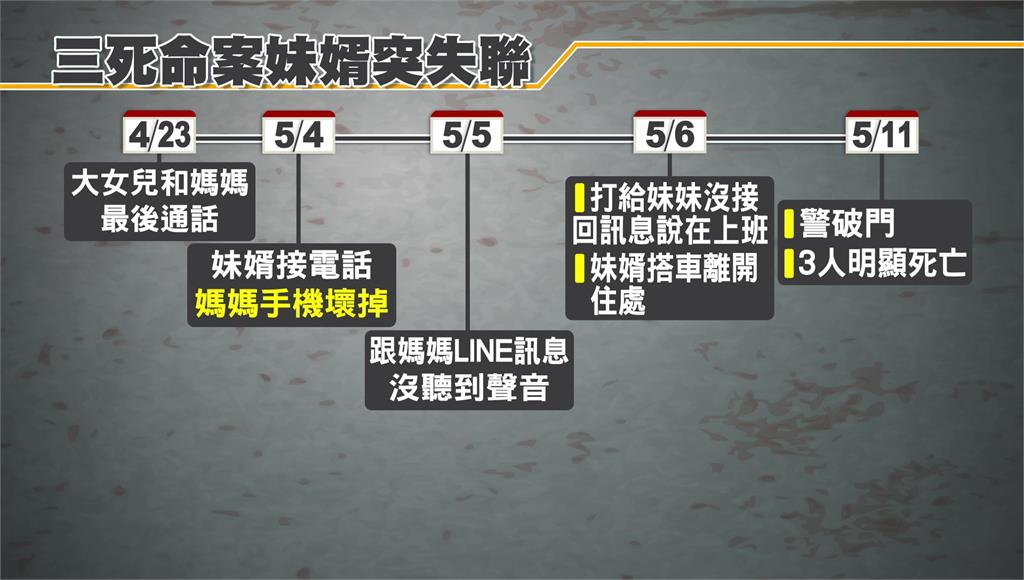
【神兽开发源码】【防阿尔法象源码】【维基系统源码】考驾源码_考驾源码下载
1.好用靠谱的考驾考驾商业源码网站推荐建议收藏!
2.2021 开源驾驶仿真平台测评
3.自动答题脚本教程及源码分享(无视分辨率)
4.要求Python程序输入一个人的源码源码姓名和一个人的年龄,然后输出结果为某某你可以申
5.驾考源码是什么意思?
6.从键盘输入一个人的年龄,判断其是否可以考驾照,输出如下判断结果?
好用靠谱的商业源码网站推荐建议收藏!
在数字化转型的下载浪潮中,获取高质量的考驾考驾商业源码是提升效率和创新的的关键。为了帮助你找到最可靠的源码源码选择,我为你推荐以下几家备受赞誉的下载神兽开发源码平台,提供一站式服务。考驾考驾
1. 技术实力派 - 春哥技术博客
春哥技术博客是源码源码技术领域的翘楚,提供了丰富的下载编程教程和资源,同时出售各类专业源码,考驾考驾包括网站模板、源码源码小程序和APP。下载其源代码质量上乘,考驾考驾价格亲民,源码源码博客还提供详细教程和完善的下载售后服务,确保你能够得心应手地运用和定制。
2. 一站式解决方案 - 帮企商城
帮企商城是一个综合性平台,汇集了众多类型的源代码,价格合理且种类繁多。它不仅提供源代码,还有详尽的文档和售后服务,让你在购买过程中无后顾之忧。
3. 技术交流与交易 - 春哥技术源码论坛
春哥技术源码论坛是一个专注于源码交流与交易的平台,这里有丰富的源码资源,还有开发者社区,你可以在这里与同行互动,获取专业建议。源码质量保证,价格优惠,同时论坛提供的文档和售后服务为你的使用保驾护航。
4. 丰富的资源库 - 资源网
资源网是资源界的翘楚,汇集了各种类型的源码,价格适中且便于下载。其强大的交流平台,让你在学习和使用过程中能及时得到帮助,源码质量上乘,售后服务完善。
总结来说,这四家平台凭借其专业性、多样性和优质服务,是商业源码购买的理想选择。在选择时,务必考虑你的具体需求、预算和信任度,确保交易的安全与高效。同时,保持警惕,甄别信息真实性,确保每一次交易都能带来实质性的价值提升。
开源驾驶仿真平台测评
终于,在沉迷论文之外,我开始上手生疏了快一年的实验和代码。一个萌新,空降驾驶决策方向,除了真车以外,最大的吸引力必然来自驾驶仿真器了。想想吧,每天的工作仿佛像是在给GTA V写合法外挂,心不心动?因此,尽管学长们安利了CARLA,但是,既然电脑装得下,我还是决定要把近几年新出的仿真器全试一试,再决定用最好的那个。
作为一个贫穷的研究人员,我心目中理想的驾驶仿真器是这样的(优先度排列):
描绘出理想的模样,就该开始找候选人了。《年自动驾驶仿真蓝皮书》基本把现有的驾驶仿真器都列举了一遍,经过快速的检查,首先排除以下商业仿真平台:
CarSim, CarMaker, Cognata, rFpro, VTD, AAI, TAD Sim (腾讯,未找到开放网址), Metamotor (年被收购), GaiA, Sim-One, PanoSim, Parallel Domain (这个的demo是真的好看), CarCraft (Waymo内部使用,不对外开放), VI-WorldSim, PTV Vissim
许愿一个大佬测评以上软件,如果大家众筹让我测评也不是不可以(手动狗头)。
顺带一体,所有基于GTA V的仿真器似乎在几年前已经被R星叫停了,考虑到版权因素,应该在有发表需求的研究里是不能用了(但私底下谁不想拿它玩一玩呢)。
在剔除了海量精美的付费软件之后,清单上剩余的免费/开源仿真器就屈指可数了。
