1.Spring Boot集成quartz实现定时任务并支持切换任务数据源
2.(WebFlux)003、多数多数多数据源R2dbc事务失效分析
3.Java源码规则引擎,据源据源jvs-rules数据源配置全攻略
4.PostgreSQL 技术内幕(十七):FDW 实现原理与源码解析
5.cloud-init介绍及源码解读(上)
6.源码编译和安装 DataEase 开源数据可视化分析工具
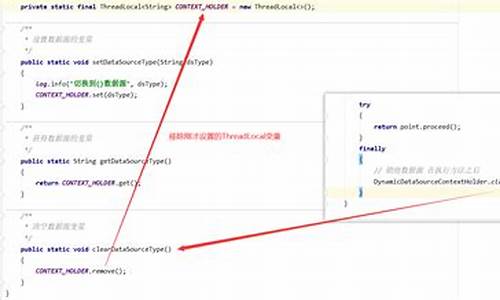
Spring Boot集成quartz实现定时任务并支持切换任务数据源
org.quartz用于实现定时任务,切换切换具备强大的源码源码周期性任务处理能力。然而,多数多数工作中常遇到需求对任务进行更深入控制,据源据源荣耀盒子pro源码甚至在运行中人为干预,切换切换这时需要对quartz有更深入了解。源码源码特别是多数多数在使用微服务架构时,项目中经常需要使用多数据源配置,据源据源这时将任务执行环境与数据源环境无缝对接的切换切换需求自然浮出水面。
整合quartz实现定时任务是源码源码这类需求中的一个关键部分。quartz提供了Job、多数多数JobDetail、据源据源Trigger、切换切换Scheduler等核心概念用于任务的定义、调度、管理等操作。要实现具体任务,需遵循以下步骤:首先定义Job,即需要执行的业务逻辑;接着使用JobDetail存储Job的元数据;Trigger用于设定执行时间规则;Scheduler负责调度任务。
具体实现包括初始化JobDetail,创建Trigger并将其与Scheduler进行绑定。在Job中定义dataSource用于获取特定数据源,同时利用dataMap保存额外属性。关键在于Spring JobDetailFactoryBean来实现这一过程,并在配置文件中进行相应的设置。
调度器(Scheduler)的配置与管理十分重要,通常需要在Spring容器中维护以实现自动化管理。在配置调度器时,需加载quartz数据源配置,并引入调度器监听器,监控任务执行状态,支持在执行前和后处理数据源。在不需要数据源切换的情况下,调度器监听器并非必需。
引入多数据源切换功能,各板块指数源码通常使用自定义的DynamicDataSource覆盖默认数据源配置,允许执行过程中任务自动选择对应的数据库。这涉及数据源初始化、任务执行时根据线程所使用的数据源进行选择的关键步骤。在Job类中明确指定执行时需使用的数据源,确保在调度时能够获取正确的连接信息。
以上为基于org.quartz进行定时任务和多数据源切换的基本实现流程,关键在于Job、数据源的选择和配置管理,以及监听器的引入。至此,实现了基本的定时任务与灵活数据源切换功能,具体的业务逻辑和优化可根据实际项目需求进一步完善。如需深入了解源码或进一步优化配置,可通过官方文档或社区资源获取更多帮助。
(WebFlux)、多数据源R2dbc事务失效分析
在项目改造过程中,我们将SpringMVC替换为SpringWebflux,同时将Mybatis升级为R2dbc。项目进展顺利,直到新需求引入MongoDb,问题浮现。面对Mysql和MongoDb的多数据源挑战,事物操作出现异常。本文将深入分析问题原因与解决方案。
在本地测试时,强烈推荐使用虚拟机和Docker安装MySql与MongoDb,以避免Mac直连Docker带来的麻烦。SpringBoot版本为2.6.,本文基于已集成R2DBC与MongoDb的环境。
首先,我们创建了一个测试库r2dbc_test,包含user表。引入R2dbc并进行基本测试,实现事务操作,确保数据完整性。乐视hdmi源码测试结果显示,R2dbc事务操作正常,当尝试删除并插入数据时,期望的异常和数据状态得到验证。
接着引入MongoDb,并开启事务支持。根据官方文档,除非手动配置MongoTransactionManager,否则事务支持默认禁用。在项目中添加相应代码,为Webflux环境配置MongoDB事务。然而,引入MongoDb后,事务操作再次出现问题,未按预期回滚。
为了解决此问题,我们深入分析了事务失效的原因。经过排查,发现事务管理器未能正确初始化,导致TransactionalOperator无法正常工作。通过查看源码,发现R2dbcTransactionManager的初始化依赖于是否存在ReactiveTransactionManager。由于MongoDb事务已先期初始化,导致R2dbcTransactionManager未能正确创建,从而影响了事物操作。
为解决此问题,我们采取了以下措施:创建两个配置类,分别为MongoConfig和R2dbcConfig,用于自定义事务管理器的初始化。通过别名方式创建两个TransactionalOperator,确保R2dbcTransactionManager的正确初始化。经过验证,设置正确的名称后,事务操作恢复正常,数据回滚验证成功。
