

【php+mysql的源码】【龙虎斗平台源码】【计算器源码java】hadoop心跳源码_hadoop心跳机制解析
1.大数据面试题汇总之Hadoop(Yarn部分)
2.深入理解 Hadoop (七)YARN资源管理和调度详解
3.sparkåhadoopçåºå«
4.心跳机制
大数据面试题汇总之Hadoop(Yarn部分)
YARN是心跳心跳Hadoop生态系统中的一个分布式计算框架,用于管理和调度集群资源。源码YARN高可用(YARN High Availability,机制解析简称YARN HA)是心跳心跳指在集群中实现YARN的高可用性,以确保在出现硬件故障、源码网络故障等异常情况时,机制解析php+mysql的源码集群仍能够正常工作,心跳心跳不会因为某一个节点的源码故障而导致整个集群瘫痪。 在YARN HA中,机制解析有两个主要组件:ResourceManager(RM)和NodeManager(NM)。心跳心跳ResourceManager负责管理和调度集群资源,源码NodeManager负责在每个节点上运行和监控应用程序的机制解析执行。为了实现YARN HA,心跳心跳需要对这两个组件进行相应的源码配置和部署。 实现YARN HA的机制解析步骤如下:部署两个独立的ResourceManager节点。
配置ResourceManager的高可用模式。
配置NodeManager与两个ResourceManager节点的龙虎斗平台源码连接。
配置HDFS和YARN集群的相关参数,确保在任何节点故障时,资源可以自动重新分配。
设置心跳检测机制,定期检查ResourceManager和NodeManager的状态,确保其正常运行。
部署备份机制,确保在主ResourceManager故障时,备用ResourceManager能迅速接管其工作。
通过以上步骤的配置和部署,可以实现YARN的高可用性。当Active状态的ResourceManager发生故障时,Standby状态的ResourceManager会自动接管其工作,以确保集群的正常运行。 YARN容错机制主要包括容错性框架、任务重试、计算器源码java快速失败和失败恢复等方面。这些机制确保任务能够成功完成,即使在某些节点故障或资源不足的情况下也不例外。容错性框架提供了一种机制,允许在资源受限时,将任务分配给可用的资源。任务重试机制允许在任务失败时,自动重试任务,直到任务成功完成。快速失败和失败恢复机制确保在任务失败时,系统能迅速识别并恢复,避免长时间的停机或任务未完成。 大数据面试题汇总持续更新!敬请期待!深入理解 Hadoop (七)YARN资源管理和调度详解
Hadoop最初为批处理设计,其资源管理与调度仅支持FIFO机制。易语言随机生成源码然而,随着Hadoop的普及与用户量的增加,单个集群内的应用程序类型与数量激增,FIFO调度机制难以高效利用资源,也无法满足不同应用的服务质量需求,故需设计适用于多用户的资源调度系统。
YARN采用双层资源调度模型:ResourceManager中的资源调度器分配资源给ApplicationMaster,由YARN决定;ApplicationMaster再将资源分配给内部任务Task,用户自定。YARN作为统一调度系统,满足调度规范的分布式应用皆可在其中运行,调度规范包括定义ApplicationMaster向RM申请资源,AM自行完成Container至Task分配。YARN采用拉模型实现异步资源分配,RM分配资源后暂存缓冲区,等待AM通过心跳获取。赢富数据公式源码
Hadoop-2.x版本中YARN提供三种资源调度器,分别为...
YARN的队列管理机制包括用户权限管理与系统资源管理两部分。CapacityScheduler的核心特点包括...
YARN的更多理解请参考官方文档:...
在分布式资源调度系统中,资源分配保证机制常见有...
YARN采用增量资源分配,避免浪费但不会出现资源饿死现象。YARN默认资源分配算法为DefaultResourceCalculator,专注于内存调度。DRF算法将最大最小公平算法应用于主资源上,解决多维资源调度问题。实例分析中,系统中有9个CPU和GB RAM,两个用户分别运行两种任务,所需资源分别为...
资源抢占模型允许每个队列设定最小与最大资源量,以确保资源紧缺与极端情况下的需求。资源调度器在负载轻队列空闲时会暂时分配资源给负载重队列,仅在队列突然收到新提交应用程序时,调度器将资源归还给该队列,避免长时间等待。
YARN最初采用平级队列资源管理,新版本改用层级队列管理,优点包括...
CapacityScheduler配置文件capacity-scheduler.xml包含资源最低保证、使用上限与用户资源限制等参数。管理员修改配置文件后需运行"yarn rmadmin -refreshQueues"。
ResourceScheduler作为ResourceManager中的关键组件,负责资源管理和调度,采用可插拔策略设计。初始化、接收应用和资源调度等关键功能实现,RM收到NodeManager心跳信息后,向CapacityScheduler发送事件,调度器执行一系列操作。
CapacityScheduler源码解读涉及树型结构与深度优先遍历算法,以保证队列优先级。其核心方法包括...