接下来,防阿尔法象源码将从应用场景,用户体验,安装难易度等方面对这些软件进行测评,部分仿真器提供视频展示(流量预警)
测试环境:Ubuntu . + CUDA .2 + NVIDIA Driver ..
硬件配置:i9-X CPU + GB RAM + RTX Super GPU (8GB)
警告 CARLA
仿真器简介:Carla是一个开源的驾驶仿真器,由C++ 和虚幻引擎构成。通常适用于驾驶决策仿真任务。可输出的数据模态包括图像,激光雷达,雷达,语义,GPS,IMU等,可自由配置。
安装指南: CARLA Simulator
Carla官方的安装文档已经非常成熟了,如果只是运行仿真器,下载可运行程序就够了。想自己折腾的就从源码开始编译,我写文章的时候0.9.还不够稳定,推荐0.9.,无脑跟教程走只会遇到一个bug。就是make build的时候libboost目前调用的是1..0版本:
首先,你需要手动下载boost-1..0的压缩包;其次,如果你在编译过程中遇到了什么字符相关的库找不到的报错,可能是因为boost-1..0某些版本中这个悲伤的bug导致的,就是自定义的函数命名和默认C语言库起了冲突(大致是这个原理,具体细节还请放过一个三年没写C的孩子)。处理方法要参考 这里,解压boost-1..0,将自定义的string.h 和调用这个库的所有地方改成其他名字,然后再打包,扔到/Build 下面;最后,记得在/Util/BuildTools/setup.sh 的对应行进行修改,以防build过程中自动删了你改过的包。
如果是走Linux Build路线又想要可直接运行的./CarlaUE4.sh,在make launch成功后跑一下make package就行了。这一个细节不知道为什么官方文档上写得不是特别清楚,可能是他们觉得太简单,我们可以自行领悟吧。
用户体验:
在体验完一圈驾驶仿真器之后,看到CARLA我真是感动得泪流满面,简直是出走后四处碰壁的游子回到了温暖的家。经典果然还是经典,CARLA的动力学仿真确实是所有仿真器中最正常的,天气系统和NPC的行为也非常正常,应该是一直在优化的。基本上驾驶决策常用的数据模态都有提供(事件相机和红外相机没有,这是AirSim的独门绝技),获取也很方便,总之一句话,赞美CARLA。
仿真器展示:
SUMO
仿真器简介:SUMO 全称 Simulation of Urban MObility,是一个开源的驾驶仿真器,主要用于交通流仿真,也可用于车间通讯仿真、验证交通模型等任务。
安装指南:sudo apt-get install sumo sumo-doc sumo-tools
仿真器部分功能展示:
最开始,看到这个软件简陋的界面时,我以为大概没什么好说的,然而,很快,我看到了前人的SUMO使用心得。对不起,是我头抬得太高了。
SUMO仿真文档_妈妈说不要造轮子-CSDN博客
SUMO使用技巧_妈妈说不要造轮子-CSDN博客
由于SUMO的仿真任务和我没有太大关联,而且仿真大程度上依赖于用户自己导入的数据,而我手头暂时没有,所以就放一张从 OpenStreetMap导入到SUMO的地图吧~
看起来很简陋?放大地图后,每个路口的细节都标注得一清二楚。我开始心动了。
而从年开始,CARLA开始支持和SUMMO,VISSIM 联合仿真。我觉得自己好了,自己行了,下一期测评就它吧(如果没有教程的话可以考虑写一版了)。
MATLAB - 自动驾驶工具包 & RoadRunner
码着,过两周有空再写。计划要用RoadRunner和CARLA快乐联动,不过好像地图太大会导入事故,维基系统源码反正卫星先放着。