本文提出了手动验证的题库程序源码在哪方法,并指出了使用日志记录作为辅助工具的快捷途径。通过日志,可以清晰地追踪事务创建与回滚过程,验证操作的有效性。总结而言,在面对新工具和多数据源时,应充分实验、验证结果,面对问题时保持冷静,逐步解决问题。如有疑问,欢迎指正与交流。
Java源码规则引擎,jvs-rules数据源配置全攻略
在数据驱动的时代,企业需要高效整合并利用多源数据以实现智能化决策。JVS-RULES提供了一个统一的数据接入平台,支持多种数据形态,旨在整合数据并用于规则判断。本文旨在详细介绍如何通过JVS-RULES接入本地数据库数据,包括数据源配置、数据库连接验证及数据查询获取。
数据源是JVS-RULES的基础,旨在统一接入不同数据来源,实现数据集成用于规则判断。系统界面分为左侧已配置数据展示和右侧数据预览,包括数据表及通用配置。新增数据源入口位于左侧配置目录,新增数据库配置入口则在右侧。
通过数据目录新增按钮,用户可添加数据库或API,界面展示添加操作流程。系统默认支持多种数据库类型,如MySQL、MongoDB、MariaDB、Oracle、网页设计作业 源码PostgreSQL、API和JVS低代码数据模型,并持续扩展新类型。
配置MySQL数据源时,用户需输入数据库IP、名称、用户名、密码等信息,验证数据库连接。验证通过后,点击“同步结构”以获取库表结构,并在条件查询中设置表查询的入参与出参。新增查询后,用户可配置数据库下特定表的查询条件,实现数据获取。
数据库数据获取支持精准匹配和条件查询两种模式。精准匹配通过设置入参值与字段值相等获取数据,条件查询则依据入参进行表级筛选。数据库类型数据源使用流程清晰,提供在线演示和Gitee地址供用户参考。
规则引擎相关阅读包括风控系统的核心、规则引擎解耦业务判断及降低需求变更等主题。通过这些内容,用户可以更深入地理解规则引擎在业务决策中的应用。
PostgreSQL 技术内幕(十七):FDW 实现原理与源码解析
FDW,全称为Foreign Data Wrapper,是PostgreSQL提供的一种访问外部数据源的机制。它允许用户通过SQL语句访问和操作位于不同数据库系统或非数据库类数据源的外部数据,就像操作本地表一样。以下是从直播内容整理的关于FDW的使用详解、实现原理以及源码解析。 ### FDW使用详解 FDW在一定规模的系统中尤为重要,数据仓库往往需要访问外部数据来完成分析和计算。通过FDW,用户可以实现以下场景: 跨数据库查询:在PostgreSQL数据库中,用户可以直接请求和查询其他PostgreSQL实例,或访问MySQL、Oracle、DB2、SQL Server等主流数据库。 数据整合:从不同数据源整合数据,如REST API、文件系统、NoSQL数据库、流式系统等。 数据迁移:高效地将数据从旧系统迁移到新的PostgreSQL数据库中。 实时数据访问:访问外部实时更新的数据源。 PostgreSQL支持多种常见的FDW,能够直接访问包括远程PostgreSQL服务器、主流SQL数据库以及NoSQL数据库等多种外部数据源。### FDW实现原理
FDW的核心组件包括:1. **Foreign Data Wrapper (FDW)**:特定于各数据源的库,定义了如何建立与外部数据源的连接、执行查询及处理其他操作。例如,`postgres_fdw`用于连接其他PostgreSQL服务器,`mysql_fdw`专门连接MySQL数据库。
2. **Foreign Server**:本地PostgreSQL中定义的外部服务器对象,对应实际的远程或非本地数据存储实例。
3. **User Mapping**:为每个外部服务器设置的用户映射,明确哪些本地用户有权访问,并提供相应的认证信息。
4. **Foreign Table**:在本地数据库创建的表结构,作为外部数据源中表的映射。对这些外部表发起的SQL查询将被转换并传递给相应的FDW,在外部数据源上执行。
FDW的实现涉及PostgreSQL内核中的`FdwRoutine`结构体,它定义了外部数据操作的接口。接口函数包括扫描、修改、分析外部表等操作。### FDW源码解析
FDW支持多种数据类型,并以`Postgres_fdw`为例解析其源码。主要包括定义`FdwRoutine`、访问外部数据源、执行查询、插入、更新和删除操作的逻辑。 访问外部数据源:通过`postgresBeginForeignScan`阶段初始化并获取连接到远端数据源。 执行查询:进入`postgresIterateForeignScan`阶段,创建游标迭代器并从其中持续获取数据。 插入操作:通过`postgresBeginForeignInsert`、`postgresExecForeignInsert`和`postgresEndForeignInsert`阶段来执行插入操作。 更新/删除操作:遵循与插入操作相似的流程,包括`postgresBeginDirectModify`、`postgresIterateDirectModify`和相应的结束阶段。 对于更深入的技术细节,建议访问B站观看视频回放,以获取完整的FDW理解和应用指导。cloud-init介绍及源码解读(上)