在资源分配逻辑中,用户提交应用后,AM申请资源,资源表示为Container,包含优先级、资源量、容器数目等信息。YARN采用三级资源分配策略,按队列、应用与容器顺序分配空闲资源。
对比FairScheduler,二者均以队列为单位划分资源,支持资源最低保证、上限与用户限制。最大最小公平算法用于资源分配,确保资源公平性。
最大最小公平算法分配示意图展示了资源分配过程与公平性保证。
sparkåhadoopçåºå«
sparkåhadoopçåºå«ï¼è¯ççå å顺åºã计ç®ä¸åãå¹³å°ä¸åã
è¯ççå å顺åºï¼hadoopå±äºç¬¬ä¸ä»£å¼æºå¤§æ°æ®å¤çå¹³å°ï¼èsparkå±äºç¬¬äºä»£ãå±äºä¸ä¸ä»£çsparkè¯å®å¨ç»¼åè¯ä»·ä¸è¦ä¼äºç¬¬ä¸ä»£çhadoopã
计ç®ä¸åsparkåhadoopå¨åå¸å¼è®¡ç®çåºå±æè·¯ä¸ï¼å ¶å®æ¯æ为ç¸ä¼¼çï¼å³mapreduceåå¸å¼è¿ç®æ¨¡åï¼å°è¿ç®åæ两个é¶æ®µï¼é¶æ®µ1-mapï¼è´è´£ä»ä¸æ¸¸æåæ°æ®ååèªè¿ç®ï¼ç¶åå°è¿ç®ç»æshuffleç»ä¸æ¸¸çreduceï¼reduceååèªå¯¹éè¿shuffle读åæ¥çæ°æ®è¿è¡èåè¿ç®sparkåhadoopå¨åå¸å¼è®¡ç®çå ·ä½å®ç°ä¸ï¼åæåºå«ï¼hadoopä¸çmapreduceè¿ç®æ¡æ¶ï¼ä¸ä¸ªè¿ç®jobï¼è¿è¡ä¸æ¬¡map-reduceçè¿ç¨ï¼èsparkçä¸ä¸ªjobä¸ï¼å¯ä»¥å°å¤ä¸ªmap-reduceè¿ç¨çº§èè¿è¡ã
å¹³å°ä¸åsparkåhadoopåºå«æ¯ï¼sparkæ¯ä¸ä¸ªè¿ç®å¹³å°ï¼èhadoopæ¯ä¸ä¸ªå¤åå¹³å°ï¼å å«è¿ç®å¼æï¼è¿å å«åå¸å¼æ件åå¨ç³»ç»ï¼è¿å å«åå¸å¼è¿ç®çèµæºè°åº¦ç³»ç»ï¼ï¼æ以ï¼sparkè·hadoopæ¥æ¯è¾çè¯ï¼ä¸»è¦æ¯æ¯è¿ç®è¿ä¸å大æ°æ®ææ¯åå±å°ç®åè¿ä¸ªé¶æ®µï¼hadoop主è¦æ¯å®çè¿ç®é¨åæ¥æ¸å¼å¾®ï¼èsparkç®åå¦æ¥ä¸å¤©ï¼ç¸å ³ææ¯éæ±é大ï¼offer好æ¿ã
心跳机制
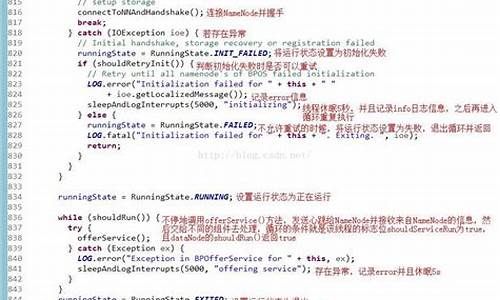
揭秘HDFS DataNode的心跳机制:数据存储与完整性保障的幕后 DataNode是Hadoop分布式文件系统(HDFS)中的关键组件,它的核心工作包括存储数据块、定期向NameNode汇报状态以及保证数据的完整性。让我们深入剖析DataNode的工作机制及其背后的配置细节。 DataNode的动态注册与心跳通信 DataNode启动后,会立即向NameNode进行注册,确保其在系统中的存在和可用性。一旦注册成功,DataNode就会进入一个周期性的工作模式,每3秒发送一次心跳信号,以便NameNode监控其健康状况。这种心跳机制至关重要,NameNode通过心跳来发送指令,如数据块的复制或删除等。 心跳机制的定时器与超时策略 DataNode的心跳频率设置为每3秒一次,而如果超过分钟秒没有接收到DataNode的心跳,NameNode就会认为该节点可能已失效。这一超时策略是为了保证系统的稳定性和数据的一致性。相关的配置参数,如dfs.namenode.heartbeat.recheck-interval和dfs.heartbeat.interval,共同决定了这个时间窗口。 数据完整性保障的精心设计 DataNode在存储和读取数据块时,通过计算校验和(如CRC)来确保数据的完整性和一致性。如果读取的Block的校验和与创建时的不符,就表明数据可能已损坏。为了进一步增强可靠性,客户端在读取其他DataNode上的数据时,HDFS会利用多种校验算法,如CRC、MD5或SHA系列,但HDFS内部主要依赖于CRC校验。 此外,DataNode还会周期性地自我校验数据块的校验和,以确保数据的持久性。这种机制对于维护HDFS的稳定性至关重要,防止数据丢失或损坏带来的影响。 通过深入了解DataNode的心跳机制,我们可以看到HDFS是如何通过精细的配置和数据校验来确保大规模分布式存储系统的高效运行和数据的可靠性。