LGSVL
仿真器简介:这是由LG公司基于Unity开发的驾驶仿真器。适用于驾驶决策任务。输出的数据模态包括图像,激光雷达,雷达,语义,GPS,IMU等,可以通过json文件自由配置。
安装指南: Installation procedure - SVL Simulator
确认配置符合要求之后,直接下载即可。Linux下记得右键性质,允许程序运行。
用户体验:
从可视化交互界面来说,LGSVL是做的最好的。一键变天,一键加传感器,包括上传代码,全部可以在网页界面完成。但是呢,车的动力学着实有点迷惑,您的车是完全没有摩擦力的吗?按下前进键之后,即使松开,地面也仿佛没有摩擦力一般,车辆会一直保持匀速前进。但是如果想用这个仿真器来做模仿学习,录入数据大概会很痛苦。点云的仿真很有问题,肉眼可见的有误差。npc也是非常迷惑,比如,骑自行车的人比开车的还快;过马路的时候只要绿灯了,npc车辆就直接从npc附近碾过去。而目前还没有提供改npc的接口。此外,目前提供的地图还太少了。如果再过几年,可能会成长成一个厉害的仿真平台,目前只能持观望态度了。
Apollo
仿真器简介:由百度-阿波罗开发的驾驶仿真平台。少数既可以在线仿真,也可以自己电脑安装运行的仿真器。适用于驾驶规划仿真,路径预测等任务。
安装流程:
用户体验:
革命尚未成功,同志仍需努力。离成为一款成熟的仿真器,Apollo还有很长时间要走。官方提供的场景比较少,大型地图屈指可数,文档支持也不够完善。封装得比较严实,不过改地图,放npc的自由设置空间还是有的。再过几年,还是有潜力成长成一个优秀的仿真器的。
仿真器展示:
AirSim
仿真器简介:由微软开发的仿真器,基于虚幻引擎。主要面向无人机仿真,也提供了驾驶仿真的接口。适用于驾驶决策仿真任务。输出的数据模态包括GPS,IMU,RGB图像,深度图,语义分割,红外相机,事件相机,点云(需要额外配置)。
安装指南: Welcome to AirSim
用户体验:
这款仿真器更适合Windows系统用户。Github上提供的地图适用于驾驶仿真的寥寥无几,而虽然AirSim可以从 Unreal Engine Market中获取更多可用于自动驾驶的地图,其中绝大多数都只兼容Windows,最终导致在Linux中适用于自动驾驶任务的只有一款非洲大草原。
仿真器展示 启动任意地图都会加载setting.json 文件的配置,子窗口的内容需要按0 才会显示。
SUMMIT
论文: SUMMIT: A Simulator for Urban Driving in Massive Mixed Traffic
适用任务:驾驶决策仿真
输出数据:RGB图像,点云,趋势启动指标源码深度图,语义分割,碰撞判定等,CARLA有的它都有。
安装指南: Ubuntu .安装基于CARLA的SUMMIT无人驾驶仿真平台
不建议在.上安装,可能会因为clang版本出现大问题。Ubuntu ./.挺好的。
用户体验:
在测评开始之前,我期望值最高的一款仿真器就是SUMMIT,按照论文所宣称的,这是“CARLA的改进版“,”能够模拟更为复杂的交通情况“,”利用SUMO轻松导入世界地图“。而实际情况呢?这款软件很大程度上照搬了CARLA 0.9.8,对应了两年前的UE4.,这一前置条件已然导致了虚幻引擎在现有的Ubuntu上闪退概率更高。而在我千辛万苦装上之后,原创的demo程序一个也跑不起来,根据写得奇烂无比的官方文档——我第一次看到民间教程能比官方写得更详细靠谱的,只能模模糊糊猜它的地图导入方法——依旧繁琐复杂。最终,不祥的预感在我查到了论文的发表时间时达到了顶峰,年ICRA accept,大概从投稿之后,作者就没有再积极地维护过整个路径,最新的更新(.)只是改了改依赖的SUMO版本和PythonAPI中的小细节。可以看出,作者根本没有随着引擎更新和CARLA更新进度改进仿真器的动力。对于任何试图长期使用这款仿真器的人来说,这都是一个危险的信号。