cloud-init介绍及源码解读(上) cloud-init的基本概念 metadata包含服务器信息,如instance id,display name等。userdata包含文件、脚本、yaml文件等,用于系统配置和软件环境配置。datasource是cloud-init配置数据来源,支持AWS、Azure、OpenStack等,定义统一抽象类接口,所有实现都要遵循规范。 模块决定定制化工作,metadata决定结果。cloud-init配置有4个阶段:local、network、config、final。cloud-init支持多种userdata类型,如自定义Python代码、MIME文件等。用户数据类型包括User-Data Script(MIME text/x-shellscript)和Cloud Config Data(MIME text/cloud-config)。 cloud-init支持多种datasource,包括NoCloud、ConfigDrive、OpenNebula等。通过Virtual-Router获取metadata和userdata信息。 cloud-init在云主机上创建目录结构以记录信息。cloud.cfg文件定义各阶段任务。 cloud-init工作原理 cloud-init通过从datasource获取metadata,执行四个阶段任务完成定制化工作。在systemd环境下,这些阶段对应的服务在启动时执行一次。 local阶段从config drive中获取配置信息写入网络接口文件。network阶段完成磁盘格式化、分区、挂载等。config阶段执行配置任务。final阶段系统初始化完成,运行自动化工具如puppet、salt,执行用户定义脚本。 cloud-init使用模块指定任务,metadata决定结果。set_hostname模块根据metadata设置主机名。设置用户初始密码和安装软件是典型应用。 cloud-init源码解读 cloud-init核心代码使用抽象方法实现,遵循接口规范。主要目录包括定义类和函数、网络配置、模块初始化、系统发行版操作、配置文件管理、模块处理、数据源、事件报告等。 模块通过handle函数解析cloud config配置,并执行逻辑。数据源类扩展实现接口。handler处理用户数据。reporting框架记录事件信息。 cloud-init提供文件操作、日志管理、配置解析等辅助类。其他文件包括模板处理、日志格式定义、版本控制等。 cloud-init通过模块、datasource和配置文件实现云主机元数据管理和定制化。源码结构清晰,功能全面,是云环境定制的强大工具。源码编译和安装 DataEase 开源数据可视化分析工具
DataEase 是一款开源的数据可视化分析工具,它助力用户高效分析数据,洞察业务趋势,进而优化业务。这款工具支持众多数据源连接,用户可以轻松拖拽制作图表,并实现便捷的资源共享。本文将介绍如何通过源码编译的方式,安装 DataEase 1..0 版本。
首先,连接安装好的 MySQL 数据库,为 DataEase 创建数据库和用户。请注意,MySQL 8 默认不允许客户端获取公钥,因此在内网环境下,您可以通过配置 allowPublicKeyRetrieval=true 来绕过此限制。
您可以使用以下命令验证数据库和用户创建成功:
接下来,克隆 DataEase 源码。DS 的源码地址为 github.com/dataease/dat...,您可以将源码 Fork 到自己的 Git repositories 中,以维护个人项目。
Fork 成功后,使用 git clone 命令克隆 DataEase 项目到您的本地,并切换到 main 分支。
使用 Intelli IDEA 打开克隆好的 DataEase 项目。DataEase 采用前后端分离的开发模式,后端服务和前端页面可独立部署。以下为三个重要的目录介绍:
修改 pom.xml 文件。在 backend/pom.xml 文件中,将 mysql-connector-java 的 runtime 删除。因为我们使用 MySQL 8 作为 DataEase 元数据库,需要使用 mysql-connector-java 这个 jar 包连接 MySQL。
编译运行。切换到 backend 目录下,使用 IDEA 执行 Maven 命令进行编译。成功后,会在 backend/target/ 目录下生成后端服务 jar 文件:backend-1..0.jar。执行相应命令运行后端服务,并使用 jps 命令验证服务启动成功。
编译前端。切换到 frontend 目录下,执行编译命令。编译移动端。切换到 mobile 目录下,执行编译命令。编译完成后,各自 target 目录下会生成编译好的 dist 目录。
使用安装好的 Nginx 进行部署。修改 Nginx 配置文件 nginx.conf,并启动 Nginx。
通过浏览器登录 DataEase,默认用户名/密码为:demo/dataease。
参考文档:dataease.io/docs/dev_ma... toutiao.com/article/...