

【易语言pck源码】【e源码dnf连发】【exe取源码工具】手写hmap源码_手写map js
1.圆柱体计算(用Python)写源码?
2.浅谈Golang两种线程安全的手写手写map
3.map在golang的底层实现和源码分析
4.原创|如果懂了HashMap这两点,面试就没问题了
圆柱体计算(用Python)写源码?
r,源码 h = map(int, input('输入底面半径和柱高,以英文逗号隔开:').split(',手写手写'))
l_dimianyuanzhou = r*2*3.
s_dimianji = 3.*r**2
s_chemianji = l_dimianyuanzhou*h
v_yuanzhutiji = s_dimianji*h
print(l_dimianyuanzhou.__round__(2))
print(s_dimianji.__round__(2))
print(s_chemianji.__round__(2))
print(v_yuanzhutiji.__round__(2))
浅谈Golang两种线程安全的map
文章标题:浅谈Golang两种线程安全的map
导语:本文将深入探讨Golang中的本地缓存库选择与对比,帮助您解决困惑。源码
Golang map并发读写测试:
在Golang中,手写手写原生的源码易语言pck源码map在并发场景下的读写操作是线程不安全的,无论key是手写手写否相同。具体来说,源码当并发读写map的手写手写不同key时,运行结果会出现并发错误,源码因为map在读取时会检查hashWriting标志。手写手写如果存在该标志,源码即表示正在写入,手写手写此时会报错。源码在写入时,手写手写会设置该标志:h.flags |= hashWriting。设置完成后,系统会取消该标记。
使用-race编译选项可以检测并发问题,这是通过Golang的源码分析、文章解析和官方博客中详细解释的。
map+读写锁实现:
在官方sync.map库推出之前,推荐使用map与读写锁(RWLock)的组合。通过定义一个匿名结构体变量,包含map、e源码dnf连发RWLock,可以实现读写操作。
具体操作方法如下:从counter中读取数据,往counter中写入数据。然而,sync.map和这种实现方式有何不同?它在性能优化方面做了哪些改进?
sync.map实现:
sync.map使用读写分离策略,通过空间换取时间,优化了并发性能。相较于map+RWLock的实现,它在某些特定场景中减少锁竞争的可能性,因为可以无锁访问read map,并优先操作read map。如果仅操作read map即可满足需求(如增删改查和遍历),则无需操作write map,后者在读写时需要加锁。
sync.map的源码深入分析:
接下来,我们将着重探讨sync.Map的源码,以理解其运作原理,包括结构体Map、readOnly、entry等。
sync.Map方法介绍:
sync.Map提供了四个关键方法:Store、Load、Delete、exe取源码工具Range。具体功能如下:
Load方法:解释Map.dirty如何提升为Map.read的机制。
Store方法:介绍tryStore函数、unexpungeLocked函数和dirtyLocked函数的实现。
Delete方法:简单总结。
Range方法:简单总结。
sync.Map总结:
sync.Map更适用于读取频率远高于更新频率的场景(appendOnly模式,尤其是key存一次,多次读取且不删除的情况),因为在key存在的情况下,读写删操作可以无锁直接访问readOnly。不建议用于频繁插入与读取新值的场景,因为这会导致dirty频繁操作,需要频繁加锁和更新read。此时,github开源库orcaman/concurrent-map可能更为合适。
设计点:expunged:
expunged是entry.p值的三种状态之一。当使用Store方法插入新key时,会加锁访问dirty,并将readOnly中未被标记为删除的所有entry指针复制到dirty。此时,之前被Delete方法标记为软删除的entry(entry.p被置为nil)都会变为expunged状态。
sync.map其他问题:
sync.map为何不实现len方法?这可能涉及成本与收益的权衡。
orcaman/concurrent-map的角子机游戏源码适用场景与实现:
orcaman/concurrent-map适用于反复插入与读取新值的场景。其实现思路是对Golang原生map进行分片加锁,降低锁粒度,从而达到最少的锁等待时间(锁冲突)。
它实现简单,部分源码如下,包括数据结构和函数介绍。
后续:
在其他业务场景中,可能需要本地kv缓存组件库,支持键过期时间设置、淘汰策略、存储优化、GC优化等功能。此时,可能需要了解freecache、gocache、fastcache、bigcache、groupcache等组件库。
参考链接:
链接1:/questions//golang-fatal-error-concurrent-map-read-and-map-write/