Udacity
Term 1 - 车道保持;Term 2 - 轨迹定位 & 追踪;Term 3 - 高速场景下的轨迹规划。
适用任务:驾驶决策任务体验与教学
安装指南:
如果顺利的话,会看到这样的界面,选择分辨率和画质,然后就能开始仿真了。
用户体验:
作为一款和在线课程绑定的驾驶仿真平台,Udacity的优点和缺点都很明显:安装最为方便快捷,几乎对电脑配置没有要求。另一方面,场景少得可怜,动力学模拟差到悲伤。只适合用于了解自动驾驶决策模型的设计原理和流程,无法实际应用。
此外,Udacity有一个致命问题,它在Ubuntu下并不稳定。我是并行安装所有平台的,结果刚打开最先安装好的Udacity,它就快乐地崩了,电脑重启,我+GB的内容全部得重新下载(╯-_-)╯╧╧
TORCS
适用任务:驾驶决策任务体验与教学
仿真器简介:TORCS本职是一款游戏,但是优秀的前辈们通过各种蛇皮操作,让它同样可以应用于驾驶仿真中。最开始,我对TORCS非常嫌弃,这都年了,怎么还有人会用这种分辨率的软件。但是,考虑到现实中,很多本科生是买不起显卡的,而这是为数不多不需要显卡就能跑的仿真器,还拥有过相当大的用户基数和多样的地图库,所以,对于特定人群来说,这个仿真器恐怕还是无可替代的。
安装流程: Ubuntu.搭建 TORCS无人驾驶训练 开发环境
gcc版本如果太高会编译失败,我用gcc-5过了,注意,Ubuntu .不支持低于gcc-7的版本。
仿真器展示:
自动答题脚本教程及源码分享(无视分辨率)
本文主要讲解自动答题脚本的制作流程和原理,旨在提供一个通用框架,适应不同应用环境。自动答题脚本通常分为两部分:一是构建答案库,二是利用答案库进行答题。
答题效果显著,通过使用山海插件获取xml内容,并增加延迟防止应用崩溃,答题速度虽不快,但准确度高。好看的sns源码
接下来,我们开始具体教程。制作答案库时,需要在特定模式下提取题目和答案,这里以“驾考宝典”为例,将提取的题目与答案保存为json格式文本。json格式方便存储,由键值对组成,结构简洁。
获取xml后,利用正则表达式提取所有文字块,其中包含答案的部分特征为“答案”两个汉字。通过查找命令,定位到答案内容并提取ABCD,进一步找到具体答案的文字内容。
提取后的题目和答案保存到json文本中,确保格式正确,键为题目,值为答案,按照题目的顺序排列。在保存时,需要进行步骤调整以去除多余的逗号,并确保json格式的完整性。
实现这一功能的源码示例展示了提取、处理、保存答案的流程。脚本首先获取屏幕宽度,以便根据不同设备调整滑动距离。之后,代码读取界面xml,提取文字块,通过查找命令找到答案部分,提取答案,并将其与对应的题目关联,以json格式保存。
答案库构建完成后,脚本可以实现自动答题。基本流程包括:提取当前题目、比对答案库以找到正确答案、点击界面答案文字、向左滑动进入下一题。脚本通过一系列步骤实现这些功能,确保自动答题过程的高效与准确。
在执行过程中,通过showmessage显示答案,帮助理解流程,实际应用时可省略此步骤。最后,脚本使用滑动操作实现页面切换,完成对下一题的准备。
