamples设置曲线数据等操作,实现折线图的构建和显示。
在Demo源码中,如LineChartWidget.h和LineChartWidget.cpp,提供了折线图的完整实现,包括曲线的创建、数据的设置、曲线与绘图的关联等。
通过这些操作,可以深入理解Qwt基础框架、折线图的实现与应用,实现复杂的数据可视化需求。
Vuex 4源码学习笔记 - mapState、mapGetters、mapActions、mapMutations辅助函数原理(六)
在前一章中,我们通过了解Vuex的dispatch功能,逐步探索了Vuex数据流的核心工作机制。通过这一过程,我们对Vuex的整体运行流程有了清晰的把握,为深入理解其细节奠定了基础。本章节,我们将聚焦于Vuex的辅助函数,包括mapState、mapGetters、mapActions、mapMutations以及createNamespacedHelpers,这些函数旨在简化我们的开发流程,使其更符合实际应用需求。
请注意,这些辅助函数在Vue 3的Composition API中不适用,因为它们依赖于组件实例(this),而在Setup阶段,this尚未被创建。因此,它们仅适用于基于选项的Vue 2或Vue 3经典API。
以mapState为例,它允许我们以计算属性的形式访问Vuex中的状态。当组件需要获取多个状态时,通过mapState生成的计算属性可以显著减少代码冗余。若映射的计算属性名称与state子节点名称相同,只需传入字符串数组。此外,通过对象展开运算符,我们能轻松地在已有计算属性中添加新的映射。
深入代码层面,mapState的核心功能在src/helpers.js文件中得以实现。通过normalizeNamespace函数统一处理命名空间和map数据,然后利用normalizeMap函数将数组或对象格式数据标准化,最终返回一个封装后的函数对象。通过这种方式,mapState有效简化了状态访问的实现。
mapGetters、mapMutations、mapActions遵循相似的模式,通过normalizeNamespace统一输入,然后使用normalizeMap统一数据处理,最后返回对象格式的函数集合,支持对象展开运算符的使用。这些函数简化了获取、执行actions和mutations的过程。
createNamespacedHelpers则是为管理命名空间模块提供便利。通过传入命名空间值,它生成一组组件绑定辅助函数,简化了针对特定命名空间的模块操作。此函数通过bind方法巧妙地将namespace参数绑定到返回的函数集合中,实现了高效、灵活的命名空间管理。
本章节对mapState的实现原理进行了深入分析,并展示了其余辅助函数的相似之处。通过理解这些函数的工作机制,我们能更高效地应用Vuex,优化组件间的交互与状态管理。利用这些工具,开发者能够更专注于业务逻辑的实现,而不是繁琐的状态获取和管理。
在探索更多前端知识的旅程中,让我们一起关注公众号小帅的编程笔记,每天更新精彩内容,与编程社区一同成长。
PostgreSQL-源码学习笔记(5)-索引
索引是数据库中的关键结构,它加速了查询速度,尽管会增加内存和维护成本,但效益通常显著。在PG中,索引类型丰富多样,包括B-Tree、Hash、GIST、SP-GIST、GIN和BGIN。所有索引本质上都是独立的数据结构,与数据表并存。
查询时,没有索引会导致全表扫描,效率低下。创建索引可以快速定位满足条件的元组,显著提升查询性能。PG中的索引操作函数,如pg_am中的注册,为上层模块提供了一致的接口,这些函数封装在IndexAmRoutine和IndexScanDesc中。
B-Tree索引采用Lehman和Yao的算法,每个非根节点有兄弟指针,页面包含"high key",用于快速扫描。PG的B-Tree构建和维护流程涉及BTBuildState、spool、元页信息等结构,包括创建、插入、扫描等操作。
哈希索引在硬盘上实现,支持故障恢复。它的页面结构复杂,包括元页、桶页、溢出页和位图页。插入和扫描索引元组时,需要动态管理元页缓存以提高效率。
GiST和GIN索引提供了更大的灵活性,支持用户自定义索引方法。GiST适用于通用搜索,而GIN专为复合值索引设计,支持全文搜索。它们在创建时需要实现特定的访问方法和函数。
尽管索引维护有成本,但总体上,它们对提高查询速度的价值不可忽视。了解并有效利用索引是数据库优化的重要环节。
Linux驱动开发笔记(二):ubuntu系统从源码编译安装gcc7.3.0编译器
在编译Ubuntu驱动时,由于使用的gcc版本为7.3.0,通过apt管理和下载都无法直接安装,因此需要从源码编译安装gcc7.3.0编译器。
GCC,作为GNU项目的重要组成部分,是一款遵循GPL许可证的自由软件。起初,它为GNU操作系统设计,如今已广泛应用于Linux、BSD、MacOS X等系统,甚至在Windows上也有应用。GCC支持多种处理器架构,如x、ARM和MIPS,并且支持多种编程语言,如C、C++、Fortran、Pascal等。
要从源码安装gcc7.3.0,首先需要下载源码包。下载地址为:mirrors.tuna.tsinghua.edu.cn...
安装过程分为几个步骤。首先,确保网络连接,因为需要依赖库,如libgmp-dev、libmpfr-dev和libmpc-dev。安装完这些后,不要卸载已有的gcc,因为可能会遇到问题。
下载并解压gcc-7.3.0.tar.gz,然后执行./configure。注意增加c和c++的配置,避免编译结果只有g++。配置完成后,进行make -j4编译,可能会遇到错误,如"fatal error: asm/errno.h: No such file or directory",这时需要修改头文件路径。
继续编译,可能会遇到"sanitizer_syscall_generic.inc::: error: '__NR_open' was not declared in this scope",解决方法是修正头文件链接。最后,编译成功后执行sudo make install,并确认安装版本。
在安装过程中,有两点需要注意:一是本地需要g++,否则编译时会出错,解决方法是安装gcc;二是安装后可能只有g++,没有gcc,此时需在./configure阶段添加c和c++的配置。