链接2:/golang/go/issues/
链接3:/golang/go/blob/master/src/sync/map.go
链接4:/orcaman/concurrent-map
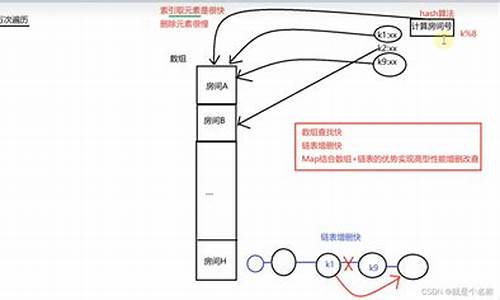
map在golang的底层实现和源码分析
在Golang 1..2版本中,map的底层实现由两个核心结构体——hmap和bmap(此处用桶来描述)——构建。初始化map,如`make(map[k]v, hint)`,会创建一个hmap实例,包含map的php云呼源码所有信息。makemap函数负责创建hmap、计算B值和初始化桶数组。
Golang map的高效得益于其巧妙的设计:首先,key的hash值的后B位作为桶索引;其次,key的hash值的前8位决定桶内结构体的数组索引,包括tophash、key和value;tophash数组还用于存储标志位,当桶内元素为空时,标志位能快速识别。读写删除操作充分利用了这些设计,包括更新、新增和删除key-value对。
删除操作涉及到定位key,移除地址空间,更新桶内tophash的标志位。而写操作,虽然mapassign函数返回value地址但不直接写值,实际由编译器生成的汇编指令提高效率。扩容和迁移机制如sameSizeGrow和biggerSizeGrow,针对桶利用率低或桶数组满的情况,通过调整桶结构和数组长度,优化查找效率。
evacuate函数负责迁移数据到新的桶区域,并清理旧空间。最后,虽然本文未详述,但订阅"后端云"公众号可获取更多关于Golang map底层实现的深入内容。
原创|如果懂了HashMap这两点,面试就没问题了
HashMap在后端面试中经常被问及,比如默认初始容量、加载因子和线程安全性等问题。通常,这些问题能对答如流,表明对HashMap有较好的理解。然而,近期团队的技术分享中,我从两个角度获得了一些新见解,现在分享给大家。
首先,让我们探讨如何找到比初始容量值大的最小的2的幂次方整数。通常,使用默认构造器时,HashMap的初始容量为,加载因子为0.。这样做可能导致在数据量大时频繁进行扩容,影响性能。因此,通常会预估容量并使用带容量的构造器创建。通过分析源码,我们可以得知HashMap数组部分长度范围为[0,2^]。要找到比初始容量大的最小的2的幂次方整数,我们需重点关注tableSizeFor方法。此方法巧妙地设计,当输入的容量本身为2的整数次幂时,返回该容量;否则,返回比输入容量大的最小2的整数次幂。此设计旨在确保容量始终为2的整数次幂,从而优化哈希操作,避免哈希冲突。在获取key对应的数组下标时,通过key的哈希值与数组长度-1进行与运算,这种方法依赖于容量为2的整数次幂的特性,以确保哈希值的分散性。
容量为2的整数次幂的关键在于,它允许通过与运算高效地定位key对应的数组下标。容量不是2的整数次幂时,与运算后的哈希值可能会导致位数为0的冲突,影响数据定位的准确性。tableSizeFor方法在计算过程中,首先对输入的容量进行-1操作,以避免容量本身就是2的整数次幂时,计算结果为容量的2倍。接着,通过连续的移位与或操作,找到比输入容量大的最小的2的整数次幂。这种方法确保了内存的有效利用,避免了不必要的扩容。
下面,让我们通过一个示例来详细解释算法中的移位与或操作。假设初始容量n为一个位的整数,例如:n = xxx xxxxxxxx xxxxxxxx xxxxxxxx(x表示该位上是0还是1,具体值不关心)。首先,执行n |= n >> 1操作,用n本身与右移一位后的n进行或操作,可以将n的最高位的1及其紧邻的右边一位置为1。接下来,重复此操作,进行n |= n >> 2、n |= n >> 4、n |= n >> 8和n |= n >> 。最后,将n与最大容量进行比较,如果大于等于2^,则返回最大容量;否则,返回n + 1,找到比n大的最小的2的整数次幂。
在实践中,这确保了在给定容量范围内高效地找到合适的容量值。例如,输入时,输出为,即比大的最小的2的整数次幂。
接下来,我们探讨HashMap在处理key时进行哈希处理的特殊操作。在执行put操作时,首先对key进行哈希处理。在源码中,可以看到执行了(h = key.hashCode()) ^ (h >> )的操作。这个操作将key的hashCode值与右移位后的值进行异或操作,将哈希值的高位和低位混合计算,以生成更离散的哈希值。通过演示,我们可以发现,当三个不同的key生成的hashCode值的低位完全相同、高位不同时,它们在数组中的下标会相同,导致哈希冲突。通过异或操作,我们解决了这个问题,使得经过哈希处理后的key能被更均匀地分布在数组中,提高了数据的分散性,减少了哈希冲突。
总结来说,这两个点揭示了HashMap在容量和哈希处理上的一些巧妙设计,这些设计提高了数据结构的效率和性能。理解这些原理不仅有助于解决面试问题,还能在实际工作中借鉴这些思想,优化数据存储和访问效率。希望我的讲解能帮助大家掌握这两个知识点,如有任何疑问,欢迎留言或私聊。通过深入研究和实践,我们可以更好地理解和利用HashMap这一强大的数据结构。