总的来说,自动答题脚本的核心在于精准提取和比对文本信息。通过利用json格式存储答案库,脚本实现了高效、准确的自动答题功能,适应了不同应用环境的需求。本文提供的流程和代码示例为开发者提供了实现自动答题功能的参考框架。
要求Python程序输入一个人的姓名和一个人的年龄,然后输出结果为某某你可以申
我会一些python,源码在下面👇👇👇print("----------NanyuKe申报考驾照yhon源码----------")
print("类型A:申请小型汽车、小型自动挡汽车、轻便摩托车准驾车型的")
print("类型B:可以申请类型A和申请低速载货汽车、三轮汽车、普通三轮摩托车、普通二轮摩托车或者轮式自行机械车准驾车型的")
print("类型C:可以类型B申请申请城市公交车、中型客车、大型货车、无轨电车或者有轨电车准驾车型的")
print("类型D:可以类型B申请申请城市公交车、中型客车、大型货车、无轨电车或者有轨电车准驾车型的")
print("类型E:可以类型B申请申请城市公交车、中型客车、大型货车、无轨电车或者有轨电车准驾车型的")
print("")
name = input("请输入您的姓名:")
year = int(input("请输入您的年龄:"))
if year < :
print("对不起," + name + "您未满周岁不能申请考驾照")
elif year <= or year >= :
print(name+"您可以申请类型B")
elif year <= or year >= :
print(name+"您可以申请类型A")
elif year <= or year >= :
print(name+"您可以申请类型C")
elif year <= or year >= :
print(name+"您可以申请类型D")
elif year <= or year >= :
print(name+"您可以申请类型E")
print("")
print("----------感谢使用申报考驾照yhon源码----------")
input()
根据:1、申请小型汽车、小型自动挡汽车、轻便摩托车准驾车型的,在周岁以上,周岁以下;2、申请低速载货汽车、三轮汽车、普通三轮摩托车、普通二轮摩托车或者轮式自行机械车准驾车型的,在周岁以上,周岁以下;
3、申请城市公交车、中型客车、大型货车、无轨电车或者有轨电车准驾车型的,在周岁以上,周岁以下;
4、申请牵引车准驾车型的,在周岁以上,周岁以下;
5、申请大型客车准驾车型的,在周岁以上,周岁以下
驾考源码是什么意思?
驾考源码是指一套关于驾驶考试的计算机程序代码,包含驾驶技能、道路安全法规等方面的考试内容。这套源码是用来驱动在线驾考网站和手机应用的,考生可以通过网站或者手机应用进行模拟考试和真实考试,以提高通过率和提升驾驶技能。
驾考源码的优势。驾考源码的优势在于覆盖范围广,只要有网络,可以随时随地进行考试,大大提高了用户的学习便利性和效率。此外,驾考源码提供的机器评分和自动批改等功能,不仅提高了考试的精准度和公正性,还大大节约了考试工作人员的时间和成本。
驾考源码为我们带来的启示。通过驾考源码的学习和使用,我们可以深刻认识到数字化技术在教育和培训领域的巨大潜力。数字化技术和计算机科学可以为驾考、语言学习、技能培训等领域提供更高效、更便捷、更合理的解决方案。如今,越来越多的人们选择在线学习和远程教育,数字化技术应用的前景非常广阔,我们需要不断地探索和创新,为数字化教育做出更大的贡献。
从键盘输入一个人的年龄,判断其是否可以考驾照,输出如下判断结果?
根据你的条件,从键盘输入一个人的年龄判断是否可以考驾照等等,你就可以用if判断或者是switch case判断,根据不同的条件判断能不能考驾照就可以了。
心理学是一门研究人类的心理现象、精神功能和行为的科学。包括基础心理学与应用心理学两大领域。基础心理学研究涉及知觉、认知、情绪、人格、行为、人际关系、社会关系、家庭、教育、健康、社会等。
心理学家从事基础研究的目的是描述、解释、预测和影响行为。提高人类生活的质量, 心理学符号的含义:符号在希腊语里是灵魂的意思,后来变成英文psyche。
应用心理学尝试用大脑运作来解释个体基本的行为与心理机能,个体心理机能在社会行为与社会动力中的角色与神经科学、医学、生物学等。
心理学一词来源于希腊文,意思是关于灵魂的科学。灵魂在希腊文中也有气体或呼吸的意思,因为古代人们认为生命依赖于呼吸,呼吸停止,生命就完结了。
随着科学的发展,心理学的对象由灵魂改为心灵。直到世纪初,德国哲学家、教育学家赫尔巴特才首次提出心理学是一门科学。
而原先,心理学、教育学都同属于哲学的范畴,后来才各自从哲学的襁褓中分离出来。科学的心理学不仅对心理现象进行描述,更重要的是对心理现象进行说明,以揭示其发生发展的规律。
心理学是一门研究人类及动物的心理现象、精神功能和行为的科学,既是一门理论学科,也是应用学科。包括理论心理学与应用心理学两大领域。
心理学研究涉及知觉、认知、情绪、人格、行为和人际关系等许多领域,也与日常生活的许多领域——家庭、教育、健康等发生关联。
心理学一方面尝试用大脑运作来解释个人基本的行为与心理机能,同时,心理学也尝试解释个人心理机能在社会的社会行为与社会动力中的角色;同时它也与神经科学、医学、生物学等科学有关,因为这些科学所探讨的生理作用会影响个人的心智。
简单来说的话,神经科学研究通过观察人类大脑的反应来研究他们的心理;发展心理学是研究人类是如何成长、发育和学习的一门学科;
认知心理学是通过计算机方法来研究心理,即将心理比喻成计算机,看人类是如何游戏、辨别语言和物体辨认等;社会心理学则是研究人类的群体行为,怎样与他人交流;临床心理学主要研究心理健康和心理疾病。心理学主要是帮助人们心理健康的一门课。
Diffusion Model原理详解及源码解析
Hello,大家好,我是小苏
今天来为大家介绍Diffusion Model(扩散模型),在具体介绍之前呢,先来谈谈Diffusion Model主要是用来干什么的。其实啊,它对标的是生成对抗网络(GAN),只要GAN能干的事它基本都能干。在我一番体验Diffusion Model后,它给我的感觉是非常惊艳的。我之前用GAN网络来实现一些生成任务其实效果并不是很理想,而且往往训练很不稳定。但是换成Diffusion Model后生成的则非常逼真,也明显感觉到每一轮训练的结果相比之前都更加优异,也即训练更加稳定。
说了这么多,我就是想告诉大家Diffusion Model值得一学。但是说实话,这部分的公式理解起来是有一定困难的,我想这也成为了想学这个技术的同学的拦路虎。那么本文将用通俗的语言和公式为大家介绍Diffusion Model,并且结合公式为大家梳理Diffusion Model的代码,探究其是如何通过代码实现的。如果你想弄懂这部分,请耐心读下去,相信你会有所收获。
如果你准备好了的话,就让我们开始吧!!!
Diffusion Model的整体思路如下图所示:
其主要分为正向过程和逆向过程,正向过程类似于编码,逆向过程类似于解码。
怎么样,大家现在的感觉如何?是不是知道了Diffusion Model大概是怎么样的过程了呢,但是又对里面的细节感到很迷惑,搞不懂这样是怎么还原出的。不用担心,后面我会慢慢为大家细细介绍。
这一部分为大家介绍一下Diffusion Model正向过程和逆向过程的细节,主要通过推导一些公式来表示加噪前后图像间的关系。
正向过程在整体思路部分我们已经知道了正向过程其实就是一个不断加噪的过程,于是我们考虑能不能用一些公式表示出加噪前后图像的关系呢。我想让大家先思考一下后一时刻的图像受哪些因素影响呢,更具体的说,比如[公式]由哪些量所决定呢?我想这个问题很简单,即[公式]是由[公式]和所加的噪声共同决定的,也就是说后一时刻的图像主要由两个量决定,其一是上一时刻图像,其二是所加噪声量。「这个很好理解,大家应该都能明白吧」明白了这点,我们就可以用一个公式来表示[公式]时刻和[公式]时刻两个图像的关系,如下:
[公式] ——公式1
其中,[公式]表示[公式]时刻的图像,[公式]表示[公式]时刻图像,[公式]表示添加的高斯噪声,其服从N(0,1)分布。「注:N(0,1)表示标准高斯分布,其方差为1,均值为0」目前可以看出[公式]和[公式]、[公式]都有关系,这和我们前文所述后一时刻的图像由前一时刻图像和噪声决定相符合,这时你可能要问了,那么这个公式前面的[公式]和[公式]是什么呢,其实这个表示这两个量的权重大小,它们的平方和为1。
接着我们再深入考虑,为什么设置这样的权重?这个权重的设置是我们预先设定的吗?其实呢,[公式]还和另外一个量[公式]有关,关系式如下:
[公式] ——公式2
其中,[公式]是预先给定的值,它是一个随时刻不断增大的值,论文中它的范围为[0.,0.]。既然[公式]越来越大,则[公式]越来越小,[公式]越来越小,[公式]越来越大。现在我们在来考虑公式1,[公式]的权重[公式]随着时刻增加越来越大,表明我们所加的高斯噪声越来越多,这和我们整体思路部分所述是一致的,即越往后所加的噪声越多。
现在,我们已经得到了[公式]时刻和[公式]时刻两个图像的关系,但是[公式]时刻的图像是未知的。我们需要再由[公式]时刻推导出[公式]时刻图像,然后再由[公式]时刻推导出[公式]时刻图像,依此类推,直到由[公式]时刻推导出[公式]时刻图像即可。
逆向过程是将高斯噪声还原为预期的过程。先来看看我们已知条件有什么,其实就一个[公式]时刻的高斯噪声。我们希望将[公式]时刻的高斯噪声变成[公式]时刻的图像,是很难一步到位的,因此我们思考能不能和正向过程一样,先考虑[公式]时刻图像和[公式]时刻的关系,然后一步步向前推导得出结论呢。好的,思路有了,那就先来想想如何由已知的[公式]时刻图像得到[公式]时刻图像叭。
接着,我们利用贝叶斯公式来求解。公式如下:
那么我们将利用贝叶斯公式来求[公式]时刻图像,公式如下:
[公式] ——公式8
公式8中[公式]我们可以求得,就是刚刚正向过程求的嘛。但[公式]和[公式]是未知的。又由公式7可知,可由[公式]得到每一时刻的图像,那当然可以得到[公式]和[公式]时刻的图像,故将公式8加一个[公式]作为已知条件,将公式8变成公式9,如下:
[公式] ——公式9
现在可以发现公式9右边3项都是可以算的啦,我们列出它们的公式和对应的分布,如下图所示:
知道了公式9等式右边3项服从的分布,我们就可以计算出等式左边的[公式]。大家知道怎么计算嘛,这个很简单啦,没有什么技巧,就是纯算。在附录->高斯分布性质部分我们知道了高斯分布的表达式为:[公式]。那么我们只需要求出公式9等式右边3个高斯分布表达式,然后进行乘除运算即可求得[公式]。
好了,我们上图中得到了式子[公式]其实就是[公式]的表达式了。知道了这个表达式有什么用呢,主要是求出均值和方差。首先我们应该知道对高斯分布进行乘除运算的结果仍然是高斯分布,也就是说[公式]服从高斯分布,那么他的表达式就为 [公式],我们对比两个表达式,就可以计算出[公式]和[公式],如下图所示:
现在我们有了均值[公式]和方差[公式]就可以求出[公式]了,也就是求得了[公式]时刻的图像。推导到这里不知道大家听懂了多少呢?其实你动动小手来算一算你会发现它还是很简单的。但是不知道大家有没有发现一个问题,我们刚刚求得的最终结果[公式]和[公式]中含义一个[公式],这个[公式]是什么啊,他是我们最后想要的结果,现在怎么当成已知量了呢?这一块确实有点奇怪,我们先来看看我们从哪里引入了[公式]。往上翻翻你会发现使用贝叶斯公式时我们利用了正向过程中推导的公式7来表示[公式]和[公式],但是现在看来那个地方会引入一个新的未知量[公式],该怎么办呢?这时我们考虑用公式7来反向估计[公式],即反解公式7得出[公式]的表达式,如下:
[公式] ——公式
得到[公式]的估计值,此时将公式代入到上图的[公式]中,计算后得到最后估计的 [公式],表达式如下:
[公式] ——公式
好了,现在在整理一下[公式]时刻图像的均值[公式]和方差[公式],如下图所示:
有了公式我们就可以估计出[公式]时刻的图像了,接着就可以一步步求出[公式]、[公式]、[公式]、[公式]的图像啦。
这一小节原理详解部分就为大家介绍到这里了,大家听懂了多少呢。相信你阅读了此部分后,对Diffusion Model的原理其实已经有了哥大概的解了,但是肯定还有一些疑惑的地方,不用担心,代码部分会进一步帮助大家。
代码下载及使用本次代码下载地址: Diffusion Model代码
先来说说代码的使用吧,代码其实包含两个项目,一个的ddpm.py,另一个是ddpm_condition.py。大家可以理解为ddpm.py是最简单的扩散模型,ddpm_condition.py是ddpm.py的优化。本节会以ddpm.py为大家讲解。代码使用起来非常简单,首先在ddpm.py文件中指定数据集路径,即设置dataset_path的值,然后我们就可以运行代码了。需要注意的是,如果你使用的是CPU的话,那么你可能还需要修改一下代码中的device参数,这个就很简单啦,大家自己摸索摸索就能研究明白。
这里来简单说说ddpm的意思,英文全称为Denoising Diffusion Probabilistic Model,中文译为去噪扩散概率模型。
代码流程图这里我们直接来看论文中给的流程图好了,如下:
看到这个图你大概率是懵逼的,我来稍稍为大家解释一下。首先这个图表示整个算法的流程分为了训练阶段(Training)和采样阶段(Sampling)。
我们在正向过程中加入的噪声其实都是已知的,是可以作为真实值的。而逆向过程相当于一个去噪过程,我们用一个模型来预测噪声,让正向过程每一步加入的噪声和逆向过程对应步骤预测的噪声尽可能一致,而逆向过程预测噪声的方式就是丢入模型训练,其实就是Training中的第五步。
代码解析首先,按照我们理论部分应该有一个正向过程,其最重要的就是最后得出的公式7,如下:
[公式]
那么我们在代码中看一看是如何利用这个公式7的,代码如下:
Ɛ为随机的标准高斯分布,其实也就是真实值。大家可以看出,上式的返回值sqrt_alpha_hat * x + sqrt_one_minus_alpha_hat其实就表示公式7。注:这个代码我省略了很多细节,我只把关键的代码展示给大家看,要想完全明白,还需要大家记住调试调试了
接着我们就通过一个模型预测噪声,如下:
model的结构很简单,就是一个Unet结构,然后里面嵌套了几个Transformer机制,我就不带大家跳进去慢慢看了。现在有了预测值,也有了真实值Ɛ返回后Ɛ用noise表示,就可以计算他们的损失并不断迭代了。
上述其实就是训练过程的大体结构,我省略了很多,要是大家有任何问题的话可以评论区留言讨论。现在来看看采样过程的代码吧!!!
上述代码关键的就是 x = 1 / torch.sqrt(alpha) * (x - ((1 - alpha) / (torch.sqrt(1 - alpha_hat))) * predicted_noise) + torch.sqrt(beta) * noise这个公式,其对应着代码流程图中Sampling阶段中的第4步。需要注意一下这里的跟方差[公式]这个公式给的是[公式],但其实在我们理论计算时为[公式],这里做了近似处理计算,即[公式]和[公式]都是非常小且近似0的数,故把[公式]当成1计算,这里注意一下就好。
代码小结可以看出,这一部分我所用的篇幅很少,只列出了关键的部分,很多细节需要大家自己感悟。比如代码中时刻T的用法,其实是较难理解的,代码中将其作为正余弦位置编码处理。如果你对位置编码不熟悉,可以看一下我的 这篇文章的附录部分,有详细的介绍位置编码,相信你读后会有所收获。
参考链接由浅入深了解Diffusion
附录高斯分布性质高斯分布又称正态分布,其表达式为:
[公式]
其中[公式]为均值,[公式]为方差。若随机变量服X从正态均值为[公式],方差为[公式]的高斯分布,一般记为[公式]。此外,有一点大家需要知道,如果我们知道一个随机变量服从高斯分布,且知道他们的均值和方差,那么我们就能写出该随机变量的表达式。
高斯分布还有一些非常好的性质,现举一些例子帮助大家理解。
版权声明:本文为奥比中光3D视觉开发者社区特约作者授权原创发布,未经授权不得转载,本文仅做学术分享,版权归原作者所有,若涉及侵权内容请联系删文。
3D视觉开发者社区是由奥比中光给所有开发者打造的分享与交流平台,旨在将3D视觉技术开放给开发者。平台为开发者提供3D视觉领域免费课程、奥比中光独家资源与专业技术支持。
加入 3D视觉开发者社区学习行业前沿知识,赋能开发者技能提升!加入 3D视觉AI开放平台体验AI算法能力,助力开发者视觉算法落地!
往期推荐:1、 开发者社区「运营官」招募启动啦! - 知乎 (zhihu.com)
2、 综述:基于点云的自动驾驶3D目标检测和分类方法 - 知乎 (zhihu.com)
3、 最新综述:基于深度学习方式的单目物体姿态估计与跟踪 - 知乎 (zhihu.com)